神经网络模型压缩——剪枝
一、Adaptive Neural Networks for Efficient Inference 2017
(注意比较这个和下一个: 一二)
https://www.baidu.com/link?url=G_BjuL1bDrwmt0XxMTS-3g6VB_HGfIBJTCVmuWUatmJ4dyXNzxhluOH7h_NI6K-T&wd=&eqid=9da5384e00025b29000000025b0fb611
以缩短运行路径为目的,两种方式来缩减运行时间:一是使用在卷积层早期就能判别是否该导出的策略early-exit stratage to bypass some layers;一种是使用类似的方法选择构建的网络结构
具体的实施是正则化运行时间(使用某种方式度量)以及降低总体预测的loss
二、NISP: Pruning Networksusing Neuron Importance Score Propagation 2017
https://www.baidu.com/link?url=QeG-iSKujQ85hc6mDUyyDU3SDhB_fXm9EbgghvficYB-Dm9gmjwLAb2j37tre3rc&wd=&eqid=fc43a3fc0005fc68000000025b10a391
使用后向传播的方式来确定各个channel的重要性,然后排序选择重要的部分
【这篇论文对FC层压缩的综述很有意思,可看看】
特征排序使用Inf-FS方法【G.Roffo, S. Melzi, and M. Cristani. Infinite feature selection. In 2015 (ICCV),并有GitHub开源代码】

目标函数就是让留下的部分尽可能的小,同时的表达能力还在
三、meProp: Sparsified BackPropagation for Accelerated Deep Learning with Reduced Overfitting
http://arxiv.org/abs/1706.06197
这篇文章是发现了再反向传播的时候,只有很少的一部分参数是需要更新的,约4%。所以就是一种更新稀疏矩阵的方式,可以加快收敛。
为做到这一点,需要找到需要更新的参数的子集,使用top-k重要的参数。The proposed meProp uses approximate gradients by keeping only top-kelements based on the magnitude values.
后向传播的时候,只保留前k个,其他的梯度设置为0. For meProp, back propagation computes an approximate gradient bykeeping top-k values of the backward flowed gradient and masking the remainingvalues to 0
这篇文章也列出了相关的研究,不过有一个比较有意思的是:Thesampled-output-loss methods (Jean et al., 2015 On using very large target vocabularyfor neural machine translation) are limited to the softmax layer (output layer)and are only based on random sampling对soft max处理的方法
四、Data-Driven Sparse Structure Selection for Deep Neural Networks 2017
(注意比较这个和下一个:四五)
https://www.baidu.com/link?url=fRF_MTPGpjVy-Eyd-MGWtO2gP_LUrXiuauuV2Sm7jwX3fyaxMt8ez_yaE0qfzm3X&wd=&eqid=9ca674fc0001fda8000000025b0faef6
1. 在一些结构块/神经节点等加上一个参数,控制该结构输出
2. 对这些结构进行正则化处理
是整体的调整单元结构,是结构化处理的方式,同时又能对结构整体的处理,让最终权重看起来更“干净”。
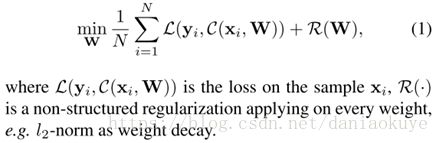

五、Learning Efficient Convolutional Networks through Network Slimming 2017
https://www.baidu.com/link?url=iDduWCYJ4EFSJLQJX0DuumnBNwqYGYkYqV6LdlwyO88fkO6kNkan2x1iGEnRYKr_&wd=&eqid=aabe025f0004ba2d000000025b0fbe12
是对CNN卷积核的每一个channel进行处理:加上一个scale量化因子,该因子在训练时被正则化处理。控制每一个channel,也就是相当于控制了相应的立方体的卷积核
实施的时候也很取巧,直接对BN层的缩放因子进行正则化处理(L1)

六、squeezenet: alexnet-level accuracy with 50x fewer parameters and <0.5mb model size 2017
https://www.baidu.com/link?url=Lm-JzAB7U42hGpqRAnQjmuciE8--Hc7XSbW6wy86EjNODbVdJEZb0uKkn6rfAhWT&wd=&eqid=efadc8a8000792f5000000025b10e0d9
fire module是一个区块设计,用来组成squeezenet
其思路空间主要由三种方式:1*1的卷积替代3*3的卷积;对3*3的卷积的输入层降维;空间尺寸缓降,大的激活特征图有利于保持精度
Fire module结构是:squeeze卷积(1*1);expand卷积(1*1和3*3的组合);三中模式的维度是可学习的,分别为s1x1, e1x1, and e3x3
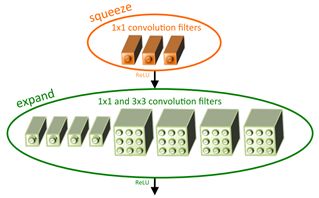
expand实际操作是1*1和3*3两分支在channel上的concatenate,维度上的组合

注:这篇文章也没有fully connection layer,由global pooling layer代替,作者说是参考与NIN
最后,在此基础上,作者又:添加了复杂的skip connection结构(又为bypass结构);使用deep compression(S. Han, H. Mao, and W. Dally. Deep compression: Compressing DNNswith pruning, trained quantization and huffman coding. arxiv:1510.00149v3,2015a.)进一步的压缩。
作者这样评价:these results demonstrate that DeepCompression (Han et al., 2015a) not only works well on CNN architectures withmany parameters (e.g. AlexNet and VGG), but it is also able to compress thealready compact, fully convolutional SqueezeNet architecture.
七、SBNet: Sparse Blocks Network for Fast Inference
http://arxiv.org/abs/1801.02108
稀疏化矩阵,在作者认为often gains in terms oftheoretical FLOPs without realizing a practical speed- up 只有理论效果,难有实际效果。
稀疏矩阵通常的做法:In these examples, spatialsparsity can be represented as binary computation masks. Mask通常有一个cheap net小网络或者主干网络中的部分形成的。
本文呢,也没超脱这个窠臼,不过是使用mask做attention机制,用来指导哪儿去做卷积。
本文还想在底层一些的卷积运算的方式上提升速度,参考img2col和FFT的方式。(注意,这篇文章还重点解释了另外一种方式,使用查找表的方法来提高压缩率,文中论文[6])
具体是先提取激活的位置作为mask,成为reduce mask;然后作者是将对应部分复制出来,操作后再粘贴回去
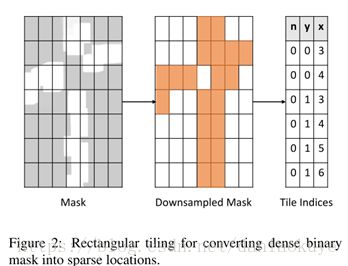
实际上,这就是稀疏矩阵的标准做法。如mxnet 的RowSparseNDArray的做法http://mxnet.incubator.apache.org/tutorials/sparse/row_sparse.html。
不同是,稀疏矩阵处理后其输出的大小是不统一的,这篇文章就是将其做成统一大小,方法是gather,如下图。以及相反的操作,scatter。
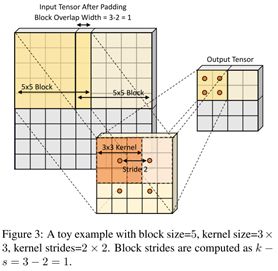
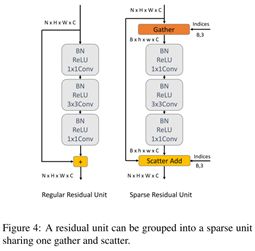
是某种形式的缩放,类似与pooling的方法
此外,需要补充的是[J. Uhrig, N. Schneider, L.Schneider, U. Franke, T. Brox, and A. Geiger. Sparsity invariant cnns. CoRR,abs/1708.06500, 2017.] showed that batch-normalizing across non-sparse elements contributes to better model accuracy since it ignores non-valid data that may introduce noise to the statistics.就是说BN忽略包括零值在内的无效值,可以提高精度。——可用于工程分析
八、Attention-Based Guided Structured Sparsity of Deep Neural Networks
https://arxiv.org/pdf/1802.09902.pdf
目前稀疏化的方法有主流的:group lasso;控制网络结构收缩constrain the structure scale;对网络结构正则化处理regularizingmultiple DNN structures。
这篇是使用group sparsity减少有效参数;设置额外的loss函数强迫部分参数不会被稀疏化

结果表明GSS的效果比SSL还要好!
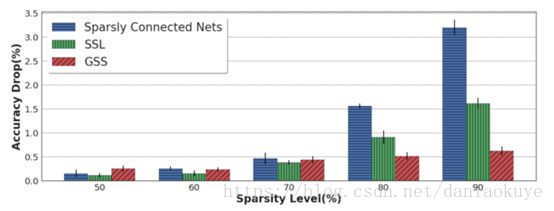
九、ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression
https://arxiv.org/abs/1707.06342ThiNet (stands for “Thin Net”)
filter level pruning;we need to prune filters based on statistics in- formation computedfrom its next layer, not the current layer
不过这种方法再NISP论文中,指出Thinet是一种贪婪的方法,没有太多整体的考虑。
现在主流的稀疏化方法:1)han song提出的方法,低于某一阈值的归零,但是这种非结构化的稀疏矩阵现有的库很难处理,需要专门设置。2)group-wise稀疏化,使用group-sparsityregularization【V. Lebedev andV. Lempitsky. Fastconvnets using group-wise brain damage. In CVPR, pages 2554–2564, 2016】。3)还有module等单位(filter,channel, filter shape and depth structures)的稀疏化,StructuredSparsity Learning (SSL) method。4)神经元的重要性度量:a. 使用权值的模【H. Li, A. Kadav, I. Durdanovic, H.Samet, and H. P. Graf. Pruning filters for efficient ConvNets. In ICLR, pages1–13, 2017.】;b. 度量relu之后的结果的稀疏度【H. Hu, R. Peng, Y.W. Tai, and C. K. Tang. Network trimming: Adata-driven neuron pruning approach towards efficient deep architectures. InarXiv preprint arXiv:1607.03250, pages 1–9, 2016】;c. 近似的求算对loss的影响力度,如使用Talayor expansion泰勒展开【P. Molchanov, S. Tyree, T. Karras, T. Aila, and J. Kautz. Pruningconvolutional neural networks for resource efficient transfer learning. In ICLR,pages 1–17, 2017.】
所以对filter整体进行处理,可以保证结构化稀疏。evaluate the importance of each neuron, remove those unimportantones, and fine-tune the whole network
对应的方法是一种近似解,比较依赖finetune提升精度。此外有一个近似的精度比较:
留意random的曲线
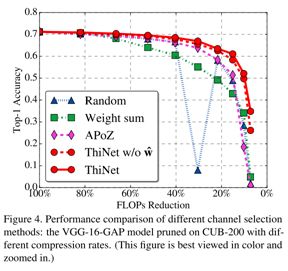
十、Differentiable plasticity: training plastic neural networks with back propagation
http://arxiv.org/abs/1804.02464
这是塑性网络结构,是一个研究的小领域,为了lifelong learning,具体实现的方式是synaptic plasticity – the strengthening and weakening of connectionsbetween neurons as a result of neural activity.生物学理论基础是Hebb’srule: if a neuron repeatedly takes part in making another neuron fire, theconnection between them is strengthened
顺便插一句,作者说这种方式的记忆能力优于LSTM。outperform advanced non-plastic recurrent networks (LSTMs) by ordersof magnitude in complex pattern memorization.实际上是具体的网络结构,不是用于压缩网络的策略或者结构。分析他主要是了解目前后向传播应用的一个维度。