数据结构与算法--最小生成树之Kruskal算法
上一节介绍了Prim算法,接着来看Kruskal算法。
我们知道Prim算法是从某个顶点开始,从现有树周围的所有邻边中选出权值最小的那条加入到MST中。不妨换个思路,为何不一开始就将所有边中权值最小的边取出来搭建二叉树?这里说的最小权值是全局的最小权值,而Prim说的最小权值,是已经访问过的顶点的周围的边中的最小权值,这个范围当然比全部边要小。
于是需要对边按照权值升序排列,由于每次取出的最小权值分布在图的各个地方,一开始各条边可能并不是相连的,图中就会形成多棵树。随着添加的边越来越多,两棵树合并成一棵树(用可以找到的权值最小的边连接),如此合并下去,最后只剩下一棵,这就是最小生成树。选出的边不能造成一棵树产生环,而树可以看作连通分量,不能有环就是说——处于同一个连通分量中的任意两个结点不能再将它们连通(否则必然成环)。所以我们在选出边准备连接树的时候一定要判断,选出的边如果其两个顶点处于同一个连通分量中,那么要跳过本次连接。
关键就是如何判断两个顶点是否处于同一连通分量;以及如果两个顶点不处于同一连通分量,如何将他们合并到同一连通分量中?
为此,我们要先实现一个UnionFind类来完成上述工作。
连通分量--UnionFind类的实现
package Chap7;
public class UnionFind {
// id相同的分量是连通的
private int[] id;
//连通分量的个数
private int count;
public UnionFind(int num) {
count = num;
id = new int[num];
for (int i = 0; i < num; i++) {
id[i] = i;
}
}
public int count() {
return count;
}
// 所属连通分量的id
public int find(int p) {
return id[p];
}
public void union(int p ,int q) {
int pID = find(p);
int qID = find(q);
if (pID == qID) {
return;
}
// 将和p同一个连通分量的结点全部归到和q一个分量中,即将p所在连通分量与q所在连通分量合并。
// 反过来也可以
// if (id[i] == qID) {
// id[i] = pID;
// }
for (int i = 0; i < id.length; i++) {
if (id[i] == pID) {
id[i] = qID;
}
}
// 合并后,连通分量减少1
count--;
}
public boolean isConnected(int p, int q) {
return find(p) == find(q);
}
}
至关重要的就是这个id[]标识数组了。它的功能就是将处于同一连通分量的结点归并到同一个id中,也就是说如果某两个结点他们的id相同,那么他们就处于同一个连通分量中。比如id[3] = id[4]= id[6] = 8,id[2] = id[4] = id[9] = 1,那么结点3,4,6处于同一个连通分量中,结点2、4、9处于另外一个连通分量中。
find就是找到某结点所属的连通分量,如果find到两个结点属于同一个连通分量(id),isConnected返回true。
union方法将两个不连通的分量连通。具体做法是,若结点p和q不属于同一个连通分量,则将p所在的连通通分量A的全部结点的id改成和q所在连通分量B的id一样——也就是连接p-q,连通分量A和连通分量B就将合并成一个连通分量了。
这个算法很简单,不过有待优化,可以看到每次合并分量都遍历了整个id[],所以针对id[]进行优化。优化后id[]更像是一种树形结构,最早存在于连通分量中的为该连通分量的根结点,之后加进来的结点成为根结点的孩子结点。因为一棵树就是一个连通分量,如果两个结点往上追溯,他们有相同的根结点,说明这两个结点位于同一棵树中,也就是说这两个结点位于同一个连通分量中。
基于此思想,我们来修改下UnionFind的代码,只需变动find和union方法。
package Chap7;
public class UnionFind {
//
private int[] parentTo;
//连通分量的个数
private int count;
public UnionFind(int num) {
count = num;
parentTo = new int[num];
for (int i = 0; i < num; i++) {
parentTo[i] = i;
}
}
public int count() {
return count;
}
public int find(int p) {
// p = parentTo[p]说明到达树的根结点,返回根结点
while (p != parentTo[p]) {
p = parentTo[p];
}
return p;
}
public void union(int p,int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot) {
return;
}
// 这行的意思就是q所在连通分量和q所在连通分量合并
// 从树的角度来看,p树的根结点成为了q树根结点的孩子结点
// 反过来也可以,parentTo[qRoot] = pRoot;
parentTo[pRoot] = qRoot;
count--;
}
public boolean isConnected(int p, int q) {
return find(p) == find(q);
}
}
首先我们将id[]改成了parentTo[],命名更易于理解。未优化的版本id[]存放的是各个结点所属的连通分量的标识,id表达的意义再合适不过。不过在优化的版本中,该数组是树形结构了,里面存的是某结点的父结点,用parentTo比较恰当,比如parent[3] = 4表达的意思是结点3的父结点是4。
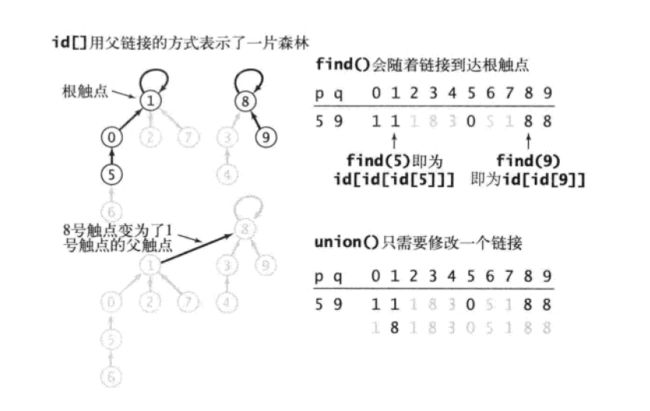
上图的有两个连通分量,其中1和8作为根结点,可以看到根结点有p = parent[p]这一特点。它们都是初始值,从初始化代码中可以看出一开始parent[i] = i,所谓的根结点其实就是parent[i]从来没有被赋值过。
现在find(int p)方法就比较好理解了,它找到的就是p所在连通分量(树)的根结点。如果两个结点它们的根结点相同,说明处于同一个连通分量(同一棵树),这就解释了isConnected方法的实现。再看union方法,如果两个结点属于不同的树,将这两棵树连接,p树的根结点成为了q树根结点的孩子结点,其实就是两个连通分量合并成一个连通分量。和未优化版本相比,合并分量只修改了数组中一个元素的值,不用遍历整个数组了。
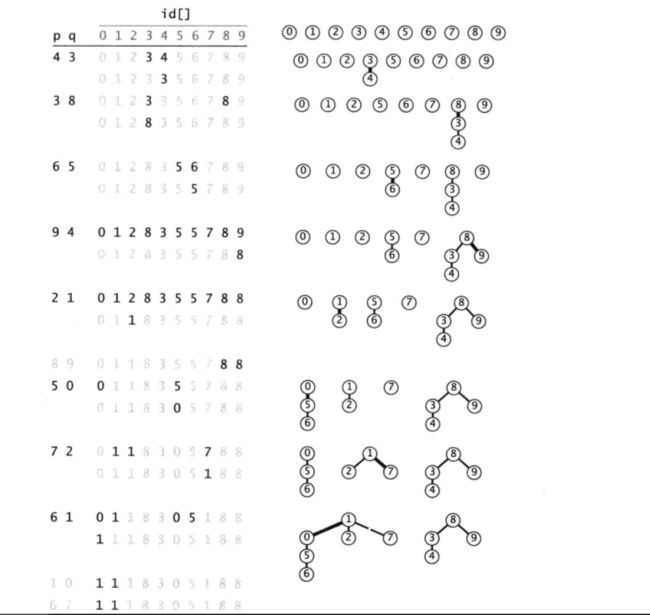
下图给出了分量合并的过程。
Kruskal算法实现
好了,有了这个工具,实现Kruskal算法就相当简单了。
package Chap7;
import java.util.*;
public class Kruskal {
private Queue mst;
public Kruskal(EdgeWeightedGraph graph) {
mst = new LinkedList<>();
Queue edges = new PriorityQueue<>(graph.edges());
UnionFind uf = new UnionFind(graph.vertexNum());
// 只要mst边小于n-1就进入循环,在循环内添加一条后就变成了n-1条
while (!edges.isEmpty() && mst.size() < graph.vertexNum() -1) {
// 优先队列,删除最小权值的边
Edge edge = edges.poll();
int v = edge.either();
int w = edge.other(v);
if (uf.isConnected(v, w)) {
continue;
}
uf.union(v, w);
mst.offer(edge);
}
}
public Iterable edges() {
return mst;
}
public double weight() {
return mst.stream().mapToDouble(Edge::weight).sum();
}
public static void main(String[] args) {
List vertexInfo = Arrays.asList("v0", "v1", "v2", "v3", "v4", " v5", "v6", "v7");
int[][] edges = {{4, 5}, {4, 7}, {5, 7}, {0, 7},
{1, 5}, {0, 4}, {2, 3}, {1, 7}, {0, 2}, {1, 2},
{1, 3}, {2, 7}, {6, 2}, {3, 6}, {6, 0}, {6, 4}};
double[] weight = {0.35, 0.37, 0.28, 0.16, 0.32, 0.38, 0.17, 0.19,
0.26, 0.36, 0.29, 0.34, 0.40, 0.52, 0.58, 0.93};
EdgeWeightedGraph graph = new EdgeWeightedGraph<>(vertexInfo, edges, weight);
Kruskal kruskal = new Kruskal(graph);
System.out.println("MST的所有边为:" + kruskal.edges());
System.out.println("最小成本和为:" + kruskal.weight());
}
}
代码流程比Prim算法清晰得多,理解起来也容易。无非是取出一条最小权值的边,先判断这条边中的两个顶点是否位于同一个连通分量中(同一棵树),若已连通则忽略这条边;否则将这两个顶点连通,并将这条边加入到MST。
最后注意一点,我们的Prim算法和Kruskal算法都是针对无向加权图,若是要对有向加权图处理,那被称为最小树形图,所用到的算法是朱刘算法。
by @sunhaiyu
2017.9.21