版权申明:本文为博主窗户(Colin Cai)原创,欢迎转帖。如要转贴,必须注明原文网址 http://www.cnblogs.com/Colin-Cai/p/7507317.html 作者:窗户 QQ/微信:6679072 E-mail:[email protected]
数学中有一个重要概念,就是抽象。由数学开始发展的计算机科学,自然也离不开抽象。计算机语言、编程范式都为抽象提供了工具,函数、回调、泛型、算子、类……
以下从两个问题开始,描述了一大类抽象。
问题
这一篇文章我们先引入两个问题。
狼、羊、白菜问题:
一个农夫带着一匹狼、一只羊、一筐白菜这三样东西,需要过一条河。河上有条船,农夫每次渡河要么是自己一个人,要么最多带三样东西中的其中一样,多带了船要沉。农夫当然是要把三样东西都带过河,但是有一个限制条件,如果农夫不在旁边,狼是要吃羊的,羊是要吃白菜的,这是要绝对避免的。农夫怎么一个过程,才能把狼、羊、白菜都运过河呢?
倒油问题:
有两个没有刻度的杯子,一个杯子倒满是9升,另一个杯子倒满是4升。请问如何利用这两个杯子倒出6升油?
思考
这两道题目说来应该历史比较悠久。特别是第一道题目我印象非常深刻,在我小的时候就见过这个题目,当时我父亲拿着我的小船玩具和三颗不一样的扣子、药丸给我讲了这个问题的解答。
我在这里之所以把这两个表面上看起来八竿子打不到一起的问题放在一起,自然是因为这两个问题实际上具有某些方面的一致性。而我们今天要讲的就是如何把这两个问题抽化从而提取共性,从更一般的角度上去解决这两个问题乃至更多的问题。
一般来说,这样的题目会出现在孩子的奥数甚至脑筋急转弯里。然而,我从来不认为一把钥匙开一把锁从而满是套路的教育有什么真正的用处。
状态和原子
所谓抽象,就是从各个问题中去掉不重要的成分,只保留与问题解答相关的最少信息,然后再从多个问题中提取共性。问题中不重要的成分很多,比如狼羊白菜问题中羊的种类、白菜的重量、农夫划船的速度,倒油问题中杯子的材质、倒油的速度,等等,此类信息都是与问题的解答没什么关系,都是不需要考虑的。
然后就是提取共性。
对于这两个问题,数学建模首先做的第一个抽象就是状态和原子。
我们把这两个问题都看成是状态的转换,而推动状态转换的是不可分割的原子操作。
对于狼羊白菜问题,过程中不断渡船改变的只是两岸的物品,可以认为状态是当前河两岸的物品(包括狼、羊、白菜,以及农夫),使用字母代替更加方便一点,狼用W代替,羊用S代替,白菜用C代替,农夫用F代替,那么最开始的状态为FWSC||,如果第一步农夫带着羊渡船,之后的状态则为WC||FS,其中两条竖线代表一条河应该比较形象化,当然,符号长什么样其实并不重要。
然后我们把每次渡船看成原子操作,如果第一步农夫带着羊渡船,就记作FS->
对于倒油问题,我们把9升的杯子称为A杯,把4升的杯子称为B杯。反复的倒来倒去改变的只是两个杯子的油量,从而可以认为状态是两个杯子的油量组成的序偶。比如(5,4)就是A杯有5升油,B杯有4升油。
原子操作则为每一次倒油,因为杯子没有刻度,我们可以想到的是:
倒满A杯,记作A<-;
倒满B杯,记作B<-;
倒空A杯,记作A->;
倒空B杯,记作B->;
再者,A杯和B杯也可以互相倒,分别记作A->B和B->A,倒油直到一只杯子倒空或者另外一只杯子倒满为止。
另外,再重申一次,思想最重要,符号不重要!
图的遍历
有了上面状态和原子的抽象,就有了图的抽象,其中图的顶点就是各个状态,而图的边则为各个原子操作。
而原问题就抽象为图的路径寻找问题,从而本质上还是图的遍历问题。
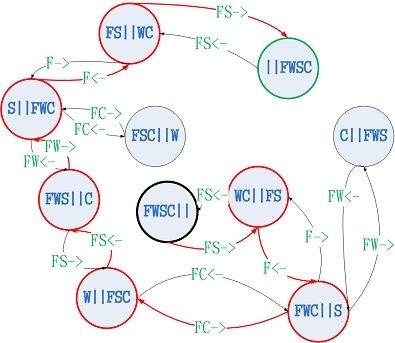
上图就是狼羊白菜问题的状态图,红线经过的是全部过河的最短路径。
既然要讲遍历,还是以下面这个简单一点的图为例子比较好。

广度遍历
为了找到达到目的状态的最短路径,可以选择广度遍历。
对于广度遍历,如果只是遍历出图的各个顶点,学过数据结构的应该都知道,只需要一个队列,先把最初的顶点入列,之后每次顶点出列之前先把该顶点直接指向的没有遍历过的顶点入队,如此重复直到队列为空。当然,我们需要记录已遍历过的顶点。
对于上面的图,广度遍历队列的变换可能如下(每次都是入列和出列一起,右边一列记录当前已经遍历过的顶点):
[1] {1}
[2 3 4] {1,2,3,4}
[3 4 5] {1,2,3,4,5}
[4 5] {1,2,3,4,5}
[5 6] {1,2,3,4,5,6}
[6] {1,2,3,4,5,6}
[] {1,2,3,4,5,6}
但是,我们不要忘了,我们目的是在搜索到合适的顶点时得到路径,而上述队列里没有任何路径的信息,从而队列里的每个元素只放顶点是不合适的,还要把顶点的路径也放在一起。比如上述如果要找到6并给出6的路径,应该是
[(1,)] {1}
[(2,1),(3,1),(4,1)] {1,2,3,4}
[(3,1),(4,1),(5,1->2)] {1,2,3,4,5}
[(4,1),(5,1->2)] {1,2,3,4,5}
[(5,1->2),(6,1->4)] {1,2,3,4,5,6}
如此,当找到6这个顶点的时候,会知道路径是1->4->6
深度遍历
深度遍历是另外一种遍历方法。深度遍历使用一个栈来记录压栈的路径,压栈是路径往前加一个顶点,而退栈是路径最前端减少一个节点。既然栈记录的是路径,而我们的目的是路径,那么我们至少不需要和广度遍历那样,对于每个顶点都再记录完整路径,因为从栈底到这个顶点就是路径。(但是我们实际需要的路径可能是过程中的原子操作,所以实际需求的时候也可以再做一个栈,用来压原子操作)
大多数人会记得,深度遍历依然需要标志来记录已经遍历过的顶点。实际上,这个不是必须的。
我们考虑一般情况的回溯,我们除了栈之外并没有这样的标志来记录以往遍历过的顶点,也就是遍历的过程中永远只知道栈里的顶点遍历过而需要规避,不过有一个重要信息,就是每次退栈回溯的时候我们会知道刚才退出的顶点,如果我们对于每个顶点,它所指向的所有的顶点存在一个排序,那么回溯是可以终止的。
对于上面的这个图,我们不记录以往遍历过的顶点回溯的过程如下:
[1]
[1 2]
[1 2 3]
[1 2 3 4]
[1 2 3 4 6]
[1 2 3 4] (6)
[1 2 3] (4)
[1 2 3 6]
[1 2 3] (6)
[1 2] (3)
[1 2 5]
[1 2] (5)
[1] (2)
[1 3]
[1 3 4]
[1 3 4 6]
[1 3 4] (6)
[1 3] (4)
[1 3 6]
[1 3] (6)
[1] (3)
[1 4]
[1 4 6]
[1 4] (6)
[1] (4)
上面虽然可以完成遍历,但是顶点可能不只一次被遍历。
于是,我们还是记录下节点访问标记,那么上图遍历则如下:
[1] {1}
[1 2] {1,2}
[1 2 3] {1,2,3}
[1 2 3 4] {1,2,3,4}
[1 2 3 4 6] {1,2,3,4,6}
[1 2 3 4] {1,2,3,4,6}
[1 2 3] {1,2,3,4,6}
[1 2] {1,2,3,4,6}
[1 2 5] {1,2,3,4,6,5}
[1 2] {1,2,3,4,6,5}
[1] {1,2,3,4,6,5}
当然,假如我们的目的是找到顶点6,那么到[1 2 3 4 6]时,1->2->3->4->6就是路径。
其他问题
太多太多的问题其实都可以归结到这篇文章所说的内容来建模,甚至于,prolog语言都是基于回溯这样的模型设计的。
当然,以下这样的迷宫问题自然可以很好的对接于这篇文章的内容,不过这个似乎看上去太过于明显了一点。

我再举一个更加复杂一点的游戏——华容道。这个游戏曾经出现在江苏电视台的《最强大脑》第五季中,以下是一个简化版的。
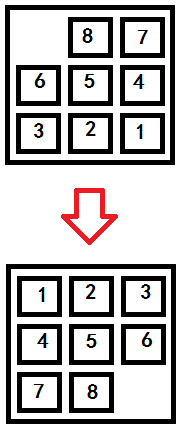
我们把9个位置的数字(如果是空则为0)序列当成状态,比如上面的状态为(0,8,7,6,5,4,3,2,1),下面的状态为(1,2,3,4,5,6,7,8,0)。
而每次移动则是原子操作,可以用所移动的数字来代表。
有了状态和原子的抽象,华容道问题就可以归结于上述一样的抽象,从而可以统一解决。
代码
抽象的最终还是为了解决问题,程序的解决当然需要代码。
如下链接文件用Python做了本章的抽象,以及狼羊白菜、倒油、迷宫、华容道各自的实现:
![]()