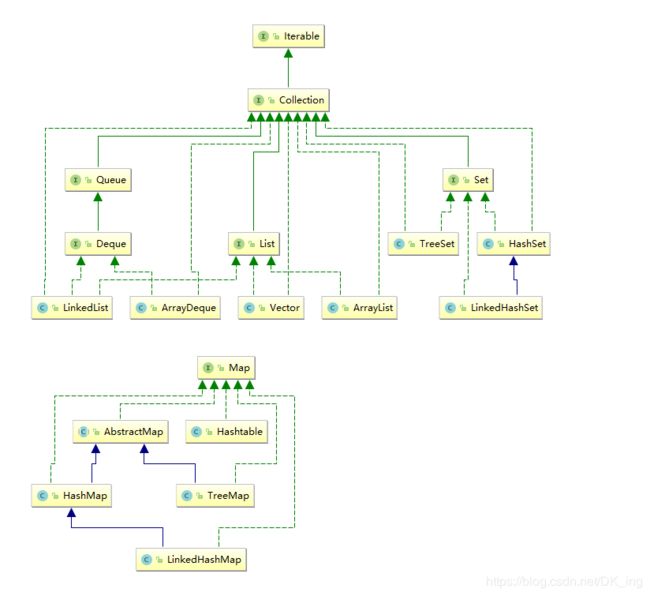
Java集合框架
目录
Collection
Map
深入源码分析
ArrayList
Vector
LinkedList
HashMap
说话前先上图。
Collection
- ArrayList:线程不同步。默认初始数组大小为10,当数组大小不足时容量扩大为1.5倍。
- LinkedList:线程不同步,双向链表。LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,也可以看作一个队列,同时又可以看作是一个栈。当你需要使用栈或者队列时,可以考虑使用LinkedList。当然啦,首选时ArrayDeque。
- Vector:线程同步。默认大小为10,当数组大小不足容量扩大为2倍。
- TreeSet:线程不同步,默认元素“自然顺序”排列,可以通过Comparator改变排序。
- HashSet:线程不同步,内部使用HashMap进行数据存储,所以下文只具体分析HashMap。
- Set:无重复元素的集合。
Map
- HashMap:线程不同步。根据key的hashcode进行存储,内部使用静态内部类Node的数组进行存储,缺省大小为16,每次扩大一倍。当发生Hash冲突时,采用拉链法(链表)。JDK8中:当单个桶中元素个数大于等于8时,链表实现改为红黑树实现;当元素个数小于6时,变回链表实现,防止hashcode攻击。
- LinkedHashMap:保存了记录的插入顺序,先得到的记录肯定是先插入的。
- TreeMap:线程不同步,基于红黑树的NavigableMap实现,能够把它保存的记录根据建排序,默认时按键值的升序排序,也可以制定排序的比较器。
- HashTable:线程安全,HashMap的迭代器时fail-fast迭代器。不能存储null的Key和Value。
深入源码分析
ArrayList
- 概览
实现了RandomAccess接口,因此支持随机访问,ArrayList本就是基于数组实现的。
public class ArrayList extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable 数组默认大小为10 。
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;- 序列化问题
基于数组实现,保存元素的数据使用transient修饰,该关键字声明数组默认不会序列化。ArrayList具有动态扩容特性,因此保存元素的数组不一定都会被使用,那么就没必要全部进行序列化。ArrayList重写了writeObject()和readObject()来控制序列化数组中有元素填充的那部分内容。
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* Save the state of the ArrayList instance to a stream (that
* is, serialize it).
*
* @serialData The length of the array backing the ArrayList
* instance is emitted (int), followed by all of its elements
* (each an Object) in the proper order.
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; iArrayList instance from a stream (that is,
* deserialize it).
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i - 扩容机制
添加元素时使用ensureCapacityInternal方法保证容量足够,如果不够时,需要使用grow()方法进行扩容,新容量的大小为newCapacity = oldCapacity + (oldCapacity >> 1); 也就是旧容量的1.5倍。扩容操作需要调用Arrays.copyOf方法将原数组整个复制到新数组,这一操作代价很高,因此最好在创建ArrayList对象时就制定大概的容量大小,减少扩容操作的次数。
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return true (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}- 删除元素
需要调用System.arraycopy()将index + 1后面的元素都复制到index位置上
/**
* Removes the element at the specified position in this list.
* Shifts any subsequent elements to the left (subtracts one from their
* indices).
*
* @param index the index of the element to be removed
* @return the element that was removed from the list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}- Fail-Fast
首先给大家介绍一下,什么是Fail-Fast机制,在遍历一个集合时,当集合内容被修改,会抛出ConcurrentModificationException异常。fail-fast会在以下两种情况下抛出该异常。
- 单线程:集合被创建后,在遍历它的过程中修改了结构;remove()方法会让expectedModCount和modcount相等,所以是不会抛出这个异常的。
- 多线程:当一个线程在遍历这个集合,而另一个线程对这个集合的结构进行了修改。
modCount参数用来记录ArrayList结构发生变化的次数,add、remove操作或者改变数组大小的操作。
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; iVector
- 添加元素
与ArrayList相似,唯一特殊是使用了synchronized关键字进行同步
/**
* Appends the specified element to the end of this Vector.
*
* @param e element to be appended to this Vector
* @return {@code true} (as specified by {@link Collection#add})
* @since 1.2
*/
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
/**
* This implements the unsynchronized semantics of ensureCapacity.
* Synchronized methods in this class can internally call this
* method for ensuring capacity without incurring the cost of an
* extra synchronization.
*
* @see #ensureCapacity(int)
*/
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}- ArrayList与Vector对比
- Vector是同步的,因此开销比ArrayList打,访问速度慢。因此,ArrayList优于Vector,同步操作可以控制在自己手中;
- Vector每次扩容增大两倍空间,而ArrayList是1.5倍。
- Vector的替代方案
synchronizedList
为了获得线程安全的ArrayList,可以使用Collections.synchronizedList();得到一个线程安全的ArrayList。
/**
* @author King Chen
* @Date: 2019/3/3 14:57
*/
public class ListTest {
public static void main(String[] args) {
List list = new ArrayList<>();
List synchronizedList = Collections.synchronizedList(list);
}
} CopyOnWriteArrayList
可以使用concurrent并发包下的CopyOnWriteArratList类。
List list = new CopyOnWriteArrayList<>(); 写时复制容器,我理解,在我们向容器添加元素的时候,不直接往当前容器添加,而是copy当前容器,在心的容器中添加元素,再将旧容器的引用指向新容器。这样做的好处时我们可以对CopyOnWrite容器进行并发读,而不需要加锁,大大提升了效率。
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
/**
* Sets the array.
*/
final void setArray(Object[] a) {
array = a;
}读的时候不需要加锁,如果读的时候有多个线程正在向ArrayList添加元素,读还是会读到旧数据,因为写的时候不会锁住旧的ArrayList。
/**
* {@inheritDoc}
*
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
return get(getArray(), index);
}缺点
可想而知,不断的Copy出新的容器,对内存的负荷也是过大的。并且,CopyOnWrite只能保证数据的最终一致性。
LinkedList
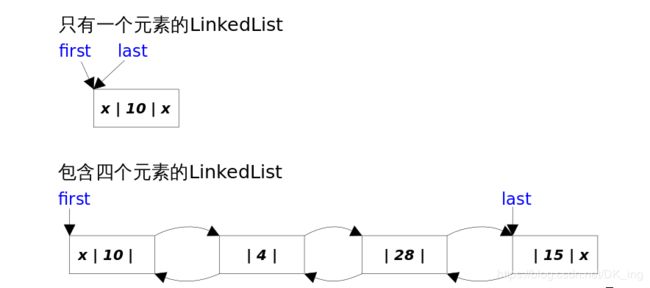
- 概览
LinkedList底层是基于双向链表实现的,也是实现了List接口。
LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以堪称一个队列queue,同时又可以看作一个栈。
LinkedList的底层,是Node节点来保存节点信息的。结构如下:
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
} 每一个链表都存储了头和尾两个节点:
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node last; LinkedList 的实现方式决定了所有跟下标相关的操作都是线性时间,而在首段或者末尾删除元素只需要常数时间。为追求效率LinkedList没有实现同步(synchronized),如果需要多个线程并发访问,可以先采用Collections.synchronizedList();方法对其进行包装。
- 添加add

LinkedList的add()方法,总结来说,有两大类,一种是从中间插入元素,一种是从首尾插入元素。两种实现有差,我们来分别看一下,首先,来看从中间插入的实现:
逻辑稍微复杂些,根据index找到当前节点;将当前节点的上一节点与新节点首位链接,并将当前节点与新节点的尾首位链接。
/**
* Inserts the specified element at the specified position in this list.
* Shifts the element currently at that position (if any) and any
* subsequent elements to the right (adds one to their indices).
*
* @param index index at which the specified element is to be inserted
* @param element element to be inserted
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public void add(int index, E element) {
//检查下标是否越界
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
/**
* Inserts element e before non-null Node succ.
*/
void linkBefore(E e, Node succ) {
// assert succ != null;
final Node pred = succ.prev;
final Node newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
} 而未定义条件的添加,则直接插入末尾:
/**
* Appends the specified element to the end of this list.
*
* This method is equivalent to {@link #addLast}.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
linkLast(e);
return true;
}
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node l = last;
final Node newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
- remove
remove()方法也有两个版本,一个是删除指定元素相等的第一个元素remove(Object o),另一个是删除指定下标的元素remove(int index)。

两个删除操作:
- 先找到要删除元素的引用;
- 修改相关引用,完成删除操作。
在寻找被删除元素引用的时候remove(Object o)调用的是元素的equals方法,而remove(int index)使用的是下标计数。
- get()
/**
* Returns the element at the specified position in this list.
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
/**
* Returns the (non-null) Node at the specified element index.
*/
Node node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
} 典型的二分查找,用来判断index与size中间的举例,从而确定是从头节点还是尾节点开始是检索。
- ArrayList与LinkedList
- ArrayList基于动态数组实现,LinkedList基于双向链表实现;
- ArrayList支持随机访问,LinkedList不支持;
- LinkedList在任意位置添加元素效率更高。
HashMap
- 存储结构
对于JDK1.8来说,HashMap底层在解决哈希冲突的时候,就不单单是使用数组加上单链表的组合了,因为当处理hash值冲突较多的情况下,链表的长度就会越来越长,此时通过单链表来寻找对应的Key对应的Value的时候会使时间复杂度达到O(n),因此,1.8之后,在链表新增节点导致链表长度超过static final int TREEIFY_THRESHOLD = 8;的时候,就会在添加元素的同时将原来的单链表转化为红黑树。
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;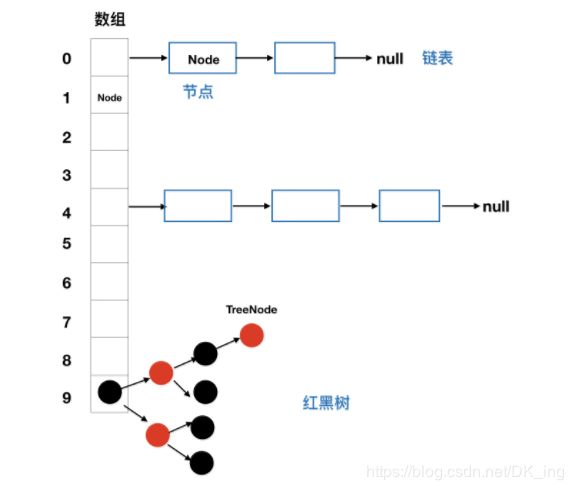
此时,我们需要明确两个问题:1、数据底层具体存储的是什么?2、这样有什么优点?
首先,我们来看一下HashMap中的关键属性,Node[] table。哈希桶。
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node implements Map.Entry {
final int hash;
final K key;
V value;
Node next;
Node(int hash, K key, V value, Node next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry e = (Map.Entry)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
} HashMap就是使用哈希表来存储的。哈希表为解决冲突,可以采用开放地址法和链地址法等来解决问题,Java中HashMap采用了链地址法。链地址法,简单来说就是数组加链表的组合。在每个数组元素上都是一个链表结构,当数据被hash后,得到数组的下标,把数据放在对应下标元素的链表上。如下代码:
map.put("king","test");通过key值的到其hashcode值,然后再通过hash算法的后两步运算来定位该键值对的存储位置,优势两个key会定位到相同的位置,表示发生了hash碰撞。当然,hash算法计算结果约分散均匀,hash碰撞的概率就越小,map的存取效率就会越高。
如果哈希桶数组很大,即使较差的hash算法也会比较分散,如果哈希桶数组很小,即使好的hash算法也会出现较多的碰撞,所以就需要再空间成本和时间成分之间权衡,其实就是根据实际情况确定哈希桶数组的大小,并在此基础上设计好的hash算法减少碰撞。
- put()
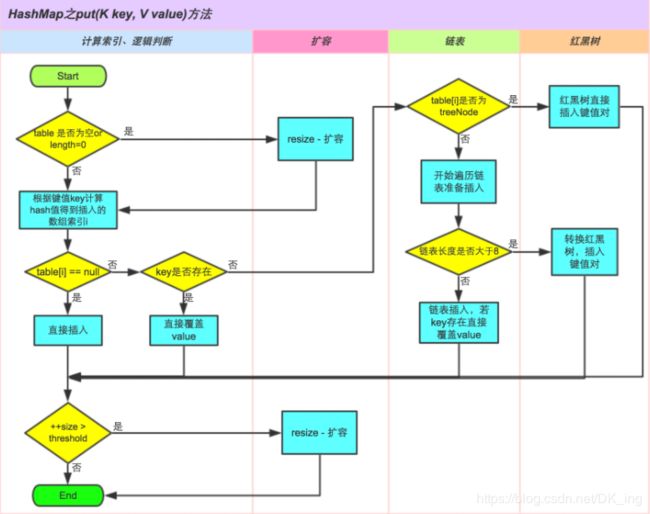
①.判断键值对数组 table[i] 是否为空或为 null,否则执行 resize() 进行扩容;
②.根据键值 key 计算 hash 值得到插入的数组索引i,如果 table[i]==null,直接新建节点添加,转向 ⑥,如果table[i] 不为空,转向 ③;
③.判断 table[i] 的首个元素是否和 key 一样,如果相同直接覆盖 value,否则转向 ④,这里的相同指的是 hashCode 以及 equals;
④.判断table[i] 是否为 treeNode,即 table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向 ⑤;
⑤.遍历 table[i],判断链表长度是否大于 8,大于 8 的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现 key 已经存在直接覆盖 value 即可;
⑥.插入成功后,判断实际存在的键值对数量 size 是否超多了最大容量 threshold,如果超过,进行扩容。
public V put(K key, V value) {
// 对key的hashCode()做hash
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
// 步骤①:tab为空则创建
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 步骤②:计算index,并对null做处理
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
// 步骤③:节点key存在,直接覆盖value
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 步骤④:判断该链为红黑树
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
// 步骤⑤:该链为链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key,value,null);
//链表长度大于8转换为红黑树进行处理
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// key已经存在直接覆盖value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 步骤⑥:超过最大容量 就扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
} - 扩容
final Node[] resize() {
Node[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node[] newTab = (Node[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 把每个bucket都移动到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
else { // 链表优化重hash的代码块
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}