| psp2.1 |
personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
| Planning |
计划 |
20 |
30 |
| Estimate |
估计这个任务需要多少时间 |
10 |
5 |
| Development |
开发 |
80 |
95 |
| Analysis |
需求分析(包括学习新技术) |
200 |
180 |
| Design Spec |
生成设计文档 |
20 |
30 |
| Design Review |
设计复审 |
20 |
15 |
| Coding Standrd |
代码规范(为目前的开发制定合适的规范) |
30 |
20 |
| Design |
具体设计 |
50 |
40 |
| Coding |
具体编辑 |
120 |
150 |
| Code Review |
代码复审 |
40 |
30 |
| Test |
测试(自我测试,修改代码,提交修改) |
40 |
40 |
| Reporting |
报告 |
20 |
30 |
| Test Repor |
测试报告 |
20 |
15 |
| Size Measurement |
计算工作量 |
10 |
20 |
| Postmortem&Process Improvement Plan |
事后总结,并提出过程改进计划 |
30 |
35 |
| - |
合计 |
680 |
735 |
解题思路:
刚开始对于这个问题还是不知从何下手,从需求上来看,实现一个能够对文本文件文件中的单词的词频进行统计的控制台程序统计文件的字符数。统计文件的单词总数统计文件的有效行数:任何包含非空白字符的行,都需要统计。统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。按照字典序输出到文件result.txt。在考虑到题目要求的存储类型,我觉得用map容器应该可以解决我们的问题,想起以前算法老师讲过红黑二叉树,比较适合我们。在后来与舍友讨论的过程中,他建议我用unordered_map,这样会提高整体的运行效率,以及使用vector容器来存放对象,用sort函数进行排序。
代码详情:(主函数部分)
```#include
#include
#include
#include
#include
#include
#include
#include "CTget.h"
#include "CTline.h"
#include "CTwf.h"
#include "CTword.h"
using namespace std;
int main(int argc, char **argv)
{
ifstream in(argv[1]); // 从文件添加内容
ofstream fout("result.txt"); // 输出至结果文件
int wordnum = CTword(argv[1]);
int linenum = CTline(argv[1]);
int getnum = CTget(argv[1]);
fout << "characters:" << getnum << endl << "words: " << wordnum << endl << "lines: " << linenum << endl; //输出统计结果
fout.close();
CTwf(argv[1], fout);
getchar();
getchar();
return 0;
}```
我将4个功能独立出来写了四个头文件:
- 统计字符个数:
```#pragma once
#include
#include
#include
using namespace std;
int CTget(char *filename)
{
char word[2000];
int num=0;
string t;
ifstream in(filename);
while (in.getline(word, 2000))
{
t = word;
num =num+ t.length();
}
return num;
}```
- 统计行数:
```#pragma once
#include
#include
#include
using namespace std;
int CTline(char *filename)
{
int num = 0;
ifstream in(filename);
char word[2000];
while (in.getline(word, 2000))
num++;
return num;
}```
- 统计单词数量:
```#pragma once
#include
#include
#include
#include
#include
#include
#include
using namespace std;
int CTword(char *filename)
{
ifstream in(filename); // 打开文件
if (!in)
{
cerr << "无法找到输入文件" << endl;
return -1;
}
char word[2000];
string ss;
int WordNum=0;
while (in.getline(word, 2000)) // 遇到空白字符即停止读入
{
ss = word;
for (int i = 0; i < ss.length(); i++)//操作每一行
{
int count = 0;
for (int k = i;; k++) //对单词格式是否符合要求进行判断
{
if (ss[k] >= 'a'&&ss[k] <= 'z')
count++;
else if (ss[k] >= 'A'&&ss[k] <= 'Z')
{
count++;
}
else if (ss[k] >= '0'&&ss[k] <= '9'&&count >= 4)
count++;
else break;
}
if (count >= 4) //记录符合要求的内容
{
char words[100] = { '\0' };
for (int k = i; k < i + count; k++)
{
words[k - i] = ss[k];
}
WordNum++; //统计单词总数
i += count - 1;
}
else if (count>0 && count<4)i += count - 1;
else continue;
}
}
return WordNum;
}```
- 词频统计(最终目标!)
```#pragma once
#include
#include
#include
#include
#include
#include
#include
using namespace std;
const int m = 10;
bool cmp(int a, int b)
{
return a>b;
}
void adjustDown(vector
{
int min = i;
int child = 2 * min + 1;
while (i < m / 2)
{
if ((child + 1 < m) && (top[child]->second > top[child + 1]->second))
child++;
if ((child
{
swap(top[min], top[child]);
min = child;
child = 2 * min + 1;
}
else
break;
}
}
void topm(unordered_map
{
auto it = tree.begin();
// 初始化该二叉树
for (int i = 0; i < m; i++)
{
top[i] = it;
it++;
}
// 建立一个小根堆
for (int i = m / 2 - 1; i >= 0; i--)
{
adjustDown(top, i);
}
// 取topm
while (it != tree.end())
{
if (it->second > top[0]->second)
{
top[0] = it; // 如果大于根元素,则入堆;
adjustDown(top, 0); // 重新调整;
}
it++;
}
int a[10];
string b[10];
for (int i = m - 1; i >= 0; i--)
{
a[i] = tree[top[0]->first];
b[i] = top[0]->first;
top[0]->second = 1000000;
adjustDown(top, 0); // 重新调整;
}
sort(a, a + 10, cmp);
fout.open("result.txt", ios::app);
for (int i = 0; i < 10; i++)
{
fout << "<" << b[i] << ">: " << a[i] << endl;
}
fout.close();
}
void CTwf(char *filename, ofstream &fout)
{
int num = 0;
ifstream in(filename); // 打开文件
if (!in)
{
cerr << "无法打开输入文件" << endl;
exit(0);
}
char word[2000];
string ss;
unordered_map
while (in.getline(word, 2000)) // 遇到空白字符即停止读入
{
//num++;//统计行数
ss = word;
for (int i = 0; i < ss.length(); i++)//操作每一行
{
int count = 0;
for (int k = i;; k++) //对单词格式是否符合要求进行判断
{
if (ss[k] >= 'a'&&ss[k] <= 'z')
count++;
else if (ss[k] >= 'A'&&ss[k] <= 'Z')
{
count++;
}
else if (ss[k] >= '0'&&ss[k] <= '9'&&count >= 4)
count++;
else break;
}
if (count >= 4) //若符合要求,则记录
{
char words[100] = { '\0' };
for (int k = i; k < i + count; k++)
{
words[k - i] = ss[k];
}
string s;
s = words;
tree[s]++; num++;
i =i+count - 1;
}
else if (count>0 && count<4)i =i+ count - 1;
else continue;
}
}
if (num < 10)
{
cout << "所给文本不同单词数量不足10个,无法输出排序" << endl;
}
else
{
vector < unordered_map
topm(tree, top, fout);
}
}```
测试部分:
这是完成后用vs的性能探测器探测之后的结果,但是对于整体的优化还需要进一步的学习,主要时间还是用于主函数和词频统计的部分。
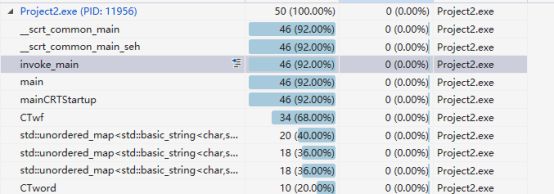
测试文档:
测试结果:

心得体会:
这次的作业对于我个人是一个极大的挑战,我之前对于本次作业所用到的头文件和函数库都了解的比较少,只是听起过,这次还是第一次使用,在这非常感谢我的舍友对我的指点,告诉我map和unordered_map的区别以及vector的用法。这次的作业让我学到了许多,也让我感受到了不小的压力,这次由于各种原因,做的比较简陋,希望在今后的学习中磨练技艺提高水平!