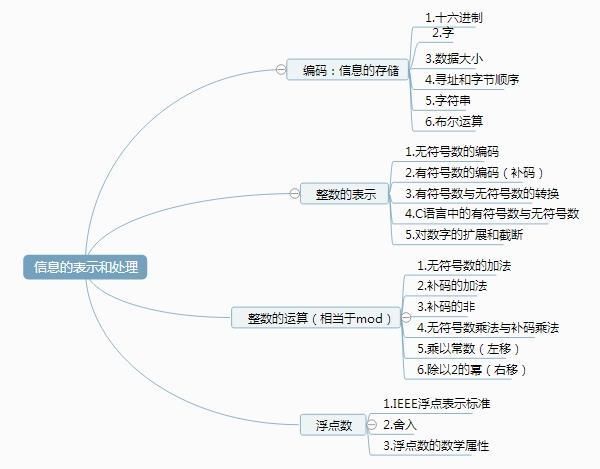
一、信息存储
- 系统将8位的块作为最小的可寻址存储器单位,机器级程序系统看成一个大的数组,然后通过地址来获得存储器中的这些块的内容。
- 数据在计算机中的存储都是用二进制,不过二进制不易表示,一般我们用十六进制来表示。如八位的十六进制范围为00~FF。
- 计算机的字长代表其整数数据的大小,同时也是系统絮凝地址空间最大大小。
- C语言中对布尔代数的操作有提供几种方式,比如&(与),|(或),~(取反),^(异或)。
二、整数的表示
我们描述用位来编码证书的两种不同的方式:
一种只能表示非负数,另一种能够表示负数、零和正数.
C语言支持的数据取值范围:
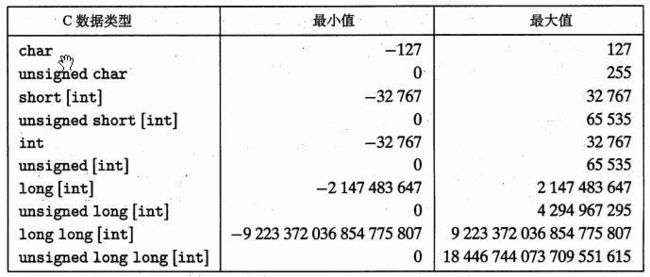
2.1整型数据类型
C语言支持多种整型数据类型—–表示有限范围的整数.
每种类型都能用关键字来指定大小,如:char、short、long或者long long.
不同大小的分配的字节数会根据机器的字长和编译器有所不同.
根据字节分配,不同的大小所能表示的值的范围是不同的.
2.2无符号数的编码
无符号的二进制表示有一个很重要的属性,就是每个介于0~2^w-1之间的数都有唯一一个w位的编码值.
2.3补码编码
最常见的有符号数的计算机表示方式就是补码形式.
在这个定义中,将字的最高有效位解释为负权.
每个介于-2^(w-1)和2^w-1之间的整数都有一个唯一长度为w的位向量二进制表示.
2.4有符号数和无符号数之间的转换
C语言允许在各种不同的数字数据类型之间做强制类型转换.
2.5C语言中的有符号数与无符号数
C语言支持所有整型数据类型的有符号和无符号运算.
C语言标注没有指定有符号数要采用某种表示,但是几乎所有的机器都使用补码.
C语言允许无符号数和有符号数之间的转换.转换的原则是底层的位表示保持不变.
2.6截断数字
假设我们不用额外的位来扩展一个数值,而是减少表示一个数字的位数.在一台典型32位机器上,当把int X强制类型转换为short时,我们就将32位的int截断为16位的short int.这个16位的位模式就是-12345的补码表示.当把它强制转换回int时,符号扩展把高16位设置为1,从而生成-12345的32位补码表示.
三、整型的运算
我们首先要来理解一下“字节膨胀”的概念:
比如我们以w=4位为例,进行无符号数[1111]=15和无1.符号数[1010]=10的加法运算,结果为25=[11001]需要5位来表示结果,依次类推我们如果要完整的表示运算结果,就不能对字长做任何限制。大部分编程语言都选择了固定精度的加减乘除运算,会对结果进行一定的处理。也就与我们数学上的运算有所不同,这一节我们就来学习这些处理方法。
首先来看看加法运算:我们会接触到[无符号的加法]和[补码的加法]。这两组加法运算使用的是相同的机器指令。
3.1.无符号数的加法
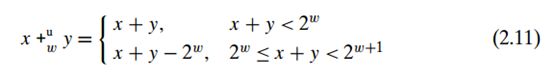
相当于截断高位。溢出的真正含义就是:完整的结果不能放入到固定精度的字长中去,于是最高位就被丢弃掉了。减去2的w次方,相当于结果mod(2的w次方)。
3.2补码的加法:
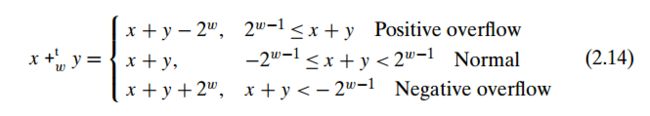
举例说明:
正溢出[0101] +[0101] = 5 + 5 = 10 = [01010]截断最高位0结果为[1010]=-6;
负溢出 [1000]+ [1011]= -8 + -5 = -13 = [10011]截断高位1结果为[0011]=3.
主要的原因还是我们使用的是固定精度的运算,由于结果不能被完整的保存,我们就需要使用截断高位保存低位的方法。这样做由于正溢出是两个大正数相加,完整的结果仍然数正数,截断最高位相当于减少了2的w次方;而负溢出数两个大负数相加,完整的结果仍然数负数,截断高位1以后相当于加上了2的w次方。
3.3补码的非
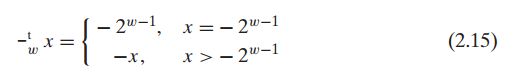
以w=4位为例,补码的表示范围在[-8,7]之间,也就是说[-7,7]内的数可以表示为-x,但是对于最小的TMin=-8的情况怎么办呢?C语音中求解补码的方法是:每位求反,结果加1.
就如[0101] = 5 每位求反为 [1010] 再加上1为;
[1011]补码表示为-5。那么同样的方法计算[1000] = -8的求反[0111]再加上1的结果还是[1000] = -8我们就认为的定义了:-8的非就是-8,也就是上个算式中显示的内容了。
3.4整数运算总结
整数运算不论是加减乘除,其本身来说就是一种mod运算。由于结果的固定精度,大的就可能会溢出。补码和无符号数使用的是相同的机器运算指令,有相同的位级表示。特别是无符号数的一些意向不到的行为,程序员特别需要注意。
四、浮点数
4.1 IEEE浮点表示标准
![]()
说明:
符号(S):当s=1为负数,当s=0为正数;
尾数(M):表示从(1~2)或者(0~1)之间的数;
阶码(E):可以是负数
4.2 浮点数的数学属性
由于舍入而产生的丢失精度,浮点数的运算中不具有结合性
C语言中的浮点数使用注意事项:
