深度学习mxnet::线性回归(简单版本)
线性回归(简单版本)
仅作为记录,不作详解
#导入
from mxnet import autograd,nd
from mxnet import gluon#生成数据
#模型:y=Xw+b+ϵ
#设置特征数、样本数
num_inputs=2
num_examples=1000
#设置真实的权值w和偏移b
true_w=[2,-3.4]
true_b=4.2
#随机生成 两列1000行的数据,features的每一行是一个长度为2的向量 (相当于X)
features=nd.random.normal(scale=1,shape=(num_examples,num_inputs))
#标签生成 ,labels的每一行是一个长度为1的向量 (相当于Y)
labels=true_w[0]*features[:,0]+true_w[1]*features[:,1]+true_b
labels+=nd.random.normal(scale=0.01,shape=labels.shape)
#输出看一下
print(features[0], labels[0]) 
#读取数据
batch_size=10
dataset=gluon.data.ArrayDataset(features,labels)
data_iter=gluon.data.DataLoader(dataset,batch_size,shuffle=True)
#看一下随机生成的小样本集
for data,label in data_iter:
print(data,label)
break 
#定义模型
#Sequential()容器,可以不断加神经网络的层数
net=gluon.nn.Sequential()
#加入一个dense层,即全连接层
#唯一参数为输出节点的个数,线性回归中为1
#不需要输入节点的个数,这个会自动赋值
net.add(gluon.nn.Dense(1))
#初始化模型参数
net.initialize()#定义损失函数
square_loss=gluon.loss.L2Loss()
#优化算法,这里用梯度下降
trainer=gluon.Trainer(
net.collect_params(),"sgd",{'learning_rate':0.1})#开始训练,与0到1建立版本差不多
epochs=5
batch_size=10
for e in range(epochs):
total_loss=0
for data,label in data_iter:
with autograd.record():
output=net(data)
loss=square_loss(output,label)
loss.backward()
trainer.step(batch_size) #走一步,即训练--更新参数一次
#这里就直接将每次计算的loss加起来
total_loss+=nd.sum(loss).asscalar()
#最后再将总的loss/总样本数得到均值
#这里写法与《线性回归从0到1建立》有所不同,但实际上做的是一个事情
print("epoch %d,average loss:%f"%(e,total_loss/num_examples)) 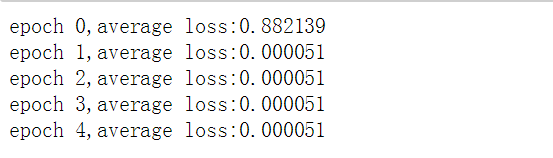
#查看训练后的参数
dense=net[0]
print("model w is:",dense.weight.data())
print("true w is:",true_w)
print("model b is:",dense.bias.data())
print("true b is:",true_b) 