运行环境:win10 64位 py 3.6 pycharm 2018.1.1
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets,cross_validation,ensemble,naive_bayes
def load_data_classification():
digits = datasets.load_digits()
return cross_validation.train_test_split(digits.data,digits.target,test_size=0.25,random_state=0)
def test_RandomForestClassifier(*data):
X_train,X_test,y_train,y_test=data
clf = ensemble.RandomForestClassifier()
clf.fit(X_train,y_train)
print("Traing Score:%f"%clf.score(X_train,y_train))
print("Tesing Score:%f"%clf.score(X_test,y_test))
X_train,X_test,y_train,y_test=load_data_classification()
test_RandomForestClassifier(X_train,X_test,y_train,y_test)
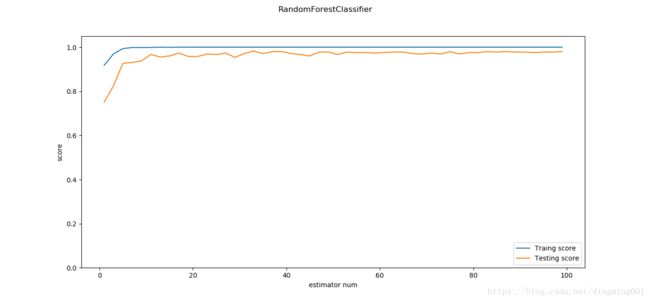
def test_RandomForestClassifier_num(*data):
X_train, X_test, y_train, y_test = data
nums = np.arange(1,100,step=2)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for num in nums:
clf = ensemble.RandomForestClassifier(n_estimators=num)
clf.fit(X_train,y_train)
training_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
ax.plot(nums, training_scores, label='Traing score')
ax.plot(nums, testing_scores, label='Testing score')
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc='lower right')
ax.set_ylim(0, 1.05)
plt.suptitle("RandomForestClassifier")
plt.show()
X_train,X_test,y_train,y_test=load_data_classification()
test_RandomForestClassifier_num(X_train,X_test,y_train,y_test)
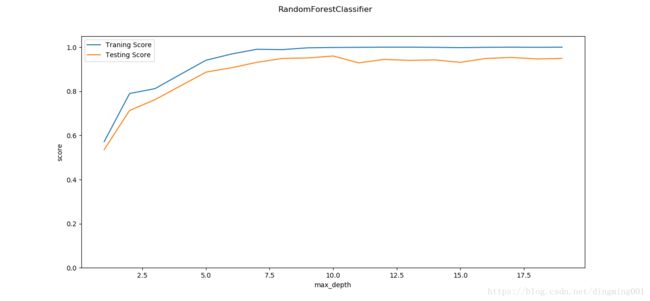
def test_RandomForestClassifier_max_depth(*data):
X_train, X_test, y_train, y_test = data
maxdepths = np.arange(1,20)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
traing_scores = []
testing_scores = []
for maxdepth in maxdepths:
clf = ensemble.RandomForestClassifier(max_depth=maxdepth)
clf.fit(X_train,y_train)
traing_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
ax.plot(maxdepths,traing_scores,label='Traning Score')
ax.plot(maxdepths,testing_scores,label='Testing Score')
ax.set_xlabel("max_depth")
ax.set_ylabel("score")
ax.legend(loc='best')
ax.set_ylim(0,1.05)
plt.suptitle('RandomForestClassifier')
plt.show()
X_train,X_test,y_train,y_test = load_data_classification()
test_RandomForestClassifier_max_depth(X_train,X_test,y_train,y_test)
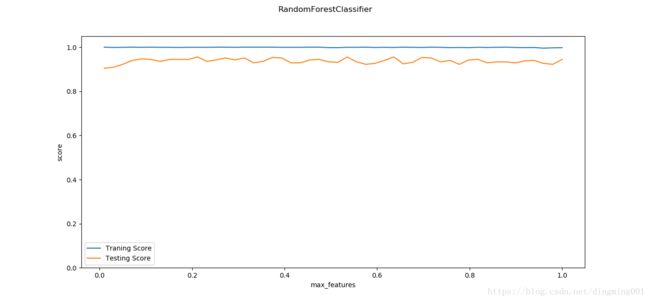
def test_RandomForestClassifier_max_features(*data):
X_train, X_test, y_train, y_test = data
max_features = np.linspace(0.01,1.0)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
traing_scores = []
testing_scores = []
for max_feature in max_features:
clf = ensemble.RandomForestClassifier(max_features=max_feature)
clf.fit(X_train,y_train)
traing_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
ax.plot(max_features,traing_scores,label='Traning Score')
ax.plot(max_features,testing_scores,label='Testing Score')
ax.set_xlabel("max_features")
ax.set_ylabel("score")
ax.legend(loc='best')
ax.set_ylim(0,1.05)
plt.suptitle('RandomForestClassifier')
plt.show()
X_train,X_test,y_train,y_test = load_data_classification()
test_RandomForestClassifier_max_features(X_train,X_test,y_train,y_test)
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets,cross_validation,ensemble,naive_bayes
def load_data_regression():
diabetes = datasets.load_diabetes()
return cross_validation.train_test_split(diabetes.data,diabetes.target,test_size=0.25,random_state=0)
def test_RandomForestRegressor(*data):
X_train,X_test,y_train,y_test=data
regr = ensemble.RandomForestRegressor()
regr.fit(X_train,y_train)
print("Traing Score:%f"%regr.score(X_train,y_train))
print("Tesing Score:%f"%regr.score(X_test,y_test))
X_train,X_test,y_train,y_test=load_data_regression()
test_RandomForestRegressor(X_train,X_test,y_train,y_test)
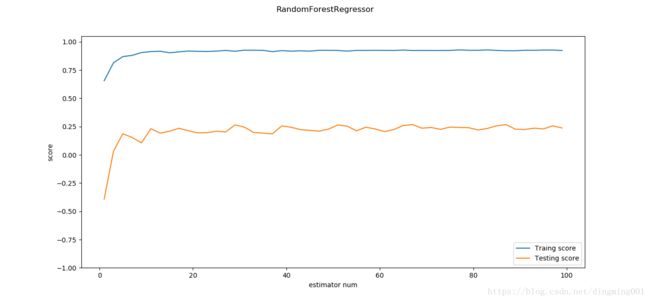
def test_RandomForestRegressor_num(*data):
X_train, X_test, y_train, y_test = data
nums = np.arange(1,100,step=2)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for num in nums:
regr = ensemble.RandomForestRegressor(n_estimators=num)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(nums, training_scores, label='Traing score')
ax.plot(nums, testing_scores, label='Testing score')
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc='lower right')
ax.set_ylim(-1, 1.05)
plt.suptitle("RandomForestRegressor")
plt.show()
X_train,X_test,y_train,y_test=load_data_regression()
test_RandomForestRegressor_num(X_train,X_test,y_train,y_test)
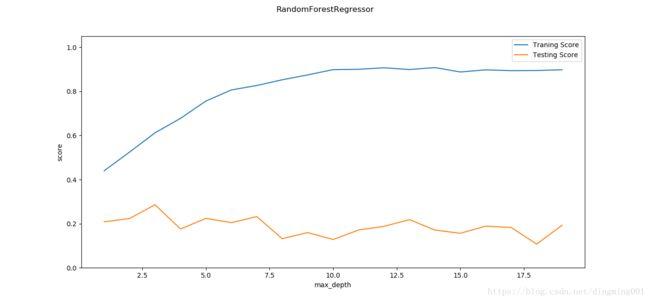
def test_RandomForestRegressor_max_depth(*data):
X_train, X_test, y_train, y_test = data
maxdepths = np.arange(1,20)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
traing_scores = []
testing_scores = []
for maxdepth in maxdepths:
regr = ensemble.RandomForestRegressor(max_depth=maxdepth)
regr.fit(X_train,y_train)
traing_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(maxdepths,traing_scores,label='Traning Score')
ax.plot(maxdepths,testing_scores,label='Testing Score')
ax.set_xlabel("max_depth")
ax.set_ylabel("score")
ax.legend(loc='best')
ax.set_ylim(0,1.05)
plt.suptitle('RandomForestRegressor')
plt.show()
X_train,X_test,y_train,y_test = load_data_regression()
test_RandomForestRegressor_max_depth(X_train,X_test,y_train,y_test)
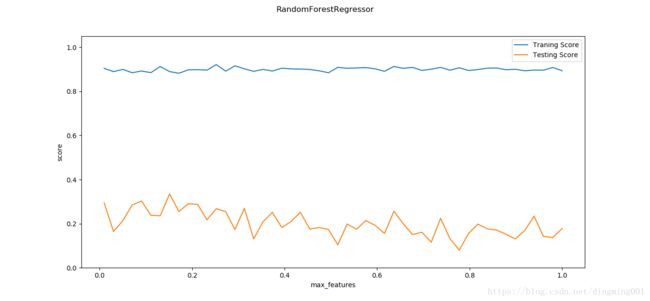
def test_RandomForestRegressor_max_features(*data):
X_train, X_test, y_train, y_test = data
max_features = np.linspace(0.01,1.0)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
traing_scores = []
testing_scores = []
for max_feature in max_features:
regr = ensemble.RandomForestRegressor(max_features=max_feature)
regr.fit(X_train,y_train)
traing_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(max_features,traing_scores,label='Traning Score')
ax.plot(max_features,testing_scores,label='Testing Score')
ax.set_xlabel("max_features")
ax.set_ylabel("score")
ax.legend(loc='best')
ax.set_ylim(0,1.05)
plt.suptitle('RandomForestRegressor')
plt.show()
X_train,X_test,y_train,y_test = load_data_regression()
test_RandomForestRegressor_max_features(X_train,X_test,y_train,y_test)