python自然语言处理入门(NLTK)
参考
开篇
这边主要讲一些nltk的日常使用,对于我来说算是一种复习吧,希望也给大家一些入门的启发,关于nlp的一些python库,我日后会慢慢介绍,前面已经出现了一些中文处理的库,后期我想把他们放到一起讲讲。关于nltk的安装,这边就不多讲了,一条命令就可以下载,语料库在nltk_data可能比较难下载,有兴趣的可以给我留言索要。这边太大了,我无法上传。
数据
数据的主要来源是亚马逊的商品评论,这边的话我使用的是电影的评论数据集,下载下来的数据是json格式的,但不是纯粹的json格式,这边的话我还是写了一个简单的处理代码把它处理成其他语言也能读的json格式以供大家参考,可以会跟网页上的代码有些不同,但是本质是一样的。
import json
data = open('data.json','r')
my_data = []
for i in data:
a = eval(i)
my_data.append(a)
with open('my_data.json','w') as f:
json.dump(my_data,f)我依旧采用的是list的格式。每一条都是相应的评论信息,这边的数据样式如下

这边我就不使用全部的评论了,就抽取出其中一种商品的评论
In [8]: reviews = []
In [9]: for i in mydata:
...: if i['asin'] == '0439893577':
...: reviews.append(i)
...:
In [10]: len(reviews)
Out[10]: 17总共是17条。
统计词频
##统计词频
tokens = texts.split()
freq = nltk.FreqDist(tokens)
freq.plot(20,cumulative=False)这里画出前二十词频的单词的图,不是词云图
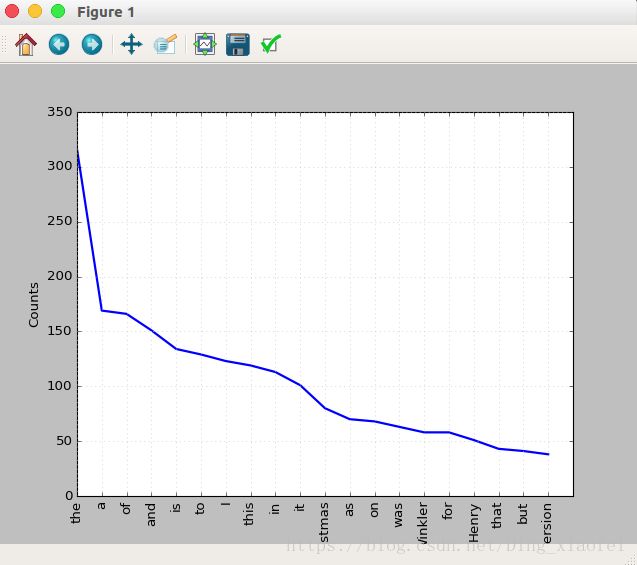
你会发现它里面全都是一些意义不大的单词
去除停用词
##剔除停用词
tokens = [c.lower() for c in tokens] ##停用词词表都是小写的,这边做一下处理,把单词都变成小写的
tokens = [c for c in tokens if c not in stop_word]
freq = nltk.FreqDist(tokens)
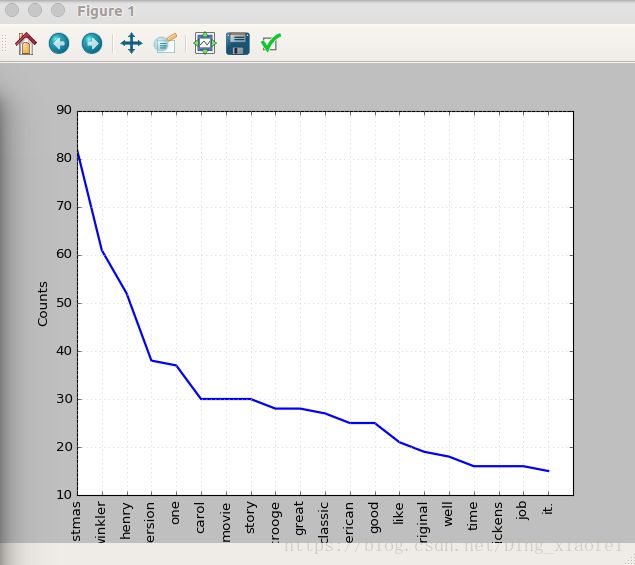
freq.plot(20,cumulative=False)这时画出的图就靠谱点啦
分词/分句
刚刚我们就是用split去分了一下词
分句
from nltk.tokenize import sent_tokenize
from nltk.tokenize import word_tokenize
sentences = sent_tokenize(texts)
tokens = word_tokenize(texts)同义词处理
In [7]: from nltk.corpus import wordnet
In [8]: syn = wordnet.synsets('happy')
In [9]: syn
Out[9]:
[Synset('happy.a.01'),
Synset('felicitous.s.02'),
Synset('glad.s.02'),
Synset('happy.s.04')]
In [10]: print(syn[0].definition())
enjoying or showing or marked by joy or pleasure
In [11]: print(syn[0].examples())
['a happy smile', 'spent many happy days on the beach', 'a happy marriage']获取同义词
In [12]: synonyms = []
...: for syn in wordnet.synsets('happy'):
...: for lemma in syn.lemmas():
...: synonyms.append(lemma.name())
...:
In [13]: synonyms
Out[13]: ['happy', 'felicitous', 'happy', 'glad', 'happy', 'happy', 'well-chosen']
反义词
In [2]: from nltk.corpus import wordnet
In [3]: antonyms = []
In [4]: for syn in wordnet.synsets("small"):
...: for l in syn.lemmas():
...: if l.antonyms():
...: antonyms.append(l.antonyms()[0].name())
...: print(antonyms)
...:
['large', 'big', 'big']词干提取
In [5]: from nltk.stem import PorterStemmer
In [6]: stemmer = PorterStemmer()
In [7]: stemmer.stem('working')
Out[7]: 'work'
In [8]: stemmer.stem('worked')
Out[8]: 'work'单词变体还原
单词变体还原类似于词干,但不同的是,变体还原的结果是一个真实的单词。不同于词干,当你试图提取某些词时,它会产生类似的词:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem('increases'))
out:increas现在,如果用NLTK的WordNet来对同一个单词进行变体还原,才是正确的结果:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('increases'))
out:increase结果可能会是一个同义词或同一个意思的不同单词。
有时候将一个单词做变体还原时,总是得到相同的词。
这是因为语言的默认部分是名词。要得到动词,可以这样指定:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))实际上,这也是一种很好的文本压缩方式,最终得到文本只有原先的50%到60%。
结果还可以是动词(v)、名词(n)、形容词(a)或副词(r):
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))
print(lemmatizer.lemmatize('playing', pos="n"))
print(lemmatizer.lemmatize('playing', pos="a"))
print(lemmatizer.lemmatize('playing', pos="r"))词干和变体的区别
from nltk.stem import WordNetLemmatizer
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
print(stemmer.stem('stones'))
print(stemmer.stem('speaking'))
print(stemmer.stem('bedroom'))
print(stemmer.stem('jokes'))
print(stemmer.stem('lisa'))
print(stemmer.stem('purple'))
print('----------------------')
print(lemmatizer.lemmatize('stones'))
print(lemmatizer.lemmatize('speaking'))
print(lemmatizer.lemmatize('bedroom'))
print(lemmatizer.lemmatize('jokes'))
print(lemmatizer.lemmatize('lisa'))
print(lemmatizer.lemmatize('purple'))
out:
stone
speak
bedroom
joke
lisa
purpl
---------------------
stone
speaking
bedroom
joke
lisa
purple词干提取不会考虑语境,这也是为什么词干提取比变体还原快且准确度低的原因。
个人认为,变体还原比词干提取更好。单词变体还原返回一个真实的单词,即使它不是同一个单词,也是同义词,但至少它是一个真实存在的单词。
如果你只关心速度,不在意准确度,这时你可以选用词干提取。
(待续)