【CVPR 2016】faster r-cnn features for instance search 笔记
论文源码以及视频:http://imatge-upc.github.io/retrieval-2016-deepvision/
我自己制作的ppt地址:http://download.csdn.net/detail/dengbingfeng/9524748
这篇paper的解读默认大家对faster-rcnn有基本的了解....
1.整个网络结构

整个网络从总体上看是faster-rcnn的网络结构,上面一部分是faster-rcnn 的RPN net部分,RPN net的输出rpn proposals,网络的下面部分
是ROI pooling 加上三个全连接层,输出是class probabilities.
Image-wise pooling of activations(IPA): 这一步骤实际上抽出image的representation,具体的方法是从卷积层的最后一层
conv5_3(针对VGG16 Net,并且经过了reLu层之后),然后做pooling,具体pooling 的方法作者是借鉴另外一篇paper:《particular object retrieval
with integeral max-pooling of CNN activations》。举个例子来说:如果最后conv5_3得出的feature map的维度是K*W*H,其中K为卷积核的数目,W*H
为每一个卷积核卷积之后的feature map,这样对于每一个W*H的feature Map 采用max-pooling 或者sum-pooling 就能得到一个值。这样,整个K*W*H
采用pooling之后得到的feature即为K*1的向量。
Region-wise pooling of activations(RPA): 这一步骤得到的是region的representation,有了上面的IPA,这一步的RPA也很容易理解,
就是找出region proposals 的ROI pooling,在ROI pooling层上面做max-pooling。
2.fine-tuning faster rcnn
fine tuning 采用两种方式:
strategy1: fine tuning ROI pooling之后的三层网络。

strategy2:fine tuning network after conv_2
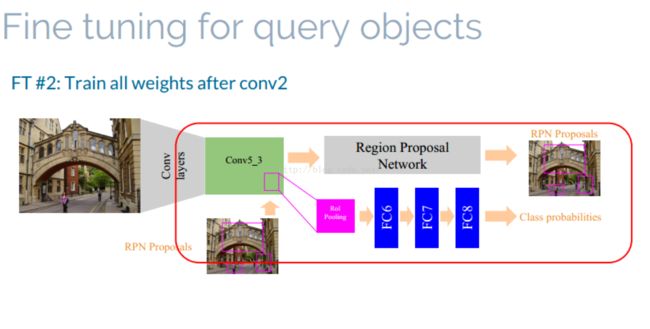
fine-tuining 所使用图像为query 图像以及将其做horizontal flip之后的图像(个人感觉图像好少)。
3.Image Retrieval
一共分为三个步骤:
1.过滤:提取出查询图像以及数据库图像的IPA,然后通过计算余弦距离将数据库图像进行排序。(整个过程都是使用的图像的IPA与区域无关)。
2.空间重排:
空间重排采用了两种方法:
Class-Agnostic Spatial Reranking (CA-SR):假设类别不可知,计算每一个query bounding box的RPA与采用第一部过滤前N幅图像每一个proposal的
余弦距离,最高的作为query与图像的余弦距离。
Class-Specific Spatial Reranking(CS-SR):使用和query相同的instances 来fine-tuin过后的整个网络,然后使用FC-8之后的class-probality 的类别得分
将其作为query与proposal 的得分。

3.查询扩展:最简单的查询扩展的方法。
4.实验
1.对比IPA以及RPA采用sumpooling 以及 maxpooling的好坏。最终得出IPA使用sumPooling RPA使用maxPooling

2.使用fine-tuin、重排、查询扩展的结果图:

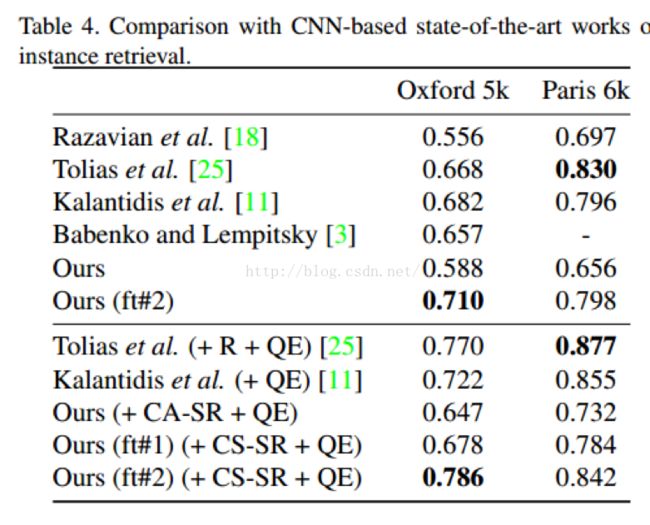
作者得出的结论是是使用第二种fine-tuin的方式能够使查询结果得到很大提高。
和stat-of-art方法的比较:
作者的conclusion:
1.suitable to obtain image and region features in a single forward pass.
2.Fine tuining as an effective solution to boost retrieval performance (subject to application time constrains)