摘要:来自物联网(IoT)传感器和全球定位系统(GPS)智能设备的海量数据流正涌入数据库系统进行进一步的处理和分析。从新鲜数据和历史数据中实时检索的能力被证明是智能制造和智能城市中利用这些数据流实现现实应用的关键。在本文中,我们提出了一个简单而有效的分布式解决方案来实现每秒数百万次元组插入和毫秒级的临时范围查询处理。为此,我们提出了一种新的数据分区方案,该方案利用了工作负载特性,避免了昂贵的全局数据合并。此外,为了解决吞吐量瓶颈,我们采用了基于模板的索引方法,在相对稳定的传入元组分布上跳过不必要的索引结构调整。为了使数据插入和查询处理并行化,我们提出了一种高效的调度机制和有效的负载均衡策略,以工作负载感知的方式充分利用计算资源。在综合工作负载和实际工作负载上,我们的解决方案的性能始终比最先进的开源系统高出至少一个数量级。
Introduction
随着物联网[21]传感器和位置信息[25]智能设备产生的高速数据的爆炸式增长,对高吞吐量数据摄取和实时数据检索的需求迅速上升。它也是支持智能制造和智能城市应用程序的最关键的数据处理功能之一,以便系统用户能够根据需要快速检索历史数据和最新数据。在图1中,我们给出了一个实时索引和查询处理的示例应用程序,其中分析系统试图实时分析网络流量,并以非常高的速率在一家电信公司的主干网络上收集样本。流数据上的典型查询从指定的IP范围和给定的时间间隔内检索所有示例包,以便识别网络攻击的潜在风险和查明网络故障。因此,对于系统来说,在响应延迟较低的情况下支持时间和范围查询的同时,保持洪泛样本在到达时立即可见是至关重要的。
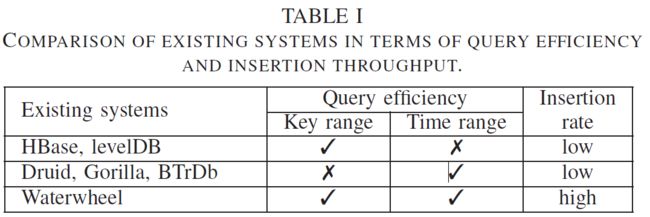
上述所有应用程序都要求系统支持极高的元组插入吞吐量,以及对指定域上的时间范围查询的实时响应。表一回顾了最先进的系统对我们的目标应用程序的性能保证。键值存储,如HBase[17]和levelDB[24],将数据元组组织为排序映射,并支持高效的键范围查询。然而,对于非键属性(如时态查询)的范围查询不是一等公民,因此不能有效地执行。此外,虽然这些系统通过使用LSM-tree[33]而不是传统的B+ tree来减少更新的开销,但是更新仍然需要与历史数据合并,这导致了大量的数据合并开销,限制了插入吞吐量。时间序列数据库,如Druid[47]、Gorilla[36]和BTrDb[2],是为实时时间序列数据摄取和具有时间约束的低延迟查询而设计的,但是由于缺少辅助范围索引,它们无法在非时间属性上提供有效的范围查询。
在本文中,我们提出了一个简单而有效的分布式解决方案Waterwheel,它支持每秒超过一百万元组的实时索引和具有键和时间范围约束的低延迟查询。据我们所知,这是第一个同时支持高效时间和范围查询和极高吞吐量数据插入的框架。Waterwheel面临的主要挑战是高效地在时间域和关键域上索引数据元组,同时保持新传入的元组在查询到达时立即可见。我们通过利用现实世界中工作负载的特性来解决这个问题,即几乎有序的到达和缓慢的分布演化。首先,流元组到达系统的顺序几乎与它们生成的顺序相同。例如,在图1中的动机示例中,示例包的收集几乎遵循示例包的时间戳上的顺序。其次,传入元组的分布通常不会随时间发生显著变化。给定各种数据源,例如图1中由智能设备、监视摄像头和智能建筑生成的网络数据包,样本数据包在IP地址域上的分布通常是缓慢而平缓的。
基于以上观察和直觉,我们完全重新设计了面向海量数据流的实时索引和查询处理体系结构。Waterwheel背后的关键思想是利用实际工作负载的特性,通过物理分区并将传入的数据维护为不同时间和键范围的独立数据块。在每个数据块中,都构建了一个模板B+树索引结构,以支持高效的元组插入和数据检索。通过使用该模板,B+树无需调整内部节点的结构,节省了索引维护开销,实现了高性能。这种简单的双层数据索引方案使系统能够根据不同的工作负载轻松地重新伸缩。为了提高系统的性能和鲁棒性,我们设计了模板更新方法和动态密钥划分机制,使系统能够适应工作负载动态。为了充分利用查询处理中的计算资源,提出了一种同时保持负载均衡和数据局部性的查询调度算法。总的来说,Waterwheel在性能上比现有的开源解决方案有了显著的提高。
1)我们提出了一种通用的双层索引体系结构,用于每秒百万次元组插入和毫秒的时间和键范围查询处理。
2)设计了一种增强的基于模板的B+树,显著降低了索引维护开销,实现了高并发性。
3)设计分布式查询调度算法和负载均衡机制,充分利用集群中的计算资源。
4)我们用合成的和真实的工作负载来评估我们的原型系统,并与文献中最先进的解决方案相比,展示了显著的性能改进。
II. PRELIMINARY
数据模型、查询和假设
我们关注的场景是,数据元组以极高的速率连续流进系统,并发出实时查询,以便在特定的键和时间范围内动态检索最近和历史数据。元组d=
水车运行在一个由本地网络连接的商用pc集群上。在图3中,我们展示了系统的总体架构,它由许多独立执行的组件组成。Dispatcher服务器接收连续传入的数据元组,并将它们分派到索引服务器。索引服务器在索引结构中重组传入的数据元组,并定期将接收到的元组刷新到外部分布式文件系统中的数据块。元数据服务器维护系统的状态,包括dispatcher服务器的分区模式和用于查询处理的数据块的属性信息。根据查询和元数据信息的选择条件,查询协调器将用户查询转换为一组独立的子查询,并在索引服务器(用于检索新输入的数据)和/或查询服务器(用于检索历史数据)之间并行执行这些查询。查询协调器聚合来自所有子查询的结果,并将它们作为查询结果返回给用户。
