TensorFlow极简教程:创建、保存和恢复机器学习模型
TensorFlow:保存/恢复和混合多重模型
如何实际保存和加载
-
保存(saver)对象
可以使用 Saver 对象处理不同会话(session)中任何与文件系统有持续数据传输的交互。构造函数(constructor)允许你控制以下 3 个事物:
-
目标(target):在分布式架构的情况下用于处理计算。可以指定要计算的 TF 服务器或「目标」。
-
图(graph):你希望会话处理的图。对于初学者来说,棘手的事情是:TF 中总存在一个默认的图,其中所有操作的设置都是默认的,所以你的操作范围总在一个「默认的图」中。
-
配置(config):你可以使用 ConfigProto 配置 TF。查看本文最后的链接资源以获取更多详细信息。
Saver 可以处理图的元数据和变量数据的保存和加载(又称恢复)。它需要知道的唯一的事情是:需要使用哪个图和变量?
默认情况下,Saver 会处理默认的图及其所有包含的变量,但是你可以创建尽可能多的 Saver 来控制你想要的任何图或子图的变量。这里是一个例子:
import tensorflow as tf
import os
dir = os.path.dirname(os.path.realpath(__file__))
# First, you design your mathematical operations
# We are the default graph scope
# Let's design a variable
v1 = tf.Variable(1. , name="v1")
v2 = tf.Variable(2. , name="v2")
# Let's design an operation
a = tf.add(v1, v2)
# Let's create a Saver object
# By default, the Saver handles every Variables related to the default graph
all_saver = tf.train.Saver()
# But you can precise which vars you want to save under which name
v2_saver = tf.train.Saver({"v2": v2})
# By default the Session handles the default graph and all its included variables
with tf.Session() as sess:
# Init v and v2
sess.run(tf.global_variables_initializer())
# Now v1 holds the value 1.0 and v2 holds the value 2.0
# We can now save all those values
all_saver.save(sess, dir + '/data-all.chkp')
# or saves only v2
v2_saver.save(sess, dir + '/data-v2.chkp')
如果查看你的文件夹,它实际上每创建 3 个文件调用一次保存操作并创建一个检查点(checkpoint)文件,我会在附录中讲述更多的细节。你可以简单理解为权重被保存到 .chkp.data 文件中,你的图和元数据被保存到 .chkp.meta 文件中。
-
恢复操作和其它元数据
一个重要的信息是,Saver 将保存与你的图相关联的任何元数据。这意味着加载元检查点还将恢复与图相关联的所有空变量、操作和集合(例如,它将恢复训练优化器)。
当你恢复一个元检查点时,实际上是将保存的图加载到当前默认的图中。现在你可以通过它来加载任何包含的内容,如张量、操作或集合。
import tensorflow as tf
# Let's load a previously saved meta graph in the default graph
# This function returns a Saver
saver = tf.train.import_meta_graph('results/model.ckpt-1000.meta')
# We can now access the default graph where all our metadata has been loaded
graph = tf.get_default_graph()
# Finally we can retrieve tensors, operations, collections, etc.
global_step_tensor = graph.get_tensor_by_name('loss/global_step:0')
train_op = graph.get_operation_by_name('loss/train_op')
hyperparameters = tf.get_collection('hyperparameters')
-
恢复权重
请记住,实际的权重只存在于一个会话中。这意味着「恢复」操作必须能够访问会话以恢复图内的权重。理解恢复操作的最好方法是将其简单地当作一种初始化。
with tf.Session() as sess:
# To initialize values with saved data
saver.restore(sess, 'results/model.ckpt.data-1000-00000-of-00001')
print(sess.run(global_step_tensor)) # returns 1000
-
在新图中使用预训练图
现在你知道了如何保存和加载,你可能已经明白如何去操作。然而,这里有一些技巧能够帮助你走得更快。
-
一个图的输出可以是另一个图的输入吗?
是的,但有一个缺点:我还不知道使梯度流(gradient flow)在图之间容易传递的一种方法,因为你将必须评估第一个图,获得结果,并将其馈送到下一个图。
这样一直下去是可以的,直到你需要重新训练第一个图。在这种情况下,你将需要将输入梯度馈送到第一个图的训练步骤……
-
我可以在一个图中混合所有这些不同的图吗?
是的,但你需要对命名空间(namespace)倍加小心。好的一点是,这种方法简化了一切:例如,你可以加载预训练的 VGG-16,访问图中的任何节点,嵌入自己的操作和训练整个图!
如果你只想微调(fine-tune)节点,你可以在任意地方停止梯度来避免训练整个图。
import tensorflow as tf
# Load the VGG-16 model in the default graph
vgg_saver = tf.train.import_meta_graph(dir + 'gg/resultsgg-16.meta')
# Access the graph
vgg_graph = tf.get_default_graph()
# Retrieve VGG inputs
self.x_plh = vgg_graph.get_tensor_by_name('input:0')
# Choose which node you want to connect your own graph
output_conv =vgg_graph.get_tensor_by_name('conv1_2:0')
# output_conv =vgg_graph.get_tensor_by_name('conv2_2:0')
# output_conv =vgg_graph.get_tensor_by_name('conv3_3:0')
# output_conv =vgg_graph.get_tensor_by_name('conv4_3:0')
# output_conv =vgg_graph.get_tensor_by_name('conv5_3:0')
# Stop the gradient for fine-tuning
output_conv_sg = tf.stop_gradient(output_conv) # It's an identity function
# Build further operations
output_conv_shape = output_conv_sg.get_shape().as_list()
W1 = tf.get_variable('W1', shape=[1, 1, output_conv_shape[3], 32], initializer=tf.random_normal_initializer(stddev=1e-1))
b1 = tf.get_variable('b1', shape=[32], initializer=tf.constant_initializer(0.1))
z1 = tf.nn.conv2d(output_conv_sg, W1, strides=[1, 1, 1, 1], padding='SAME') + b1
a = tf.nn.relu(z1)
-
协议缓冲区
协议缓冲区(Protocol Buffer/简写 Protobufs)是 TF 有效存储和传输数据的常用方式。
我不在这里详细介绍它,但可以把它当成一个更快的 JSON 格式,当你在存储/传输时需要节省空间/带宽,你可以压缩它。简而言之,你可以使用 Protobufs 作为:
-
一种未压缩的、人性化的文本格式,扩展名为 .pbtxt
-
一种压缩的、机器友好的二进制格式,扩展名为 .pb 或根本没有扩展名
这就像在开发设置中使用 JSON,并且在迁移到生产环境时为了提高效率而压缩数据一样。用 Protobufs 可以做更多的事情,如果你有兴趣可以查看教程
整洁的小技巧:在张量流中处理 protobufs 的所有操作都有这个表示「协议缓冲区定义」的「_def」后缀。例如,要加载保存的图的 protobufs,可以使用函数:tf.import_graph_def。要获取当前图作为 protobufs,可以使用:Graph.as_graph_def()。
-
文件的架构
回到 TF,当保存你的数据时,你会得到 5 种不同类型的文件:
-
「检查点」文件
-
「事件(event)」文件
-
「文本 protobufs」文件
-
一些「chkp」文件
-
一些「元 chkp」文件
现在让我们休息一下。当你想到,当你在做机器学习时可能会保存什么?你可以保存模型的架构和与其关联的学习到的权重。你可能希望在训练或事件整个训练架构时保存一些训练特征,如模型的损失(loss)和准确率(accuracy)。你可能希望保存超参数和其它操作,以便之后重新启动训练或重复实现结果。这正是 TensorFlow 的作用。
在这里,检查点文件的三种类型用于存储模型及其权重有关的压缩后数据。
-
检查点文件只是一个簿记文件,你可以结合使用高级辅助程序加载不同时间保存的 chkp 文件。
-
元 chkp 文件包含模型的压缩 Protobufs 图以及所有与之关联的元数据(集合、学习速率、操作等)。
-
chkp 文件保存数据(权重)本身(这一个通常是相当大的大小)。
-
如果你想做一些调试,pbtxt 文件只是模型的非压缩 Protobufs 图。
-
最后,事件文件在 TensorBoard 中存储了所有你需要用来可视化模型和训练时测量的所有数据。这与保存/恢复模型本身无关。
下面让我们看一下结果文件夹的屏幕截图:
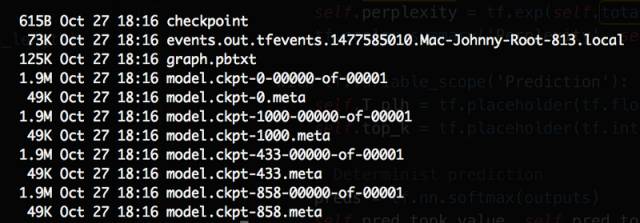
一些随机训练的结果文件夹的屏幕截图
-
该模型已经在步骤 433,858,1000 被保存了 3 次。为什么这些数字看起来像随机?因为我设定每 S 秒保存一次模型,而不是每 T 次迭代后保存。
-
chkp 文件比元 chkp 文件更大,因为它包含我们模型的权重
-
pbtxt 文件比元 chkp 文件大一点:它被认为是非压缩版本!
TF 自带多个方便的帮助方法,如:
在时间和迭代中处理模型的不同检查点。它如同一个救生员,以防你的机器在训练结束前崩溃。
-
参考资源
http://stackoverflow.com/questions/38947658/tensorflow-saving-into-loading-a-graph-from-a-file
http://stackoverflow.com/questions/34343259/is-there-an-example-on-how-to-generate-protobuf-files-holding-trained-tensorflow?rq=1
http://stackoverflow.com/questions/39468640/tensorflow-freeze-graph-py-the-name-save-const0-refers-to-a-tensor-which-doe?rq=1
http://stackoverflow.com/questions/33759623/tensorflow-how-to-restore-a-previously-saved-model-python
http://stackoverflow.com/questions/34500052/tensorflow-saving-and-restoring-session?noredirect=1&lq=1
http://stackoverflow.com/questions/35687678/using-a-pre-trained-word-embedding-word2vec-or-glove-in-tensorflow
https://github.com/jtoy/awesome-tensorflow
原文链接:https://blog.metaflow.fr/tensorflow-saving-restoring-and-mixing-multiple-models-c4c94d5d7125#.lms6atw2p