软件工程结对作业二
结对队友、博客链接、GitHub项目地址、分工
作业链接 https://edu.cnblogs.com/campus/fzu/FZUSoftwareEngineering1816W/homework/2160
- 结对成员
- 姚志辉:031602142
- 博客地址:http://www.cnblogs.com/52wu244/
- 分工:负责项目各个模块功能的实现
- 王龙涛:031602134
- 博客地址:https://www.cnblogs.com/wang371091997/p/9781183.html
- 分工:负责爬取部分,附加题部分,一起Debug,解决问题
- 姚志辉:031602142
GitHub地址:https://github.com/xiaozhirensan/PairProject-C
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| ? Estimate | ? 估计这个任务需要多少时间 | 10 | 30 |
| Development | 开发 | 600 | 900 |
| ? Analysis | ? 需求分析 (包括学习新技术) | 300 | 480 |
| ? Design Spec | ? 生成设计文档 | 60 | 50 |
| ? Design Review | ? 设计复审 | 10 | 5 |
| ? Coding Standard | ? 代码规范 (为目前的开发制定合适的规范) | 20 | 15 |
| ? Design | ? 具体设计 | 30 | 30 |
| ? Coding | ? 具体编码 | 600 | 1020 |
| ? Code Review | ? 代码复审 | 120 | 60 |
| ? Test | ? 测试(自我测试,修改代码,提交修改) | 120 | 60 |
| Reporting | 报告 | 120 | 90 |
| ? Test Repor | ? 测试报告 | 60 | 30 |
| ? Size Measurement | ? 计算工作量 | 30 | 20 |
| ? Postmortem & Process Improvement Plan | ? 事后总结, 并提出过程改进计划 | 120 | 50 |
| 合计 | 2210 | 2810 |
解题思路描述与设计实现说明
爬虫使用
- 我的python爬虫学习过程:https://blog.csdn.net/FZUMRWANG/article/details/82944100
- 我的思路
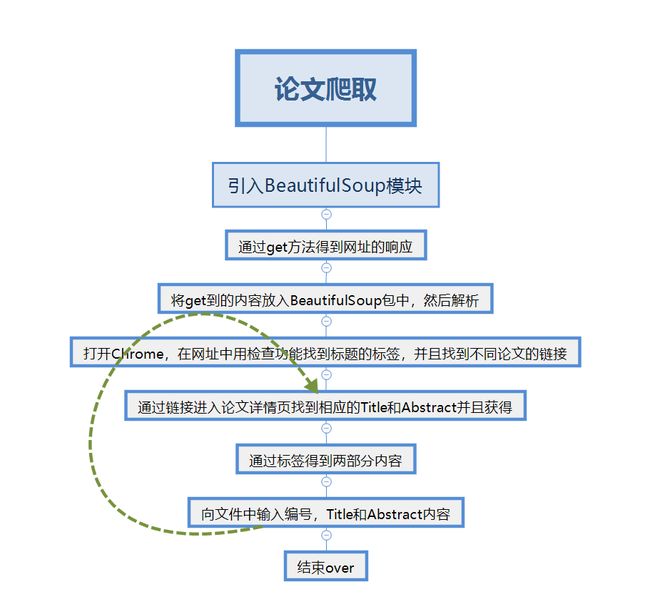
import requests
from bs4 import BeautifulSoup #引入BeautifulSoup模块
i=0
res = requests.get('http://openaccess.thecvf.com/CVPR2018.py') #通过监听网页可知使用get方法
res.encoding='utf-8' #若是有中文则需要加上utf-8编码
soup = BeautifulSoup(res.text,'html.parser') #将get到的内容放入BeautifulSoup包中,并且使用html.parser解析由requests.get所得到的html页面内容
head='http://openaccess.thecvf.com/' #由于所得到的链接可能不全,因此加上前面的总链接,有时候不用
for news in soup.select('.ptitle'): #ptitle是通过观察每一个标题的分隔符而得到的,通过Chrome的检查功能中的选择功能来选择标题然后何可看出每一个标题是使用ptitle分隔,不同网页可能不同,如果ptitle是class的话用.,如果是id的话用#
if len(news.select('a'))>0: #由于得到的list可能为空,因此加此判断
a=head+news.select('a')[0]['href'] #选择ptitle下标签中的href链接
#print(h2,head+a)
res2 = requests.get(a) #通过get方法得到网址的回应
res.encoding='utf-8'
soup2 = BeautifulSoup(res2.text,'html.parser')
h2=soup2.select('#papertitle')[0].text.strip()
article=soup2.select('#abstract')[0].text.strip()
#print('Title:',h2)
#print('Abstract:',article)
with open('D:\\result.txt','a',encoding='gb18030',errors='ignore') as f:
f.write(str(i))
f.write('\n')
f.write('Title: '+h2)
f.write('\n')
f.write('Abstract: '+article)
f.write('\n')
f.write('\n')
f.write('\n')
i=i+1
- 我爬取的结果

- 爬取结果附件:https://files.cnblogs.com/files/wang371091997/result.zip
代码组织与内部设计实现&&算法流程图
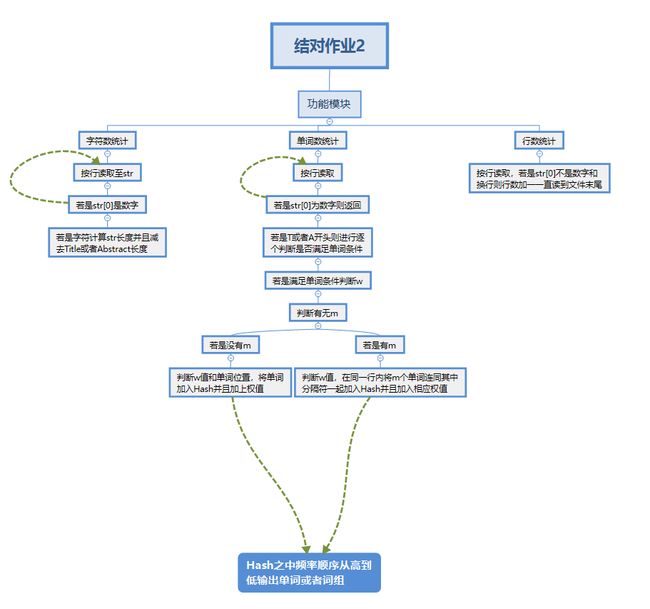
说明算法的关键
- 单词统计:只有连续四个是字母就是一个单词,有分隔符隔开就重新开始判断,并且将单词加入Hash,然后通过判断w以及单词所在的位置将value值+10或者+1
- 词组统计:在单词判断的基础之上进行词组的统计,即将m个单词以及单词之间的分隔符加入词组,并且将词组加入Hash,然后通过判断w以及词组所在的位置将value值+10或者+1
- 行数统计:直接使用getline按行读取,然后去除掉不在统计范围内的行即可
- 权值的计算:就如同上面的单词和词组统计,判断w然后Hash中value+10或者+1
关键代码解释
- 命令行解释类
struct Command {
bool _i; //是否按照指定路径读入文件
bool _o; //是否按照指定路径读出文件
bool _w; //是否加入词频权重统计
bool _m; //是否开启词组词频统计功能
bool _n; //是否开启自定义词频统计输出
char inFile[MAX_PATH_LENGTH]; //读入文件路径
char outFile[MAX_PATH_LENGTH]; //读出结果路径
int m; //词组中单词数
int n; //数组数
Command() {
_i = false;
_o = false;
_w = false;
_m = false;
_n = false;
strcpy_s(inFile, "input.txt"); //将初始读入文件设置为input.txt
strcpy_s(outFile, "output.txt"); //将初始读出文件设置为result.txt
m = 1;
n = 10;
}
void commandAnalyse(char commandStr[], Command &command);
int swiftNumber(char str[]);
};Command类用于解析用户输入的命令行,将自定义参数设置为bool型变量,同时给各参数赋予初值,第一次写的代码纯粹为一个函数,各种变量纷杂,可读性很差。经过改进之后,此程序可移植性高,结构清晰,且封装较好。
- 词组频数统计函数
void WordList::wordCount(string fileName, WordList &wordList, int m, bool _w)
{
char word[MAX_WORD_LENGTH] = { 0 };
char wordStr[2000] = { 0 };
string str;
ifstream inFile;
inFile >> noskipws;
inFile.open(fileName);
int wordposition = 0;
int wordPosition = 0;
char c;
int delta = 'a' - 'A';
int i = 0, j = 0; //记录字符当前位置
int n = m;
while (getline(inFile, str))
{
if (str[0] != 'T'&&str[0] != 'A')
continue;
c = str[0];
while (c != '\0')
{
c = str[i];
if (c <= 'Z'&&c >= 'A') c += delta;
bool separator1 = (c >= 'a'&&c <= 'z');
bool separator2 = (c >= '0'&&c <= '9');
if (separator1)
{
wordposition++;
wordStr[wordPosition] = c;
wordPosition++;
}
if (separator2)
{
if (wordposition < 4)
{
memset(wordStr, '\0', sizeof(wordStr));
wordposition = 0;
wordPosition = 0;
}
else
{
wordStr[wordPosition] = c;
wordPosition++;
}
}
if (!separator1 && !separator2 && wordposition < 4)
{
memset(wordStr, '\0', sizeof(wordStr));
memset(word, '\0', sizeof(word));
n = m;
wordPosition = 0;
wordposition = 0;
j = i;
}
if (c==':' && wordposition >= 4 && strcmp(wordStr, "title") == 0)
{
state = 1;
wordPosition = 0;
wordposition = 0;
memset(wordStr, '\0', sizeof(wordStr));
}
if (c == ':' && wordposition >= 4 && strcmp(wordStr, "abstract") == 0)
{
state = 2;
wordPosition = 0;
wordposition = 0;
memset(wordStr, '\0', sizeof(wordStr));
}
if (!separator1 && !separator2 && wordposition >= 4 && n >= 1)
{
if (n > 1)
{
wordStr[wordPosition] = c;
}
strcat_s(word, wordStr);
memset(wordStr, '\0', sizeof(wordStr));
if (n == m)
j = i;
if (n == 1)
{
wordList.addWord(word, _w);
memset(word, '\0', sizeof(word));
n = m+1;
i = j;
}
wordPosition = 0;
wordposition = 0;
n--;
}
i++;
}
memset(word, '\0', sizeof(word));
memset(wordStr, '\0', sizeof(wordStr));
i = 0;
}
inFile.close();
}此函数为单词处理类WordList中的一个函数,功能为抽取单词,并将文本字符串转换为词组存储进入链表,这部分花费了较多时间并进行了多次改进。
附加题设计与展示
- 爬取了论文作者和论文时间
- 文本链接:https://files.cnblogs.com/files/wang371091997/author.zip
- 结果截图:

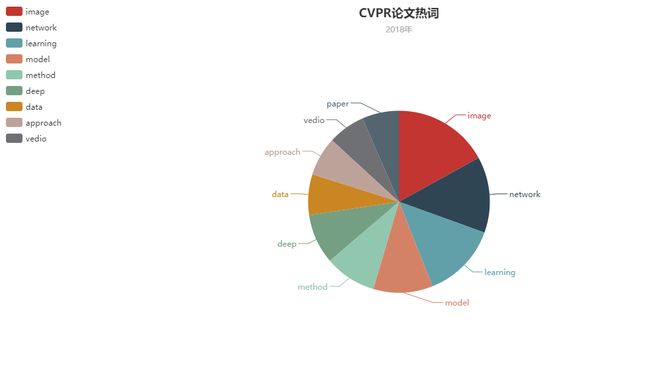
统计2018年热度最高的十个名词并且制作成饼图展示数据
- 饼图链接:http://myecharts.applinzi.com/bingtu.html
- 结果展示
- 可视化代码
ECharts
性能分析与改进
- 描述你改进的思路
改进思路可归纳为三点
第一,将命令行解析函数抽象为一个类,类包括属性和方法,变量抽象为属性,字符串解析函数为方法。
第二,将单词加入链表时,启用hash函数形成单词词表,将每次添加如链表的单词利用其ASCCI码值抽象为一个数值,这样可以快速找到所需单词。
第三,将逐个字符读取文件转换为逐行读取文件,这样处理字符串会更加方便,减少了代码量。
- 展示性能分析图和程序中消耗最大的函数
void WordList::wordCount(string fileName, WordList &wordList, int m, bool _w)
{
char word[MAX_WORD_LENGTH] = { 0 };
char wordStr[2000] = { 0 };
string str;
ifstream inFile;
inFile >> noskipws;
inFile.open(fileName);
int wordposition = 0;
int wordPosition = 0;
char c;
int delta = 'a' - 'A';
int i = 0, j = 0; //记录字符当前位置
int n = m;
while (getline(inFile, str))
{
if (str[0] != 'T'&&str[0] != 'A')
continue;
c = str[0];
while (c != '\0')
{
c = str[i];
if (c <= 'Z'&&c >= 'A') c += delta;
bool separator1 = (c >= 'a'&&c <= 'z');
bool separator2 = (c >= '0'&&c <= '9');
if (separator1)
{
wordposition++;
wordStr[wordPosition] = c;
wordPosition++;
}
if (separator2)
{
if (wordposition < 4)
{
memset(wordStr, '\0', sizeof(wordStr));
wordposition = 0;
wordPosition = 0;
}
else
{
wordStr[wordPosition] = c;
wordPosition++;
}
}
if (!separator1 && !separator2 && wordposition < 4)
{
memset(wordStr, '\0', sizeof(wordStr));
memset(word, '\0', sizeof(word));
n = m;
wordPosition = 0;
wordposition = 0;
j = i;
}
if (c==':' && wordposition >= 4 && strcmp(wordStr, "title") == 0)
{
state = 1;
wordPosition = 0;
wordposition = 0;
memset(wordStr, '\0', sizeof(wordStr));
}
if (c == ':' && wordposition >= 4 && strcmp(wordStr, "abstract") == 0)
{
state = 2;
wordPosition = 0;
wordposition = 0;
memset(wordStr, '\0', sizeof(wordStr));
}
if (!separator1 && !separator2 && wordposition >= 4 && n >= 1)
{
if (n > 1)
{
wordStr[wordPosition] = c;
}
strcat_s(word, wordStr);
memset(wordStr, '\0', sizeof(wordStr));
if (n == m)
j = i;
if (n == 1)
{
wordList.addWord(word, _w);
memset(word, '\0', sizeof(word));
n = m+1;
i = j;
}
wordPosition = 0;
wordposition = 0;
n--;
}
i++;
}
memset(word, '\0', sizeof(word));
memset(wordStr, '\0', sizeof(wordStr));
i = 0;
}
inFile.close();
}此函数为功能为抽取合法词组,是最消耗时间的函数段。
void WordList::addWord(char word[],bool _w)
{
//将word这个单词添加到词频统计表中(或者词频+1)
int p_index = Hash(word);
WordIndex* pIndex = index[p_index];
while (pIndex != nullptr)
{
Word *pWord = pIndex->pWord;
if (!strcmp(word, pWord->word))
{
if (_w == true && state == 1)
pWord->num += 10;
else
pWord->num++;
Word *qWord = pWord->previous;
while (qWord->num < pWord->num)
{
if (qWord == pWordHead) return;
shiftWord(pWord);
qWord = pWord->previous;
}
while (strcmp(qWord->word, pWord->word) > 0)
{
if (qWord->num > pWord->num) return;
shiftWord(pWord);
qWord = pWord->previous;
}
return;
}
pIndex = pIndex->next;
}
Word *pWord;
if (_w == true && state == 1)
pWord = new Word(word, 10);
else
pWord = new Word(word, 1);
pWord->previous = pWordTail->previous;
pWord->next = pWordTail;
pWordTail->previous->next = pWord;
pWordTail->previous = pWord;
pIndex = new WordIndex(pWord, index[p_index]);
index[p_index] = pIndex;
Word *qWord = pWord->previous;
while (strcmp(qWord->word, pWord->word) > 0) {
if (qWord->num > pWord->num) return;
shiftWord(pWord);
qWord = pWord->previous;
}
}此函数功能为开启链表,存储词组,是空间消耗最大的函数。
遇到代码模块异常或者结对困难及解决方法
- 问题描述
- 问题1:无法识别标识符
- 问题2:执行之后某个文件无法使用
- 问题3:执行大文本文件之后不出现越界终端
- 做过哪些尝试
- 问题1尝试:卸载了vs......然后重装,i am sorry,我就是这么特立独行的蠢,然后在网络上查找资料
- 问题2尝试:不断的查找错误,修改代码,换使用函数,在网络上查找解决方法
- 问题3尝试:改变读取方法,将字符数组改成字符串
- 是否解决
- 问题1:已解决,是因为无法识别头文件,将头文件路径更新即可
- 问题2:已解决,是因为......我们删除并且改变使用函数之后解决了
- 问题3:已解决,是因为我们开的数组不够大
- 有何收获
- 解决的问题的过程中我又get到一种排查错误的方法
- 增强自己的抗压能力
- 明白了程序员的真正意义,我们笑谈:“我一直把头藏在帽子里是为了遮挡我头上的鸟窝,并且思考着我的代码”,这个梗我只有我和队友get到......
评价你的队友
- 值得学习的地方:@王龙涛,一句话评价:这个人是我处过最优秀的对象,哦不,队友。一入软工深似海,从此只做熬夜人,国庆之后这段时间课程较满,一般写代码和debug的时间都在晚上,在完成此次作业的过程中,我的队友@王龙涛非常认真负责,我负责的是各个功能代码模块,在他日以继日的监督督促下,我们成功达成连熬四夜依然生龙活虎debug的成就,他毅力坚定,不达目的不放弃的精神很值得我学习,我很荣幸能够碰到这么好的队友。
- 需要改进的地方:永远生活在灰色帽檐下的队友,你要好好爱自己,少熬夜,不然会肾虚的!
- 我们需要改进的地方:我希望下次我们能够计划好作业的每一个步骤,合作需要更加合理的安排时间,劳逸结合,隔空戳一戳队友,下次我们能一起早点睡嘛?听起来怪怪的。。
学习进度条
- python爬虫:18/10/3
- 结对项目开发:18/10/8-18/10/12