SparkSql整合Hive
需要Hive的元数据,hive的元数据存储在Mysql里,sparkSql替换了yarn,不需要启动yarn,需要启动hdfs
首先你得有hive,然后你得有spark,如果是高可用hadoop还得有zookeeper,还得有dfs(hadoop中的)
我这里有3台节点node01,node02,node03
ps:DATEDIFF(A,B)做差集
node01
先copy hive的hive-site.xml到spark 的config
cp hive-site.xml /export/servers/hive-1.1.0-cdh5.14.0/conf/hive-site.xml /export/servers/spark-2.0.2/conf/
然后在spark config目录scp到其它节点
scp hive-site.xml node02:$PWD
scp hive-site.xml node03:$PWD

cp /export/servers/hive-1.1.0-cdh5.14.0/lib/mysql-connector-java-5.1.38.jar /export/servers/spark-2.0.2/jars/
将mysql驱动拷贝至其他节点spark目录下
首先进入到spark/jars目录
cd /export/servers/spark-2.0.2/jars/
拷贝(我配了免密登录,并且有主机名映射ip)
scp mysql-connector-java-5.1.38.jar node02:$PWD
scp mysql-connector-java-5.1.38.jar node03:$PWD

因为待会要在hdfs的文件中测试,所以需要启动dfs,不启动yarn
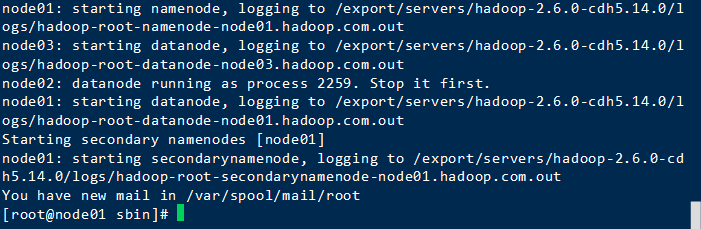
进入hadoop/sbin目录后,启动
./start-dfs.sh
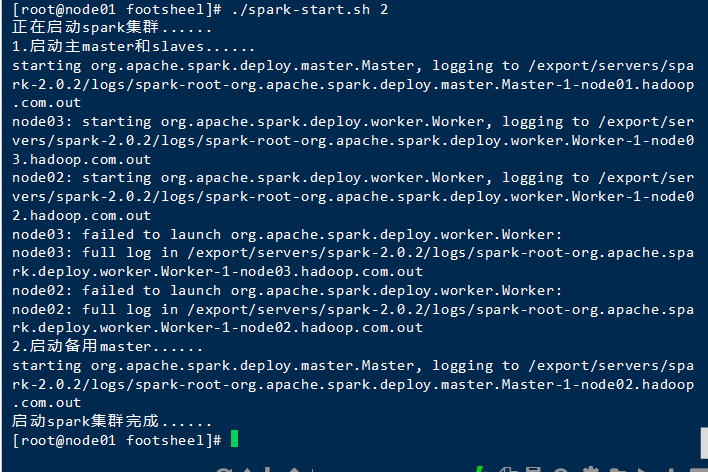
启动spark集群(我把他们封装到了一个脚本里=>如果需要,请点击我下载待定)
脚本启动
./spark-start.sh 2
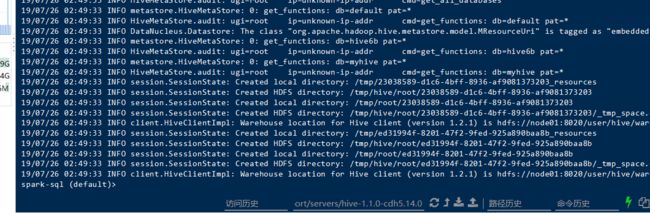
测试
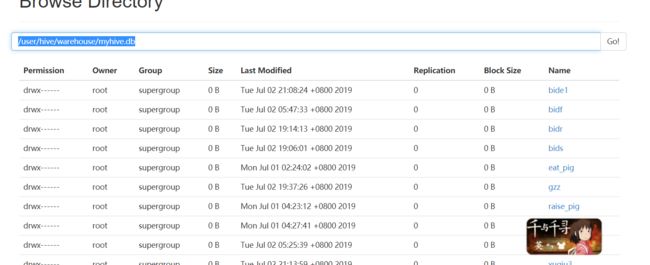
spark-sql \ --master spark://node01:7077 \ --executor-memory 1g \ --total-executor-cores 2 \ --conf spark.sql.warehouse.dir=hdfs://node01:8020/user/hive/warehouse/myhive.db
失败了
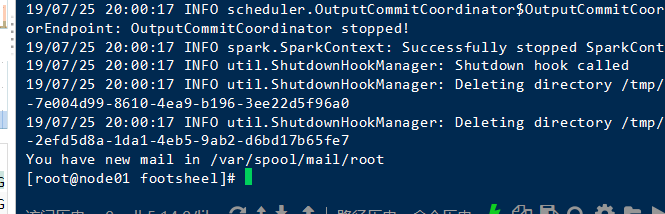

这行代码错误的原因是,因为之前我和impala整合过,但是我未启动impala。
解决方案
进入node01
hive/conf下打开hive-site.xml
注释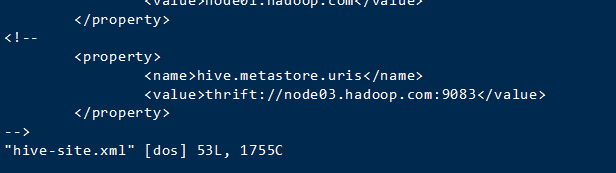
重新启动
spark-sql \ --master spark://node01:7077 \ --executor-memory 1g \ --total-executor-cores 2 \ --conf spark.sql.warehouse.dir=hdfs://node01:8020/user/hive/warehouse/myhive.db
成功