先给出github上的代码链接以及项目需求
1.项目概述
这个项目的需求可以概括为:对记事本(txt)文件进行单词的词频统计和排序,排序结果以指定格式输出到默认文件中,并要求能够快速地完成整个统计和结果输出功能。乍一看,这个功能实现起来十分简单,基本上就是遍历一遍文件,对提取出来的单词按照词频排个序就搞定了。但是要是考虑到性能问题,那还需要多动动脑筋。下面附上这项目的PSP表格。
| PSP2.1 | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) | PSP2.1 | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) | |
|---|---|---|---|---|---|---|---|---|
| Planning | 计划 | 5 | 5 | Development | 开发 | 310 | 340 | |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 5 | · Analysis | · 需求分析 (包括学习新技术) | 30 | 30 | |
| · Design Spec | · 生成设计文档 | 20 | 20 | |||||
| Reporting | 报告 | 52 | 52 | · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 10 | |
| · Test Report | · 测试报告 | 30 | 30 | · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 60 | |
| · Size Measurement | · 计算工作量 | 2 | 5 | · Design | · 具体设计 | 60 | 60 | |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 | · Coding | · 具体编码 | 90 | 60 | |
| · Code Review | · 代码复审 | 10 | 10 | |||||
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 90 | |||||
| 合计 | 367 | 397 |
因为我个人数据结构学得比较好,所以我做这个项目的时候很顺利,各种链表、散列写起来也得心应手,于是编码阶段花费的时间比预计的还要少。(后来知道室友全程使用C++自带的向量类、容器类,根本就不用自己动手写内部实现,我自己倒是哼哧哼哧写了好几个数据结构。只好感叹自己还是比室友少算了一步,哈哈哈)而在制定代码规范的时候,我们花了一个小时去研究Google提供的C++编码规范,就感觉开辟了新世界的大门,很多我之前认为很规范的代码,都被这个规范“一棍打死”!最后,在单元测试的时候,由于出现了未曾预料的BUG,也耽误了不少时间。
2.大体思路
这个项目的核心任务可以分为两部分,一是在文本中识别出不同的单词,二是统计所有单词并将这些单词按照词频进行排序。我们将我们的程序大致可以分成四个模块:输入模块,状态模块,统计模块,输出模块。具体的需求分析文档可以在这里找到
在文本中识别出不同的单词
识别文本中的单词,我使用的是一个有限状态机模型。

假如文本中没有连词符 '-' ,那么问题十分简单,只有两个状态,一个是单词内部,一个是单词外部,相互转换的条件则是在单词内部的状态下检测到一个非字母字符,或者在单词外部的状态下检测到一个字母字符。

当文本中出现了连词符,那么情况会复杂一些,不过仍然不会太复杂。我们增加了一个临界状态,当读入一串字母之后突然检测到了一个连词符,则会进入到这个状态。这个状态不会持续,一旦读入下一个字符,就会根据它是字母或者非字母字符,进入到单词内部或单词外部的状态。
使用这一个3状态7过程的状态机模型,可以完美地满足需求。
统计所有单词并将这些单词按照词频进行排序
这个部分就复杂一些。我们的基本思路是使用一个双向链表来存储所需要的数据,具体来说,每个结点记录了一个单词和这个单词的词频,从链表到链表尾词频依次递减,相同词频字母字母靠前的靠近链表头。每次遇到一个单词,我们先去查找有没有对应于这个单词的结点,如果有,就让这个单词的词频加一,否则在链表的尾部添加一个这个单词的结点。然后不论哪种情况,都要对该单词对应的结点进行调整,使它在同一词频的几个其他单词中,根据首字母大小排序,处于正确的位置。最后从链表头开始,依次遍历一百个结点,就能找到词频最高的一百个单词。
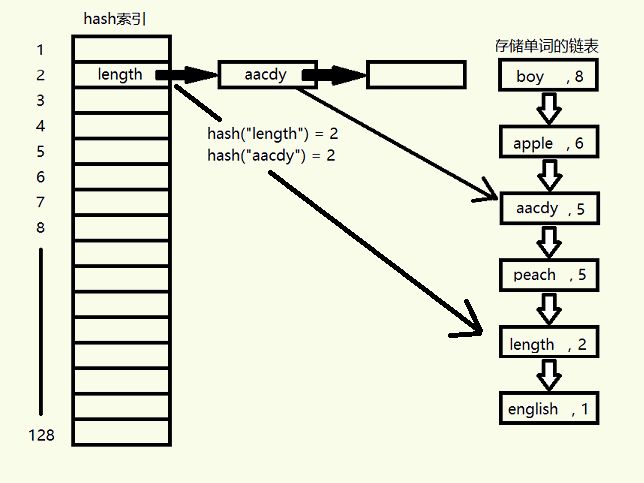
这个方法简单粗暴,但效率低下。两个原因,一个是结点交换位置时必须依次在相邻位置进行交换,这个缺点是对于链表这种数据结构来说无法克服;另一个原因是查找单词时必须从链表头开始遍历。我们考察了很多种数据结构,但是没有一种数据结构能够既快速地处理排序,又能快速地查找结点。机智的我决定给这个链表,根据单词内容构建一个哈希索引。对于每一个单词(实际上是一个字符数组),我们可以对所有字符进行求和,然后通过模除得到哈希索引,通过哈希索引来查找结点,大大提高了查找的速度。为了提高哈希函数的性能,我们选取128作为模,因为任何一个数模除128都可以写成它和127进行按位与(&)运算,与运算的速度远远高于除法。
引入了哈希索引的链表看起来像是这样的:
3.代码框架与接口
整体思路现在已经十分明晰了,在统计词频的时候,我们依次读入文件中的字符,根据状态迁移的路径,决定是否到了一个单词的末尾,是否将单词添加进入我们的数据结构。
WordState wordState; //用于记录当前的状态
processType process; //这个变量用于记录状态迁移的路径
char c = 0;
do {
c = in.get();
//这个函数可以根据读入字符进行状态转移,并返回转移过程
process = wordState.stateTransfer(c);
switch (process) {
//根据不同状态做出不同的响应
case PROCESS_23:
//临界状态->单词外部,删去最后一个连词符,单词数++
break;
case PROCESS_13:
//单词内部->单词外部,单词数++
break;
case PROCESS_33:
//单词外部-单词外部,放弃这个非字母字符
break;
default:
//其他情况:储存这个字母字符
}
} while (c != EOF);为了记录单词及其词频,我们建立了一个WordList类,其中包括一个链表和这个链表的索引。最后,我们得到一个关于程序的大体框架,这个大体框架的代码可以在这里看到。其中,最重要的两个接口在下面给出:
processType WordState::stateTransfer(char c); //根据当前状态及下一个字母,返回状态转移的方向
void WordList::addWord(char word[]); //向WordList中添加一个单词,如果已经有这个单词,则它的词频+1状态迁移函数十分重要,但之前我们说过,这个状态模型非常简单,只有三个状态七条路径,这里就不详细说明了,你可以去github上看到具体的实现。添加单词的函数就比较繁琐了,它涉及到:利用单词计算哈希索引、根据哈希索引查找结点,对结点的位置进行调整。具体的代码在下面给出。
int p_index = Hash(word); //利用单词计算哈希索引
WordIndex* pIndex = index[p_index];
while (pIndex != nullptr) {
Word *pWord = pIndex->pWord;
if (!strcmp(word, pWord->word)) { //在哈希索引对应的几个单词中,找到我们需要找到的单词
pWord->num++; //如果找到了,首先把这个单词的词频+1
//接着根据词频调整单词的位置
Word *qWord = pWord->previous;
while (qWord->num < pWord->num) {
if (qWord == pWordHead)
return;
shiftWord(pWord);
qWord = pWord->previous;
}
//然后再在同一词频下根据单词在字典中的顺序调整位置
while (strcmp(qWord->word, pWord->word) > 0) {
if (qWord->num > pWord->num) return;
shiftWord(pWord);
qWord = pWord->previous;
}
return;
}
pIndex = pIndex->next;
}当然,上述代码只给出了根据哈希索引成功找出结点的情况,对于首次遇见的单词,无法根据哈希索引找到它,那我们就在链表的末尾增加一个新的结点以记录这个单词,然后为它建立一个索引。具体的代码可以在github中找到。
4.单元测试
WordList类是我认为最有风险的一个类,它用于实现这个项目最最最主要的功能:词频统计。而为了实现这个功能,它又要调用各种子函数(如哈希函数),从函数调用图来看,它的入度和出度总和是最高的。具体的测试用例设计表格在下面给出。完整的测试用例表格可以在我们的github上看到。
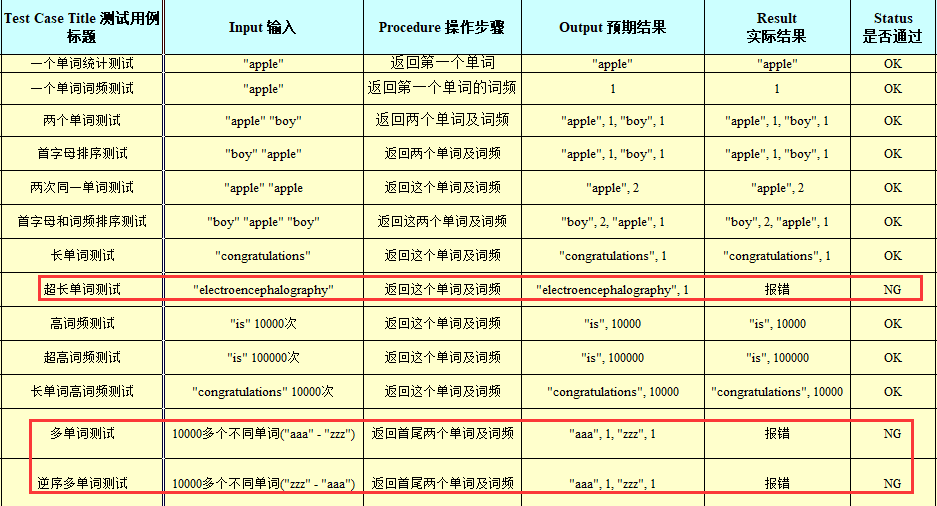
13个测试用例,从最简单的对一至两个单词进行的功能测试,到最后面对高频词、长单词、超多种类单词进行性能测试,基本把能想到的部分都测了。
其中,第八个超长单词测试,我们使用了一个22个字母组成的单词进行测试,注意到我们代码中为单词设置的最大长度是20,所以这里产生了错误。修改的方法很简单,重新设定单词最大长度即可。
第12和第13个测试用例出错是我没有想到的,这个测试用例无法正常运行,提示说这是一个非法堆指针错误。

一开始我以为是堆空间不够了(因为从aaa-zzz总共有一万多个不同的单词,意味着链表有一万多个结点),我就调大了堆空间,但是没有奏效。我就只好硬着头皮使用断点调试,发现其实链表建立很成功,出错的是在测试执行完毕之后,释放空间的那段代码。为了少些几行代码,在释放链表空间的时候,我采取了简单粗暴的递归方式:在释放一个结点之前,首先调用next结点的析构函数,然后再释放自己。这就是一个递归的过程。
//错误的示例
~Word() {
delete next;
next = nullptr;
}但是,现在我们总共有一万多个链表结点,也就是要递归调用10000多层!!!栈空间肯定不够了。要怪只能怪我偷懒,后来我老老实实改成了用一个for循环释放结点,测试就成功通过了。
//正确的示例
Word *p = pWordHead;
while (p != nullptr) {
pWordHead = p->next;
delete p;
p = pWordHead;
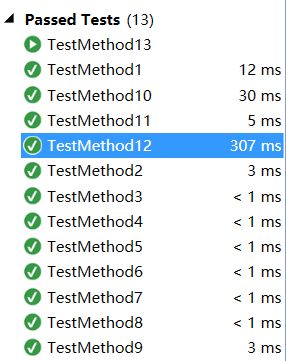
}成功的单元测试脚本运行结果如下图。一个值得注意的现象是,用例12和用例13分别是顺序多单词测试和逆序多单词测试。在顺序多单词测试中,所有的单词都按照字典顺序进入链表,不需要做多余的排序,因此仅仅用了307毫秒就完成了对一万七千多个单词的词频统计。相比之下,用例13每个单词都按照字典逆序进入链表,这意味着每个单词都要进行一次排序(而且这个排序很慢,是一个节点一个节点地挪动,在前面也解释了,这是链表的硬伤),最后用了24秒才完成统计,是用例12的80倍!如果不使用链表,而是使用向量的话,可以考虑使用先统计后排序的策略,向量排序是很快的,它有封装好的快速排序的算法,可惜我既然已经走上了链表的道路,再推翻重写就有点不太愿意了。
总体来说,我负责的部分测试质量还是不错的,它全方位地考虑了各种情况,包括极限情况,而且也确实发现并解决了问题。对于被测模块(WordList类),我认为在测试过后,它的质量也十分的好:首先它能正确完成需求。其次,对于各种高频词、长单词、多单词都能够处理。只有对于极端情况(用例13),才会有些吃力,不过这个情况简直太极端了,正常的用户绝对不会遇到。
5.静态检查
使用静态测试是为了确保代码符合行业规范。在这个项目中,我们参考了Google给出的C++风格指南,并且对所有的代码进行了检查。Google给出的代码规范涉及的范围十分全面,从头文件、命名空间,一直到if……else……语句,到注释、空格、花括号,都给出了详尽的规范。我们本来想使用Google提供的所有规范,但后来失败了。一方面,有些规范我们不是很能理解,例如Google对于命名空间提出的规范,我们并不能完全地理解;另一方面,规范中的某些内容我们并不认可,比如对于变量的命名,Google推荐使用下划线分隔变量中的每个单词,而我们认为变量命名使用变量首字母小写、单词首字母大写,中间不使用空格分隔的方式也很好(而且这是面向对象程序设计老师推荐的命名方式)。
综上,最后我们仅使用了头文件、注释、格式上的规范对整个项目进行代码检查。
进行代码检查,我们使用的是一款也是由Google提供的代码检查工具cpplint。这款工具十分方便,对于一款配置好Python环境的电脑来说,只要将被测文件和脚本文件cpplint.py放在同一目录下,然后使用控制台运行Python脚本(被测文件路径作为参数),就能够快速地进行测试。对于Python3环境来说,需要对脚本进行一些修改,修改的方法在这里给出。
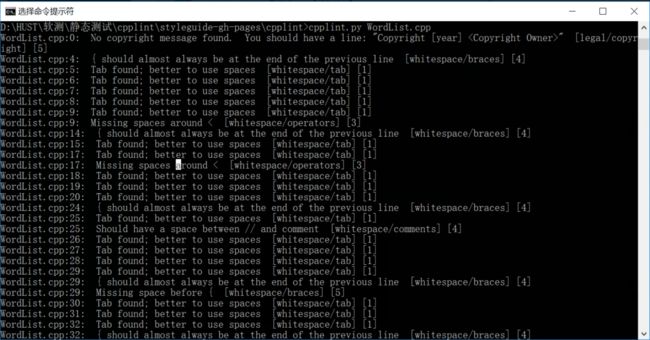
我们的代码主要存在的问题就是格式,以及一点点头文件的问题。Google规定代码中所有用Tab制表符的地方都得使用空格,每个花括号之前都要有一个空格,以及对于if……else……语句来说,只要一个分支使用了花括号,那么所有的分支都要使用花括号,而且else分支必须和前后两个花括号处在同一行。对于注释,注释内容和双斜杠之间必须要留有一个空格(我也不知道为什么)。
// 符合Google 规范的代码
if ((c >= 'a') && (c <= 'z')) {
state = INNERWORD;
} else if (c == '-') {
if (state == INNERWORD)
state = CRITICAL;
else
state = OUTERWORD;
} else {
state = OUTERWORD;
}对于头文件而言,每个头文件都必须给出版权声明,还要进行#define保护。
// Copyright[2018]
#ifndef WCPRO_WORDLIST_H_
#define WCPRO_WORDLIST_H_
// 在这里添加代码...
#endif // WCPRO_WORDLIST_H_ 不得不说,Google给出的规范真的是面面俱到。然而真的要实现它的所有规范我也不是很愿意。就拿#define保护来说吧,这三行代码,在VS编译器下,只需要用 #pragma once 这一条指令就可以实现。对于if……else……分支的种种规范,我觉得都很多余。我个人本身也有一套自己的格式规范,我的if语句看起来本来也相当顺眼,非常整齐,改成Google规范后反而看着不舒服了。
这个项目大部分代码都是我和Levey写的,就我们所采用的那部分Google规范而言,我们实际上都是差不多的。原因就是,在VS编辑器中,调整代码格式可以很方便地使用一组组合键来完成(Ctrl+K 和 Ctrl+F),使用这个组合键,可以快速地将我们的代码调整至VS的代码规范。对于没有采用Google规范的那部分(即,变量命名),我自认为胜他一筹,我对于变量命名,都会确实使用变量的含义命名,如pIndex, wordState等等,不会使用形如c, p, q 这样的简单的单字母来命名。(在小组讨论之前,我单独和Levey同学讨论了代码,提前把命名问题告诉了他,在静态检查之前就已经改正了。)
6.性能测试和优化
I/O优化
为了寻找一份一个在内容上能造成足够压力的txt文档,我在网上找了以《巴黎圣母院》为首的四部英文名著,把它们整合成一份大小超过5M的txt文档。这份文档也会在github中提供(文件非常大,需要下载下来才能看到)。
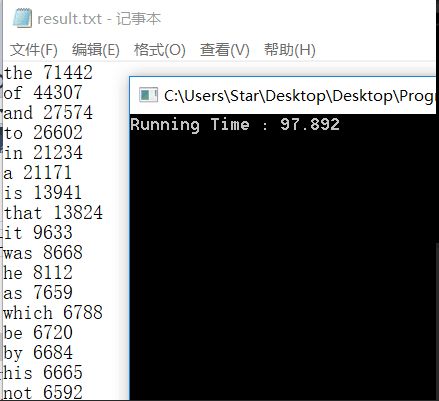
第一次测试是很惨烈的,我运行了数秒钟之后发现程序没反应,特地加了断点去看。确保程序的确在正确地运行后,我又足足等了一分多钟才运行出结果。而我室友跑出来的程序只要两秒钟(虽然室友的是错的)。
这个运行时间让我十分惊讶,首先我决定对I/O进行优化。我们的程序读取文件采用的是逐字符读取的方式,边读文件边处理,那么一个文件里面字符越多,我们的I/O次数就越多。于是,我们对此进行了改进。先将文件的所有内容一次性读到内存中,然后就可以关闭文件,从内存中逐字符判断了。
// 改进的I/O代码
ifstream in(fileName, ios::binary);
if (!in) { // Determine if the file exists
cout << fileName << "file not exists" << endl;
return nullptr;
}
filebuf *pbuf = in.rdbuf();
// 调用buffer对象方法获取文件大小
long size = pbuf->pubseekoff(0, ios::end, ios::in);
if (size == 0) {
cout << fileName << "file is empty" << endl;
in.close();
return nullptr;
}
pbuf->pubseekpos(0, ios::in);
// 分配内存空间
char *ch = new char[size + 1];
pbuf->sgetn(ch, size);
ch[size] = '\0';
in.close();在进行了这一优化后,运行时间减少了5秒(是的,只减少了5秒而已)。
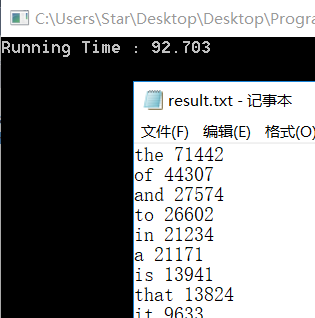
排序优化
作为一个执着追求优质程序的人,我并不满足于这短短5秒的缩短。并且我们在前面提到,链表是一个对排序极其不友好的数据结构。想必剩下的时间开销就是链表造成的。终于,我决定彻底放弃链表。注意到需求中说,只要对前100个单词进行排序。所以我觉得在统计单词的时候不去做任何的排序,在统计完之后,首先采用选择算法找出前一百个单词,然后再进行排序。创建一个优先队列(最小堆)来做这件事情再适合不过了。对于一个单词量(n个)很多的文件来说,我们建一个大小为100,层数为7的堆,最坏情况下的时间开销也是O(7n),是一个线性的时间开销。对一个大小为100的固定的堆进行排序,在单词量很大的情况下,可以视为将时间开销视为常数!当然,在统计单词的时候,为了快速查找单词,我们仍然沿用了之前的哈希索引,将所有的结点先存放在散列中,最后在输出的时候再进行堆排序。
堆的常规操作包括建堆、上滤、下滤、排序,这些我们在这里不多说明。散列的使用也和之前相差不大,具体的代码可以再github上看到。优化过后的代码,运行时间大幅下降,从之前的一分半钟下降到现在的13秒,速度提高了六倍!在面对更加巨大的文件时,可以估计,时间增长也会想当缓慢。因为当文件足够大是,由于英语单词的种类并未是无限的,到最后单词种类必然会趋于一个定值,这意味着我们的单词结点数目并不会无限地上升!在一定范围内,我们的时间复杂度和结点数成线性相关,那么由于排序所造成的时间开销,将不再无限制的上升!唯一会增加时间开销的就是I/O操作,当文件非常非常非常非常巨大时,排序的开销趋于定值,I/O操作成为时间开销的主导。不过,我们已经在上一步优化了I/O,而且文件再大也不会大到无限制,至少不会超过电脑所能提供的最大的堆空间。
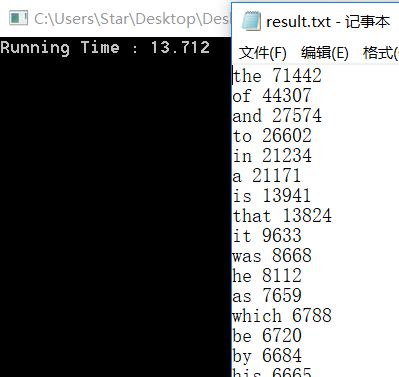
哈希优化
然而想想室友的程序只花了2秒多久运行完成了,我还是很不甘心的。他直接调用了某些库文件提供的方法,这些方法为了确保高效率,甚至使用了汇编代码来编写!所以我们也要继续优化(当然,我们仍然不会去调用现成的库函数)。现在,我们的IO操作、统计、排序的时间开销是这样的:

现在,统计的时间开销变成了整个项目优化的瓶颈!回顾一下我的统计是怎么实现的:首先构建一个长度为128的散列表,在录入单词的时候,给单词的所有字符求和并取模,得到一个散列表的索引,然后根据索引得到一系列的结点(这些结点以散列表为头结点,形成一个线性链表),逐一排查,如果遍历完这个索引下的所有结点,仍然没有找到单词,那么就在散列表的头部添加一个结点。查找、增加结点的过程看起来是这样的:
void WordList::addWord(char word[]) {
// Add the word to the WordList (or word frequency +1)
int p_index = Hash(word);
Word* pWord = index[p_index];
while (pWord != nullptr) {
if (!strcmp(word, pWord->word)) {
pWord->num++;
return;
}
pWord = pWord->next;
}
pWord = new Word(word, 1, index[p_index]);
index[p_index] = pWord;
wordNum++;
}现在,这里的时间开销达到了瓶颈,所以我们不得不再去对这个地方做出改进。首先想到的是,对于一个5M的文件,我们使用一个大小为128的散列表来存放单词,可以预料到,效率会十分低下。每个单元里可能会有上百个单词,每次都要遍历这些链表,时间开销会十分昂贵。我们可以把散列表扩大吗?
答案是可以,而且扩大散列表,并不会加剧空间开销。我们知道,在散列表还是一个空表,没有任何一个结点时,它的空间开销是L倍的结点指针大小(L是散列表的长度),当成千上百个结点慢慢进入散列时,散列表本身的空间开销仍然是L倍的结点指针大小,就可以看成是一个常量了。而结点的个数和文件里面的单词种类有关,和散列表的长度无关。于是,即使我们将散列表的长度扩大数倍,也不会付出很大的空间代价。当然,我们也不会无限制地扩大,注意到我们的哈希函数是对单词所有字符求和,高频单词通常都比较短,求和结果也就是几百而已。如果散列表太长,散列表靠后的那些桶就没办法最大效率地利用到,散列就不均匀了。
在我们的深思熟虑以及亲自尝试下,我们认为512是一个合适的散列长度。将散列表增长后,时间开销有了显著的减少,大致缩短为原来的三分之一。

还有一个问题。在我们通过哈希函数得到索引,然后对一系列具有相同索引的结点进行逐一排查时,如果可以尽量保证高频词优先被排查,那么效率就会进一步提高!审视一下我们之前的代码,每次我们在散列中添加单词时,都会选择在散列的头部添加。这意味着,最先出现的单词排在了散列的尾部,每次都会被最后一个排查到。对于一个有意义的文本,高频词通常都会很快遇到,低频词通常会在文件中后部才首次出现。这无疑会大大增加排查产生的时间开销。
因此,我们决定将这些后出现的单词添加到每个散列表引出的链表的尾部。这一做法并不会使得每次添加产生额外的开销(都只要排查一次所有结点),但是大大提高了查找的效率。在这一次优化后,我们的性能再一次得到了质的飞跃!运行时间缩短了三分之一!不过还是要强调一点,对于一个全随机的无意义的文件,这一做法并不会提高效率!
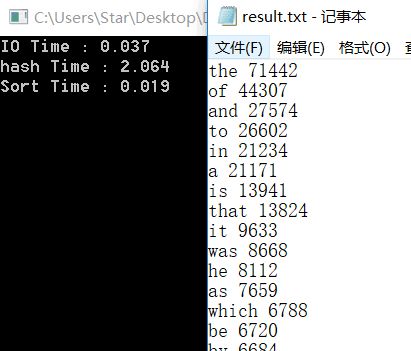
如果你想看一看我们写的改进后的代码,可以在这里查看WordList.h。
这下,对于一个5M的有意义的文件,我们仅仅需要2.100秒就可以完成词频统计(包括输入、统计、排序、输出),和室友调用库函数的效率不相上下!相比最开始的97秒,性能提高了45倍!并且当文件大小不断增长,我们的统计、排序和输出的时间开销将趋于常数(因为单词的种类趋于常数,散列表的大小是常数,并且对100个单词进行排序和输出也是常数开销),IO操作相当快,程序的整体性能非常高!
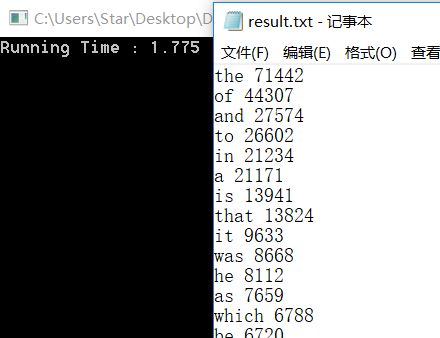
(运气最好的一次,仅仅在2秒内就完成了对一个5M大小的文件的词频统计!)
7.总结
我们所做的这个项目可以说是非常有意义了!从一开始认为这个项目十分简单,到后面开始测试发现各种奇怪的bug,再到最后为了提升性能对源代码大幅修改,我亲自见证了一个简陋的程序进化为一个高质量程序的过程。为了做这个程序,我前后使用了散列、链表、优先队列,这都是最最重要的数据结构,现在,我能够驾轻就熟地亲手操纵这些数据结构,这意味着我离一个合格的程序员又近了一步。
纵观这次项目开发的过程,我们先进行需求分析,然后设计、编码,在保证程序基本正确的情况下,首先进行静态测试以规避隐藏的缺陷,然后设计测试用例进行详细的单元测试(从最基础的功能,到用户可能使用到的最刁钻的功能),最后进行了性能测试。实际上,开发和测试是不分家的,在编码的时候,绝不可能一味地从头写到尾,一定是边写就边测试了;在性能测试时,这点我深有体会,性能测试花费的时间远远没有我为了提升性能,而进行的“二次开发”多。测试和开发相辅相成,如果孤立地看待测试和开发这两件事情,那软件质量一定也不会好。