在几个月前写过一个帖子来解决一个临床师弟的问题。
迷人的多参数批量函数mapply
那个帖子让我很得意,因为我把一个需要11小时完成的任务,用11s来完成(极大的可能是,我在熊的心里增加了分量)。但是也留下了两个笑柄。
第一个是用mapply去生成多参数下的重复,大材小用了。
unlist(mapply(rep,1:10,1:10))
[1] 1 2 2 3 3 3 4 4 4 4 5 5 5 5 5 6 6 6 6 6 6 7 7 7 7 7 7 7 8
[30] 8 8 8 8 8 8 8 9 9 9 9 9 9 9 9 9 10 10 10 10 10 10 10 10 10 10
上次上课的时候,不小心读了一下rep这个函数的文档,人家文档里面清楚地写作,我们支持多参数重复。
rep(1:4, 2)
rep(1:4, each = 2) # not the same.
rep(1:4, c(2,2,2,2)) # same as second.
rep(1:4, c(2,1,2,1))
也就是说他可以方便地实现这个操作
rep(1:10,1:10)
[1] 1 2 2 3 3 3 4 4 4 4 5 5 5 5 5 6 6 6 6 6 6 7 7 7 7 7 7 7 8
[30] 8 8 8 8 8 8 8 9 9 9 9 9 9 9 9 9 10 10 10 10 10 10 10 10 10 10
这个事情写在了这个帖子里面
用R语言中的sample函数来抽上一次的奖。
第二个笑柄是,我为了解决师弟那个填充空白项的问题
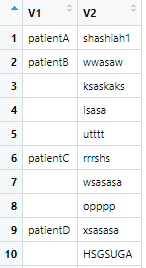
专门写了一个函数取解决,结果,有读者在留言里面给出了excel 3秒就解决的方案。

确实很高效,但是我心里有点落寞,觉得被比下去了哈,当时(一会就知道我为什么用当时)小洁的留言给我了希望

结果她这个汉堡吃了3个多月,今天她告诉我,tidyr这个包里面的fill函数可以干这个事情。
举个例子来看看,现在有这样一个数据
df <- data.frame(people=c("A","","","","B","","C","",""),
group=c("basal","","lunimalA","","lunimalB","","Her2","",""),
stage=c("III","","","II","IV","","","I",""),
levels=letters[1:9])
df
里面很多空缺,都是要补的。
people group stage levels
1 A basal III a
2 b
3 lunimalA c
4 II d
5 B lunimalB IV e
6 f
7 C Her2 g
8 I h
9 i
至少有三列都是这个情况,其实这时候,excel也可以一样的做,我们看看fill的用法
首先我们需要把空白数据变为NA(这也是小洁说的,可能是大家都会碰到的问题)
df[df==""] <- NA
df
people group stage levels
1 A basal III a
2 b
3 lunimalA c
4 II d
5 B lunimalB IV e
6 f
7 C Her2 g
8 I h
9 i
如果想把people那一列补齐,可以这样做
library(tidyr)
fill(df,people)
people group stage levels
1 A basal III a
2 A b
3 A lunimalA c
4 A II d
5 B lunimalB IV e
6 B f
7 C Her2 g
8 C I h
9 C i
确实很方便,当然要把其他两列补齐也是可以的,只要用逗号隔开就可以
fill(df,people,group,stage)
people group stage levels
1 A basal III a
2 A basal III b
3 A lunimalA III c
4 A lunimalA II d
5 B lunimalB IV e
6 B lunimalB IV f
7 C Her2 IV g
8 C Her2 I h
9 C Her2 I i
到了这里,这个操作也不一定有excel快,那还有什么优势呢?
我在想,R语言真正厉害的地方应该是这两个:
第一,掌握了R语言基本的技能后(大概就是500行那个文档中技能),无论碰到什么情况,都可以通过编程来解决,能以一抵百,缓解了我大量焦虑,虽然我不知道fill这个函数,但是我并不慌张,他并不影响我最终解决问题。
第二,R语言作为编程语言,他可以实现批量操作,假如,这里有100个数据,都需要这个操作,对于R语言来说,做一件事情和做100件是差不多的,写个循环就可以搞定。
这就是我喜欢他的地方,我只熟练掌握了一门语言,但是解决了科研中所有需要批量处理的事情,这是很愉悦的经历。
关于批量我写过以下的帖子
8秒完成2万个基因的生存分析,人人都可以!
又是神器!基于单基因批量相关性分析的GSEA
R语言学习路上的忆苦思甜
神奇的lapply
Reduce函数实现多个数据框批量合并
今天吃了个火锅,这几天奄奄一息的病态消失了,很开心。