python爬虫——城市(北京市)公交路线、公交站点及坐标(一)
干货!记录与总结!
环境:
python3.6
爬虫步骤:
一、确定爬取的链接
二、读取链接指向的内容
三、从中抽取关键元素
四、写入文件/数据库
获取公交线路及站点
一、确定URL
百度搜索公交查询,显示8684公交线路查询、图吧公交查询、各城市的公交查询,稍微对比一下,选了8684公交查询,网址为 http://www.8684.cn/。网站命名规则很简单,http://城市英文全拼.8684.cn/,我选择爬取北京公交http://beijing.8684.cn/。
公交路线包括两种:1、以数字开头1-9 2、以字母或汉字开头

数字、字母一块爬,既然要找线路及站点,看不见站点怎么爬?接着找链接吧!点开1是这样的,不对啊!接着点1路,运行时间、票价、公交公司、站点都有了,url找到!

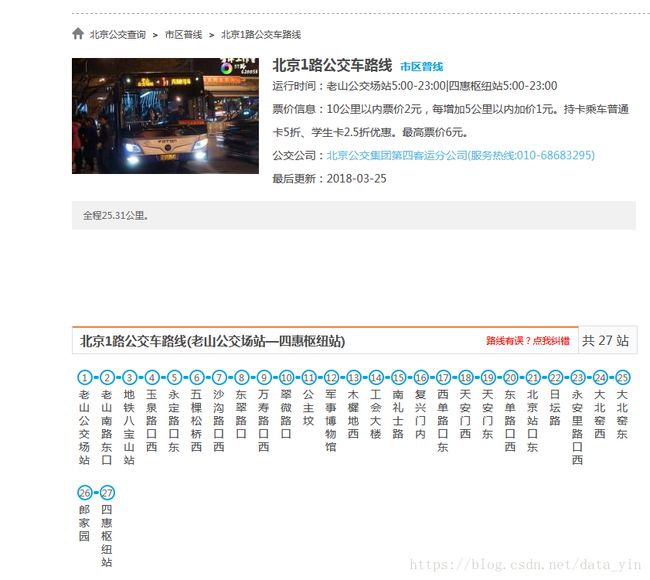
回忆一下,找链接分三步:
1、城市公交链接
2、数字、字母开头线路的链接
3、线路详细信息的链接
二、读取链接内容
请求8684北京公交首页http://beijing.8684.cn/,F12进入页面调试,数字开头内容在

请求数字1开头的页面http://beijing.8684.cn/list1,进入调试界面,和上边操作类似,8684对爬虫还是很友好的,哈哈!
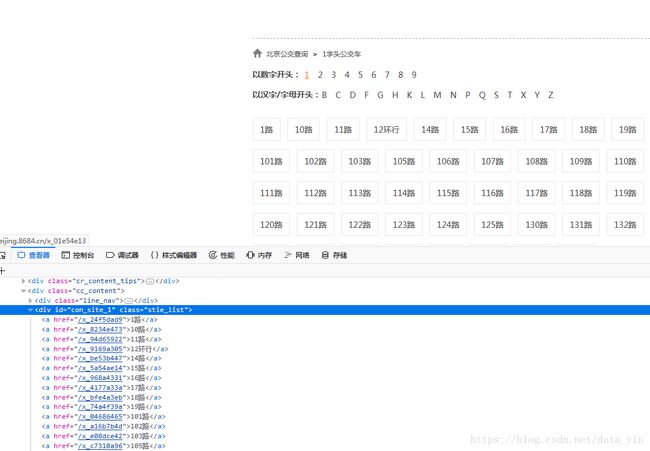
请求线路详细信息页面,和上面操作相同,具体如下图:
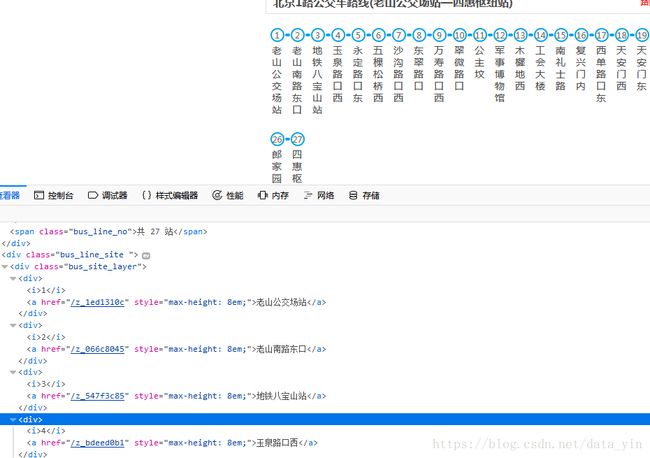
三、抽取关键元素
网页爬虫,先调requests包、再端一碗BeautifulSoup,import 一个time用以休眠,调error防程序崩溃,创建函数获取链接列表,for循环嵌套读取链接,抽取信息。
根据想抽取信息,开撸代码,具体代码如下:(代码在文章末尾,代码稚嫩,实为可用,如有问题,评论留言!)
四、写入文件/数据库
数据不多,写入文本文件了
代码:
# coding = 'utf-8'
import requests
import time
from bs4 import BeautifulSoup as bs
from urllib.error import URLError
"""通过8684公交获取城市公交线路站点"""
#创建城市
city = 'beijing'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) + \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
url_1 = 'http://'+city+'.8684.cn'
#创建函数,获取各值开头的链接
def get_html_1(url_1,headers):
try:
#模拟浏览器Chrome
html_1 = requests.get(url_1,headers=headers)
except URLError:
return None
try:
html_1_contents = bs(html_1.text,'html5lib')
except AttributeError:
return Non
except UnboundLocalError:
return None
try:
bus_kt_r1 = html_1_contents.find('div',{'class':'bus_kt_r1'})
bus_kt_r2 = html_1_contents.find('div',{'class':'bus_kt_r2'})
#获取所有链接
links_1_list = []
for r1 in bus_kt_r1:
links_1_list.append(r1['href'])
for r2 in bus_kt_r2:
links_1_list.append(r2['href'])
except AttributeError:
return None
return links_1_list
#创建函数,获取某值开头的所有公交线路的链接
def get_html_2(url_2,headers):
try:
html_2 = requests.get(url_2,headers=headers)
except URLError:
return None
try:
html_2_contents = bs(html_2.text,'html5lib')
except AttributeError:
return None
except UnboundLocalError:
return None
try:
stie_list = html_2_contents.find('div',{'id':'con_site_1','class':'stie_list'})
links_2_list = []
for link in stie_list:
links_2_list.append(link['href'])
except AttributeError:
return None
return links_2_list
#创建函数,获取具体公交线路上行站点名称
def get_html_3(url_3,headers):
try:
html_3 = requests.get(url_3,headers=headers)
except URLError:
return None
try:
html_3_contents = bs(html_3.text,'html5lib')
except AttributeError:
return None
except UnboundLocalError:
return None
try:
bus_line_txt = html_3_contents.findAll('div',{'class':'bus_line_txt'})
bus_line_up = bus_line_txt[0].strong.get_text()
with open('city_bus_line.txt','a') as f:
f.write(bus_line_up+'\n')
bus_line_site = html_3_contents.findAll('div',{'class':'bus_site_layer'})
bus_site_up = bus_line_site[0].findAll('a')
bus_site_up_list = []
for a in bus_site_up:
with open('city_bus_line.txt','a') as f:
f.write(a.get_text()+'\n')
bus_line_down = bus_line_txt[1].strong.get_text()
with open('city_bus_line.txt','a') as f:
f.write(bus_line_down+'\n')
bus_site_down = bus_line_site[1].findAll('a')
bus_site_down_list = []
for b in bus_site_down:
with open('city_bus_line.txt','a') as f:
f.write(b.get_text()+'\n')
except AttributeError:
return None
except IndexError:
return None
#创建函数,获取具体公交线路下行站点名称
def get_html_3_down(url_3,headers):
try:
html_3 = requests.get(url_3,headers=headers)
except URLError:
return None
try:
html_3_contents = bs(html_3.text,'html5lib')
except AttributeError:
return None
except UnboundLocalError:
return None
try:
bus_line_txt = html_3_contents.findAll('div',{'class':'bus_line_txt'})
bus_line_down = bus_line_txt[1].strong.get_text()
with open('city_bus_line.txt','a') as f:
f.write(bus_line_down+'\n')
bus_line_site = html_3_contents.findAll('div',{'class':'bus_site_layer'})
bus_site_down = bus_line_site[1].findAll('a')
bus_site_down_list = []
for b in bus_site_down:
with open('city_bus_line.txt','a') as f:
f.write(b.get_text()+'\n')
except IndexError:
return None
except AttributeError:
return None
#获取城市公交线路站点
for a in get_html_1(url_1,headers):
for b in get_html_2(url_1 + a,headers):
try:
for c in get_html_3(url_1 + b,headers):
pass
#一股脑异常处理
except TypeError:
continue
except KeyError:
continue
except AttributeError:
continue
获取公交站点坐标是调用百度地图API实现的,使用的服务是地点检索服务(又名Place API)中的矩形区域检索,将北京市行政区或分为3km*3km的子区域,遍历区域列表,未完待续。。。。。
请确认选中的文本是完整的单词或句子。
目前仅谷歌翻译支持汉译英。