DPDK中的Cache优化
高负载下的网络数据包处理是一种I/O密集型工作负载。CPU,DMA,以及内存(Cache+DRMA)都会频繁访问。DPDK利用了一系列的Cache软件优化方法(cache预取,cache对齐,hugepage ,NUMA感知,DDIO)高效的减少访存开销以提升性能。本文将讲解这些方法的基本原理以及在DPDK中的应用。
1:Cache预取
Cache由于时间以及空间上的局部性能提高相当的性能,所谓的Cache预取,也就是预测数据并取入Cache,根据空间/时间局部性原理,参考当前的执行状态,软件提示等信息,在数据/指令被使用前取入Cache。在之后当数据/指令被使用时,就能快速从Cache中加载到CPU内部运算和执行。Cache预取又分为硬件预取与软件预取,这里将介绍早期的NetBurst构架的硬件预取以及DPDK使用的软件预取及指令。
硬件预取:
在早期Intel的NetBurst架构的处理器上各级cache都有相应的硬件预取单元,,以一级数据Cache的预取单元为例:
1):数据Cache预取单元:也叫基于流的预取单元(Streaming prefetcher)当程序以地址递增的方式访问数据,该单元会被激活,自动预取下一个Cache行的数据。
2)基于指令寄存器(Instruction Pointer,IP)的预取单元:该单元会检测指令寄存器的读取指令(Load),当该单元发现数据块的大小基本是固定的情况下,会自动预取下一块数据。
图片转自:http://linuxperformance.top/index.php/archives/109/
当在预取机制在内存中找到了块A,那么会预取连续的A+1,A+2,A+3,A+4。因为处理器消耗完A+1后会接着消耗A+2的,预取连续的块也叫做顺序预取。
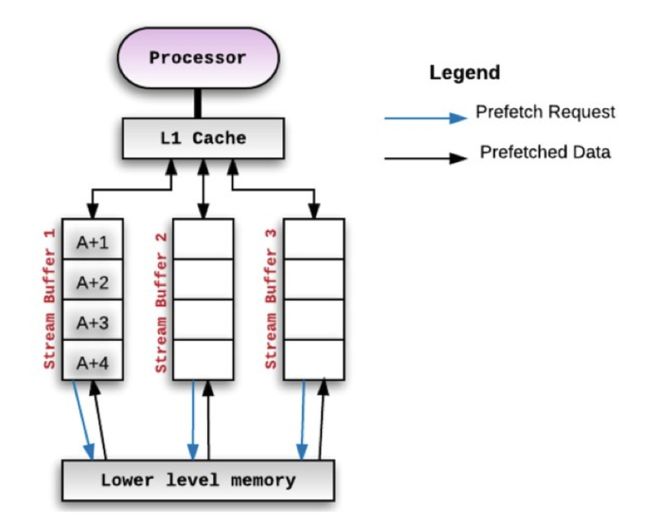
软件预取:
预取指令使软件开发人员在性能关键区域,把即将用到的数据从内存中加载到Cache,使得当前数据处理完毕后,即将用到的数据已经在Cache中,大大减小了从内存直接读取的开销,减少CPU的等待时间,提高性能。
预取指令表:
和缓存预取有关的指令:
指令 Description
PREFETCHT0 预取数据到所有级别的缓存,包括L0。
PREFETCHT1 预取数据到除L0外所有级别的缓存。
PREFETCHT2 预取数据到除L0和L1外所有级别的缓存。
PREFETCHNTA 预取数据到非临时缓冲结构中,可以最小化对缓存的污染。和PREFETCHT0 功能类似,但是数据在使用完一次后,Cache认为数据是可以淘汰出去的
Intel® C++ Compiler的Intrinsic等效方法:
void _mm_prefetch(char *p, int i)
从地址P处预取尺寸为cache line大小的数据缓存,参数i指示预取方式(_MM_HINT_T0, _MM_HINT_T1, _MM_HINT_T2, _MM_HINT_NTA,分别对应不同的预取指令0,1,2,A)。
DPDK的应用:
首先先看看DPDK的性能测试结果,转载至:http://www.cnblogs.com/hugetong/p/7126790.html
测试结果:
| 包长(byte) | pps | Mbps | seconds | socket数 | 收包physics core数 | 队列数 | 发包数 | 收包数 |
|---|---|---|---|---|---|---|---|---|
| 500 | 230000 | 960 | 1 | 1 | 24 | 10000000 | 10000000 | |
| 400 | 284000 | 950 | 1 | 1 | 24 | 10000000 | 10000000 | |
| 300 | 367000 | 940 | 1 | 1 | 24 | 10000000 | 10000000 | |
| 200 | 542000 | 952 | 1 | 1 | 24 | 10000000 | 10000000 | |
| 100 | 1039000 | 997 | 9.62 | 1 | 1 | 24 | 10000000 | 10000000 |
| 64 | 1483000 | 996 | 6.74 | 1 | 1 | 24 | 10000000 | 9907134 |
| 64 | 1483000 | 996 | 67.4 | 1 | 1 | 24 | 100000000 | 99147516 |
| 64 | 1483000 | 996 | 67.4 | 1 | 1 | 1 | 100000000 | 99671467 |
| 64 | 1483000 | 996 | 67.4 | 1 | 2 | 24 | 100000000 | 99252877 |
| 64 | 1483000 | 996 | 67.4 | 1 | 4 | 24 | 100000000 | 99084322 |
| 64 | 1483000 | 996 | 67.4 | 2 | 8 | 24 | 100000000 | 99177716 |
| 64 | 1483000 | 996 | 67.4 | 2 | 24 | 24 | 100000000 | 99110338 |
其实验环境如下
发包方式:192.168.20.205
发包工具:pktgen
发包网卡:i350
收包设备:1922.168.20.185
CPU:Intel(R) Xeon(R) CPU E5-2620 0 @ 2.00GHz
收包方式:网卡ixgeb驱动,单队列,promisc计数
收包网卡: 82599EB
传输链路:千兆RJ45网线直连
DPDK的一个处理器核每秒可以处理约33M个报文,大概30纳秒处理一个报文,在处理器频率2.7GHz的情况下,处理一个数据报文需要80个时钟周期。
一个数据报文到达网口后,会经历如下过程:
1)写接受描述符到内存,填充数据缓冲区指针,网卡接收到报文后就根据该地址把报文内容填进去。
2)从内存中读取接收描述符(到接收到报文时,网卡会更新该结构)(内存读),从而确认是否收到报文。
3)从接收描述符确认收到报文时,从内存中读取控制结构体的指针,再从内存中读取控制结构体,把从接收描述符中读取的信息填充到该控制结构体(内存读)。
4)更新接收队列寄存器,表示软件接收到了新的报文。
5)从内存读取报文头部(内存读),决定转发端口。
6)从控制结构体把报文信息填入到发送队列发送描述符中,更新发送队列寄存器。
7)从内存中读取发送描述符(内存读),检查是否有包被硬件发送出去。
8)如果有的话,则从内存中读取相应控制结构体(内存读),释放数据缓冲区。
可以看出处理一个报文的过程中,需要6次读取内存(上文(内存读))。换句话说要保证在80个时钟周期处理完一个报文DPDK就必须保证要读取的数据Cache命中,否则一旦Cache不命中,性能会严重下降。
在l3fwd-vf/main.c中使用预取的代码段
/ *
*从RX队列读取数据包
* /
for(i = 0; i n_rx_queue; ++ i){
portid = qconf-> rx_queue_list [i] .port_id;
queueid = qconf-> rx_queue_list [i] .queue_id;
nb_rx = rte_eth_rx_burst(portid,queueid,pkts_burst,MAX_PKT_BURST);
/ *预取第一个数据包* /
for(j = 0; j lookup_struct);
}
/ *转发剩余的预取包* /
for(; j lookup_struct);
}
|
将缓存行预取到所有缓存级别。
参数 p 预取地址
2:Cache一致性
当定义的数据结构或者分配了数据缓冲区之后,内存中就有了一个地址和其相对应,然后程序进行读写。在读的过程中,首先是内存加载到Cache,随后送到处理器内部的寄存器;在写操作的时候则是从寄存器送到Cache,最后由总线回写到内存。
这样会出现两个问题:
1)数据结构/数据缓冲区对应的Cache Line是否对齐?如果不是的话,即使数据区域小于Cache Line的话也会占用两个Cache Line;另外假如上一个CacheLine属于另一个数据结构且被另一个处理器核处理,数据如何同步呢?
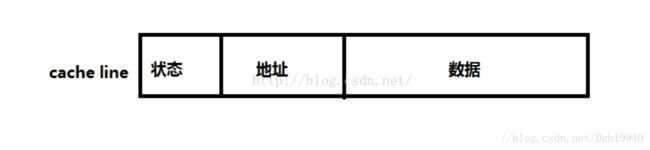
2)假设数据结构/缓冲区的起始地址是CacheLine对齐的,但是有多个核同时对该内存进行读写,如何解决冲突?
针对第一个问题
CacheLine对齐,DPDK中对很多结构体的定义是这样的:
struct lcore_conf {
uint16_t nb_rx_queue;
struct lcore_rx_queue rx_queue_list[MAX_RX_QUEUE_PER_LCORE];
uint16_t tx_queue_id[RTE_MAX_ETHPORTS];
struct buffer tx_mbufs[RTE_MAX_ETHPORTS];
struct ipsec_ctx inbound;
struct ipsec_ctx outbound;
struct rt_ctx *rt4_ctx;
struct rt_ctx *rt6_ctx;
} __rte_cache_aligned;
其中_rte_cache_aligned的定义是这样的
| struct rte_mempool_ops_table __rte_cache_aligned __rte_aligned(RTE_CACHE_LINE_SIZE) |
强制对齐缓存行。
定义在文件rte_memory.h的第62行。
#define RTE_CACHE_LINE_MIN_SIZE 64
#define __rte_cache_aligned __rte_aligned(RTE_CACHE_LINE_SIZE)
#define __rte_cache_min_aligned __rte_aligned(RTE_CACHE_LINE_MIN_SIZE)针对第二个问题
cache一致性问题:主要介绍总线窥探协议。即被X86,ARM,Power等架构广泛采用著名的MESI协议
MESI协议将cache line的状态分成modify、exclusive、shared、invalid,分别是修改、独占、共享和失效。
失效(Invalid)缓存段,要么已经不在缓存中,要么它的内容已经过时。为了达到缓存的目的,这种状态的段将会被忽略。一旦缓存段被标记为失效,那效果就等同于它从来没被加载到缓存中。
共享(Shared)缓存段,它是和主内存内容保持一致的一份拷贝,在这种状态下的缓存段只能被读取,不能被写入。多组缓存可以同时拥有针对同一内存地址的共享缓存段,这就是名称的由来。
独占(Exclusive)缓存段,和S状态一样,也是和主内存内容保持一致的一份拷贝。区别在于,如果一个处理器持有了某个E状态的缓存段,那其他处理器就不能同时持有它,所以叫“独占”。这意味着,如果其他处理器原本也持有同一缓存段,那么它会马上变成“失效”状态。
已修改(Modified)缓存段,属于脏段,它们已经被所属的处理器修改了。如果一个段处于已修改状态,那么它在其他处理器缓存中的拷贝马上会变成失效状态,这个规律和E状态一样。此外,已修改缓存段如果被丢弃或标记为失效,那么先要把它的内容回写到内存中——这和回写模式下常规的脏段处理方式一样。
对于两个Cache中存在备份时,只有部分状态是允许的。如下表所示横轴和纵轴分别表示两个Cache中的某个CacheLine的状态,且都映射到相同的内存块。如果一个CacheLine设置成M态或者E态,那么另一个只能设置为I态;如果一个CacheLine设置成S态,那么另一个可以为S或I态;如果一个设置为I态,另一个可以设置为任何状态。即:
| M | E | S | I | |
| M | false | false |
false |
true |
| E | false |
false |
false |
true |
| S | false |
false |
true |
true |
| I | true |
true |
true |
true |
MESI状态之间的迁移过程如下:
当前状态 |
事件 |
行为 |
下一个状态 |
I(Invalid) |
Local Read |
如果其他Cache没有这份数据,本Cache从该内存中取数据,Cache line状态变成E; 如果其他Cache有这份数据,且状态为M,则将数据更新到内存,本Cache再从内存中取数据,两个Cache的Cache line状态都变成S; 如果其他Cache有这份数据,且状态为S或者E,本Cache从内存中取数据,这些Cache的Cache line状态都变成S。 |
E/S |
Local Write |
从内存中取数据,在Cache中修改,状态变成M;如果其他Cache有这份数据,切状态为M,则要先将数据更新到内存; 如果其他Cache有这份数据,则其他Cache的Cache line状态变成1 |
M |
|
Remote Read |
既然是invalid,别的核的操作与它无关 |
I |
|
Remote Write |
既然是invalid,别的核的操作与它无关 |
I |
|
E(Exclusive) |
Local Read |
从Cache中取数据,状态不变 |
E |
Local Write |
修改Cache的数据,状态为M |
M |
|
Remote Read |
数据和其他核共用,状态变成了S |
S |
|
Remote Write |
数据被修改,本Cache line不能再使用,状态变成I |
I |
|
S(Shared) |
Local Read |
从Cache中取数据,状态不变 |
S |
Local Write |
修改Cache中的数据,状态变成M,其他核共享的Cache line状态变成I |
M |
|
Remote Read |
状态不变 |
S |
|
Remote Write |
数据被修改,本Cache line不能再使用,状态变成I |
I |
|
M(Modified) |
Local Read |
从Cache中取数据,状态不变 |
M |
Local Write |
修改Cache中的数据,状态不变 |
M |
|
Remote Read |
这行数据被写到内存中,使其他核能使用到最新的数据,状态变成S |
S |
|
Remote Write |
这行数据被写到内存中,使其他核能使用到最新的数据,由于其它核会修改这行数据,状态变成I |
I |
DPDK如何保证Cache一致性
DPDK解决方案很简单,首先避免多个核访问同一个内存地址或者数据结构。每个核尽量避免与其他核共享数据,从而减少因为错误的数据共享导致的Cache一致性开销。
举两个DPDK避免Cache一致性的例子:
例子1:
通过数据结构定义。对于某些数据结构给每个核都单独定义一份,如DPDK官方的l3fwd为例:
struct lcore_conf {//保存lcore的配置信息
uint16_t n_rx_queue; //接收队列的总数量
struct lcore_rx_queue rx_queue_list[MAX_RX_QUEUE_PER_LCORE];//物理端口和网卡队列编号组成的数组
uint16_t tx_queue_id[RTE_MAX_ETHPORTS]; //发送队列的编号组成的数组
struct mbuf_table tx_mbufs[RTE_MAX_ETHPORTS];//mbuf表
lookup_struct_t * ipv4_lookup_struct; //实际上就是struct rte_lpm *
#if (APP_LOOKUP_METHOD == APP_LOOKUP_LPM)
lookup6_struct_t * ipv6_lookup_struct;
#else
lookup_struct_t * ipv6_lookup_struct;
#endif
} __rte_cache_aligned;struct lcore_conf lcore[RTE_MAX_LCORE]_rte_cache_aligned;以上的数据结构 “struct lcore_conf”和上边一样总是CacheLine对齐,而定义数组“lcore[RTE_MAX_LCORE]”中RTE_MAX_LCORE为系统中最大核的数量。DPDK对每一个核编号,这样核n就只需要访问lcore[n],避免了多个核访问同一结构体。
例子2:
在多核的情况下,有可能多个核访问同一个网卡的接收/发送队列,这样也会引起Cache一致性的问题。
DPDK就会为每个核都准备一个单独的接收/发送队列。如图。

该技术称为RSS(Receive Side Scaling),是一种能够在多处理器系统下使接收报文在多个CPU之间高效分发的网卡驱动技术。
3.TLB和大页
准确来讲TLB不是DPDK专用的技术,TLB属于对处理器架构的优化。
下面转载http://blog.csdn.net/divlee130/article/details/47104241
Hugepages 机制
大内存页指的是为包处理的缓冲区缓冲区分配更大的大内存池,利用大内存页的主要好处当然是通过利用大内存页提高内存使用效率。可以得到明显的性能提高,因为需要更少的页,更少的TLB( Translation Lookaside Buffers),减少了虚拟页地址到物理页地址的转换时间。如果不使用大内存页机制的话,TLB的命中率会降低,反而会降低性能。大内存页最好在启动的时候进行分配,这样可以避免物理空间中有太多的碎片,提高发包的效率。普通的页大小为4KB, 默认的大内存页的大小为2MB,也可以设置其他的大内存页大小,可以从CPU的标识中看出支持哪种大内存页,如果有 “pse”的标识,说明支持2M的大内存页。 如果有“pdpe1gb”的标识,说明支持1G的大内存页,如果64位机建议使用1GB的大页。
如何使用大内存页
如果已经配置好了大内存页机制,就可以让DPDK利用大内存页的机制了。可以输入如下的命令
mkdir /mnt/huge
mount -t hugetlbfs nodev /mnt/huge
在运行程序 的时候,最好把分配给大页的所有空间都利用起来。如果DPDK的程序在运行的时候传递了-m 或者–socket-mem的参数,大内存页的分配在启动的时候会自动加载。如果传递给程序的内存页数量比程序要求的要少,也就是内存页不够用,程序将会中止。
TLB
其中TLB(Translation Lookaside Buffer)指的是旁路转换缓冲,或称为页表缓冲,是一个存放着页表缓存(虚拟地址到物理地址的转换表)的内存管理单元,用于改进虚拟地址到物理地址转换速度。X86体系的系统内存里存放了两级页表,第一级页表称为页目录,第二级称为页表。由于“页表”存储在主存储器中,查询页表所付出的代价很大,由此产生了TLB。
TLB是内存里存放的页表的缓存,那么它里边存放的数据实际上和内存页表区的数据是一致的,在内存的页表区里,每一条记录虚拟页面和物理页框对应关系的记录称之为一个页表条目(Entry),同样地,在TLB里边也缓存了同样大小的页表条目(Entry)。
1:TLB在X86体系的CPU里的实际应用最早是从Intel的486CPU开始的,在X86体系的CPU里边,一般都设有如下4组TLB:
第一组:缓存一般页表(4K字节页面)的指令页表缓存(Instruction-TLB);
第二组:缓存一般页表(4K字节页面)的数据页表缓存(Data-TLB);
第三组:缓存大尺寸页表(2M/4M字节页面)的指令页表缓存(Instruction-TLB);
第四组:缓存大尺寸页表(2M/4M字节页面)的数据页表缓存(Instruction-TLB);
2:TLB命中和TLB失败
如果TLB中正好存放着所需的页表,则称为TLB命中(TLB Hit);
如果TLB中没有所需的页表,则称为TLB失败(TLB Miss)。
当CPU收到应用程序发来的虚拟地址后,
首先到TLB中查找相应的页表数据,如果TLB中正好存放着所需的页表,则称为TLB命中(TLB Hit)
接下来CPU再依次看TLB中页表所对应的物理内存地址中的数据是不是已经在一级、二级缓存里了,若没有则到内存中取相应地址所存放的数据。
4.英特尔数据直接I / O技术 (DDIO技术)
Intel DDIO是一种平台技术,它可以提高I / O数据处理效率,以便从I / O设备传输数据和消耗数据。 借助英特尔DDIO,英特尔\以太网服务器适配器和控制器可直接与处理器高速缓存进行通信,而无需通过系统内存。 在所有基于英特尔®至强™处理器E5的服务器和工作站平台上默认启用英特尔DDIO。这种技术使得外部网卡和CPU通过LLCCache直接交换数据,绕过了内存这个相对较慢的部件。增加了CPU处理报文的速度,减少了网络报文在服务器端的延迟。同时,因为网络报文直接存储在LLC Cache,在英特尔至强E5处理器把LLCCache容量提高到20MB。
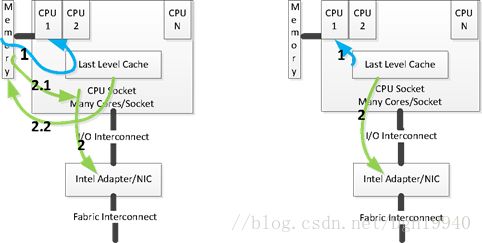
左图是没有DDIO技术的网卡读数据处理流程
1):处理器更新把报文和控制结构体。由于分配的缓冲区在内存中,所以会触发一次cache不命中,处理器把内存读取到Cache,更新控制结构体和报文信息。通知NIC读取报文。
2):当NIC接收到启动传输操作的通知时,它首先读取控制结构并随后读取分组数据。 由于之前处理器刚把该缓冲区从内存中读取到Cache并做了更新,很有可能Cache还没有把更新的内容写回内存。因此,当NIC发起一个对内存的读请求时,很有可能这个请求会发送到Cache系统中,Cache系统会把数据写回内存,然后内存控制器再把数据写到pCI总线。因此,一个读内存操作会产生多次内存读写。
右边是有DDIO技术的网卡读数据处理流程
1):处理器更新报文和控制结构体。这个步骤和没有DDIO的技术类似,但是由于DDIO的使用,处理器会开始就把数据预取到Cache。
2):NIC收到有报文需要传递到网络上的通知后,通过PCI总线把控制结构体好的报文到NIC内部。利用DDIO,I/O访问一个直接将Cache的内容送到PCI总线。减少Cache写回时等待的时间。

左图是没有DDIO技术的网卡写数据处理流程
1):报文和控制结构体通过PCI总线送到指定内存中。如果该内存恰好缓存在Cache中,则需要等待Cache先把内容写回内存中,然后才能把报文和控制结构体写回到内存。
2):运行在处理器上的驱动程序或者软件得到通知收到报文,去内存中读取,Cache不命中。
右边是有DDIO技术的网卡写数据处理流程
1):报文和控制结构体通过PCI总线直接送到Cache中。
有两种情况(a)如果内存恰好缓存在Cache中,则直接在Cache中更新内容,覆盖原有内容
(b)如果该内存没有缓存在Cache中则在最后一级Cache中分配一块区域,并相应更新Cache表。
2):运行在处理器上的驱动或者软件被通知到有报文到达,其生产一个内存读操作,由于该内容已经在Cache中,因此直接从Cache中读。
5.NUMA系统及其感知
NUMA是起源于AMD Opteron的微架构,同时被英特尔Nehalem架构采用。在这个架构中,处理器和本地内存之间拥有更小的延迟和更大的带宽,和SMP系统相比,NUMA系统访问本地内存的带宽更大,延迟更小,但是访问远程内存的成本较高。DPDK利用了以下策略在NUMA系统中实现。
1)Per-core memory。一个处理器上有多个(core),per-core memory是指每个核都有属于自己的内存,即对于经常访问的数据结构,每个核都有自己的备份。
2)本地设备本地处理。及用本地的处理器、本地的内存来处理本地设备上产生的数据。如果有一个PCI、设备在node0上,就用node0上的核来处理设备,处理该设备用到的数据结构和数据缓冲区都从node0上分配。
注:此篇文章部分引用自《深入浅出DPDK》中的观点。