AI(010) - Show and Tell: 一个神经图像说明文字生成器
Show and Tell: 一个神经图像说明文字生成器
原文标题:Show and Tell: A Neural Image Caption Generator
原文地址:https://github.com/tensorflow/models/blob/master/research/im2txt/README.md
Show and Tell: 一个神经图像说明文字生成器
本文是根据论文中关于图像转文本(image-to-text)的 TensorFlow 实现:
“Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning
Challenge.”
Oriol Vinyals, Alexander Toshev, Samy Bengio, Dumitru Erhan.
IEEE transactions on pattern analysis and machine intelligence (2016).
全文内容: http://arxiv.org/abs/1609.06647
联系方式
Author: Chris Shallue
Pull requests and issues: @cshallue
内容
- 模型概述
- 引言
- 结构
- 入门
- 关于硬件与训练时间的说明
- 安装所需的软件包
- 准备训练数据
- 下载 Inception v3 检查点
- 训练一个模型
- 初始化训练
- Fine Tune Inception v3 模型
- 生成说明文字
模型概述
引言
Show and Tell 模型是一个深度神经网络,它用于学习如何描述图像中的内容。例如:

结构
Show and Tell 模型是 编码器-解码器(encoder-decoder) 神经网络的一个案例。它首先将图像“编码”成一个固定长度(fixed-length)的向量表示,然后将此向量表示“解码”成自然语言描述。
图像编码器(encoder)是一个深度卷积神经网络。这个类型的网络被广泛应用于图像任务,同时也是目前最先进的(state-of-the-art)目标识别与目标检测技术。我们选择的网络是在 ILSVRC-2012-CLS 图像分类数据集上预先训练的 Inception v3 图像识别模型。
解码器(decoder)是一个长短期记忆(LSTM)网络。这个类型的网络常用于序列建模任务,如语言建模和机器翻译。在 Show and Tell 模型中,LSTM网络被训练成基于图像编码(image encoding)的语言模型。
说明文字中的单词用嵌入模型(embedding model)表示。词汇中的每个单词都与训练过程中学到的固定长度向量表示相关联。
下面的示意图说明了模型结构。
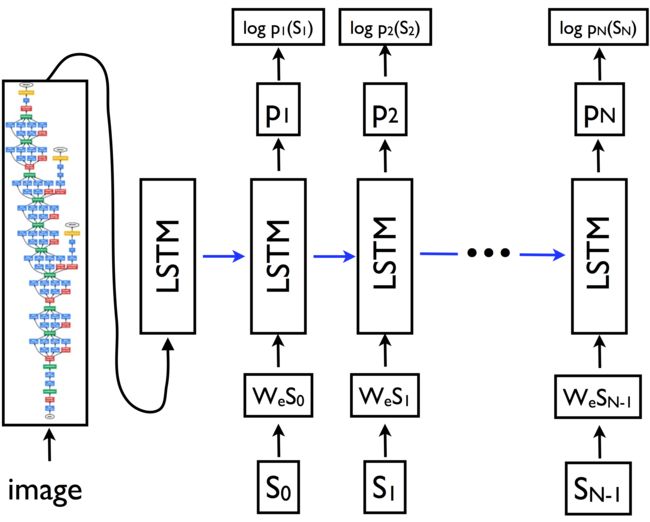
在示意图中, {*s*0, s1, …, sN-1} 为说明文字中的单词, {*w*es0, wes1, …, wesN-1} 为它们对应的词嵌入向量。LSTM的输出 {*p*1, p2, …, pN} 是由模型生成的概率分布,被用于句子中的下一个单词。项 {log p1 (s1), log p2(s2), …, log pN(sN)} 是每一步中正确单词的对数似然值(log-likelihoods);这些值的负数和是模型的最小化目标(minimization objective)。
在训练的第一阶段, Inception v3 模型参数保持固定:它只有一个静态图像编码器功能。在 Inception v3 模型的顶部添加一个可训练的层,它用于将图像嵌入到词嵌入(word embedding)的向量空间(vector space)中。该模型是针对词嵌入的参数, Inception v3 最顶层的参数与LSTM的参数进行训练的。在训练的第二阶段,所有参数 - 包含 Inception v3 的参数 - 共同地对图像编码器和LSTM进行 fine-tune 训练。
给定一个训练过的模型和一个图像,我们使用 定向搜索(beam search) 来生成它的说明文字。说明文字是逐字(word-by-word)生成的,在每个步骤 t 我们使用已经生成的长度为 t - 1 的语句集合来生成一个新的长度为 t 的语句集合。在每一步,我们只保留 k 个候选项,其中超参数 k 被称为 束径(beam size) 。我们发现表现最好的是 k = 3 。
入门
关于硬件与训练时间的说明
训练 Show and Tell 模型所需要的时间取决于你的特定硬件和计算能力。在本指南中,我们假设你将使用GPU在一台单独的机器上来运行训练。根据我们的经验,在 NVIDIA Tesla K20m GPU 上进行初始化训练需要 1-2 周。训练的第二阶段可能需要额外的几个星期才能获得最佳性能(不过你可以提前停止这个阶段,这样依然能得到合理的结果)。
为了提高训练速度,可以通过机器集群的 GPUs 实现分布式的训练,但那并不包含在本指南中。
虽然也可以在单独的 CPU 上运行本代码,但请注意,这可能会慢大约10倍。
安装所需的软件包
首先确保你已经安装了下列所需的软件包:
- Bazel (instructions)
- TensorFlow 1.0 或更高版本 (instructions)
- NumPy (instructions)
- Natural Language Toolkit (NLTK):
- 首先安装 NLTK (instructions)
- 然后安装 NLTK 数据包 “punkt” (instructions)
- Unzip
准备训练数据
要训练模型,你需要提供 TFRecord 格式的训练数据。TFRecord 格式由一组包含序列化 tf.SequenceExample 协议缓冲区的分片文件组成。每个 tf.SequenceExample proto 都包含了一个图像(JPEG 格式),一段说明文字和元数据(metadata) ,如图像的 id 。
每段说明文字是一个单词列表。在预处理中,在词汇表中的每个单词都分配一个整形数值(integer-valued) id ,并赋值给一个新创建的字典(dictionary)。每段说明文字都被编码成一个整形单词 id 的列表,并存储在 tf.SequenceExample proto 中。
我们提供了一个脚本用于下载和预处理 MSCOCO 的图像说明文字数据集来转换成此格式。下载与预处理数据可能会需要几小时,这取决于你的网络与计算机速度。请耐心等待。
在运行脚本之前,确保你的硬盘有至少 150GB 的可用空间用于存储下载和预处理的数据。
# 保存 MSCOCO 数据的路径。
MSCOCO_DIR="${HOME}/im2txt/data/mscoco"
# 新建预处理脚本。
cd research/im2txt
bazel build //im2txt:download_and_preprocess_mscoco
# 运行预处理脚本。
bazel-bin/im2txt/download_and_preprocess_mscoco "${MSCOCO_DIR}"最后一行的输出应该为:
2016-09-01 16:47:47.296630: Finished processing all 20267 image-caption pairs in data set 'test'.当脚本运行结束时,你应该能在 DATA_DIR 中找到256个训练文件,4个验证文件与8个测试文件。这些文件将分别匹配为 train-?????-of-00256, val-?????-of-00004 和 test-?????-of-00008 。
下载 Inception v3 检查点
Show and Tell 模型需要一个预训练的 Inception v3 检查点文件,它用于初始化图像编码器子模型的参数。
这个检查点文件可以获取自 TensorFlow-Slim 图像分类库 ,它提供了一套预训练图像分类模型。你可以阅读更多有关分类库里提供的模型。
运行下面的命令来下载 Inception v3 的检查点。
# 保存 Inception v3 检查点文件的路径.
INCEPTION_DIR="${HOME}/im2txt/data"
mkdir -p ${INCEPTION_DIR}
wget "http://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz"
tar -xvf "inception_v3_2016_08_28.tar.gz" -C ${INCEPTION_DIR}
rm "inception_v3_2016_08_28.tar.gz"请注意, Inception v3 检查点仅仅用于初始化 Show and Tell 模型的参数。一旦 Show and Tell 模型开始训练,它将为自己保存包含所有参数的检查点文件(包含从 Inception v3 复制的参数)。如果停止并重新开始训练,将从最新的 Show and Tell 检查点恢复参数值,并忽略 Inception v3 检查点。换句话说, Inception v3 检查点仅仅用于训练 Show and Tell 模型的第0个全局步骤(初始化)。
训练一个模型
初始化训练
运行训练脚本。
# 包含预处理的 MSCOCO 数据的目录。
MSCOCO_DIR="${HOME}/im2txt/data/mscoco"
# Inception v3 检查点文件。
INCEPTION_CHECKPOINT="${HOME}/im2txt/data/inception_v3.ckpt"
# 保存模型的目录。
MODEL_DIR="${HOME}/im2txt/model"
# 新建模型。
cd research/im2txt
bazel build -c opt //im2txt/...
# 运行训练脚本。
bazel-bin/im2txt/train \
--input_file_pattern="${MSCOCO_DIR}/train-?????-of-00256" \
--inception_checkpoint_file="${INCEPTION_CHECKPOINT}" \
--train_dir="${MODEL_DIR}/train" \
--train_inception=false \
--number_of_steps=1000000在单独的进程中运行评估脚本(evaluation script)。这将将评估指标记录到 TensorBoard 中,从而可以实时的监控训练过程。
请注意,如果训练脚本与评估脚本使用同一个GPU,可能会发生内存不足(out of memory)。你可以运行命令 export CUDA_VISIBLE_DEVICES="" 强制让评估脚本运行在CPU上。如果在CPU上评估运行的过慢,你可以减少 --num_eval_examples 的值。
MSCOCO_DIR="${HOME}/im2txt/data/mscoco"
MODEL_DIR="${HOME}/im2txt/model"
# 忽略 GPU (仅在GPU受内存限制时才需要使用,例如通过运行训练脚本)。
export CUDA_VISIBLE_DEVICES=""
# 运行评估脚本。 这将运行一个循环,定期加载最新的检查点文件,
# 并计算评估指标。
bazel-bin/im2txt/evaluate \
--input_file_pattern="${MSCOCO_DIR}/val-?????-of-00004" \
--checkpoint_dir="${MODEL_DIR}/train" \
--eval_dir="${MODEL_DIR}/eval"在单独的进程中运行 TensorBoard 服务器,用于实时的监控训练过程与评估指标。
MODEL_DIR="${HOME}/im2txt/model"
# 运行一个 TensorBoard 服务器。
tensorboard --logdir="${MODEL_DIR}"Fine Tune Inception v3 模型
你的模型经过第一阶段的训练,已经可以产生合理的说明文字了。试试看!(见 生成说明文字)。
你可以通过运行训练的第二阶段来共同地 fine-tune Inception v3 图像子模型与LSTM的参数,进一步提供模型的性能,
# 使用 --train_inception=true 重新运行训练脚本。
bazel-bin/im2txt/train \
--input_file_pattern="${MSCOCO_DIR}/train-?????-of-00256" \
--train_dir="${MODEL_DIR}/train" \
--train_inception=true \
--number_of_steps=3000000 # 增加 2M (假设初始化训练为 1M ).请注意,现在训练的运行速度要慢的多,并且模型会在很长时间里持续进行微小的提升。我们发现在过拟合之前,可以缓慢的从200万步朝向250万步增加。在单独的GPU上,这可能会花费数周时间。如果你不关心绝对最佳性能,通过停止脚本或设置更低的 --number_of_steps 可以更快的停止脚本。你的模型仍然可以很好的工作。
生成说明文字
你训练的 Show and Tell 模型可以对任意 JPEG 图像生成说明文字!以下命令行可以为测试集中的一张图像生成说明文字。
# 检查点文件路径或包含了检查点文件的目录。
# 要使用传递一个目录,必须满足以下条件:
# 传递的目录中存在一个名为 'checkpoint' 的文件;
# 此 'checkpoint' 文件的内容为当前目录中检查点文件的列表。
# 不满足条件下,你只能明确地指定检查点的文件路径。
CHECKPOINT_PATH="${HOME}/im2txt/model/train"
# 由预处理脚本生成的词汇表文件。
VOCAB_FILE="${HOME}/im2txt/data/mscoco/word_counts.txt"
# 用于生成说明文字的 JPEG 图像.
IMAGE_FILE="${HOME}/im2txt/data/mscoco/raw-data/val2014/COCO_val2014_000000224477.jpg"
# 新建推理(inference)二元运算符.
cd research/im2txt
bazel build -c opt //im2txt:run_inference
# 忽略 GPU (仅在GPU受内存限制时才需要使用,例如通过运行训练脚本)。
export CUDA_VISIBLE_DEVICES=""
# 运行推理(inference)并生成说明文字。
bazel-bin/im2txt/run_inference \
--checkpoint_path=${CHECKPOINT_PATH} \
--vocab_file=${VOCAB_FILE} \
--input_files=${IMAGE_FILE}示例输出:
Captions for image COCO_val2014_000000224477.jpg:
0) a man riding a wave on top of a surfboard . (p=0.040413)
1) a person riding a surf board on a wave (p=0.017452)
2) a man riding a wave on a surfboard in the ocean . (p=0.005743)提示:你可能会获得不同的结果。不同模型之间的一些变化是预料之中的。
这里是图像:
