目录
- 1.本次讲座的学习总结
- 2.学习中遇到的问题及解决
- 3.本次讲座的学习感悟、思考等
- 4.“Bitcoin and Block Chain”最新研究现状(由于数据库限制,博客中所查找的论文均为IEEE收录的期刊或会议论文)
- Bitcoin: A Peer-to-Peer Electronic Cash System
- Enhancing Anonymity of Bitcoin Based on Ring Signature Algorithm
- Machine Learning Models Comparison for Bitcoin Price Prediction
- Robust Password-keeping System Using Block-chain Technology
- Process Memory Investigation of the Bitcoin Clients Electrum and Bitcoin Core
- An efficient bitcoin fraud detection in social media networks
- 小结
- 参考资料
课程:《密码与安全新技术专题》
班级:1892
姓名:杨
学号:20189230
上课教师:张健毅
上课日期:2019年4月23日
必修/选修:选修
1.本次讲座的学习总结
讲座主题:区块链技术
2.学习中遇到的问题及解决
- 问题1:究竟什么是拜占庭将军问题?如何解决该问题?
- 问题1解决方案:
(1)问题背景——
在很久很久以前,拜占庭是东罗马帝国的首都。那个时候罗马帝国国土辽阔,为了防御目的,因此每个军队都分隔很远,将军与将军之间只能靠信使传递消息。
在打仗的时候,拜占庭军队内所有将军必需达成一致的共识,才能更好地赢得胜利。但是,在军队内有可能存有叛徒,扰乱将军们的决定。
这时候,在已知有成员不可靠的情况下,其余忠诚的将军需要在不受叛徒或间谍的影响下达成一致的协议。
莱斯利·兰伯特( Leslie Lamport )通过这个比喻,表达了计算机网络中所存在的一致性问题。这个问题被称为拜占庭将军问题。
(2)解决方案——
解决拜占庭将军问题的其中一种方法是使用Raft 共识算法,它依靠状态机和主从同步 的方式,在各个节点之间实现数据的一致性。
Raft算法为节点定义了三种角色:Leader(主节点);Follower(从节点);Candidate(参与投票竞争的节点)。
选出主节点的流程如下:
第一步,在最初,还没有一个主节点的时候,所有节点的身份都是Follower。每一个节点都有自己的计时器,当计时达到了超时时间(Election Timeout),该节点会转变为Candidate。
第二步,成为Candidate的节点,会首先给自己投票,然后向集群中其他所有的节点发起请求,要求大家都给自己投票。
第三步,其他收到投票请求且还未投票的Follower节点会向发起者投票,发起者收到反馈通知后,票数增加。
第四步,当得票数超过了集群节点数量的一半,该节点晋升为Leader节点。Leader节点会立刻向其他节点发出通知,告诉大家自己才是老大。收到通知的节点全部变为Follower,并且各自的计时器清零。
数据同步的流程如下:
第一步,由客户端提交数据到Leader节点。
第二步,由Leader节点把数据复制到集群内所有的Follower节点。如果一次复制失败,会不断进行重试。
第三步,Follower节点们接收到复制的数据,会反馈给Leader节点。
第四步,如果Leader节点接收到超过半数的Follower反馈,表明复制成功。于是提交自己的数据,并通知客户端数据提交成功。
第五步,由Leader节点通知集群内所有的Follower节点提交数据,从而完成数据同步流程。
(3)拜占庭将军问题的其他解决方案——
Paxos 算法:早期的共识算法,由拜占庭将军问题的提出者 Leslie Lamport 所发明。谷歌的分布式锁服务 Chubby 就是以 Paxos 算法为基础。
ZAB 算法:Zookeeper 所使用的一致性算法,在流程上和 Raft 算法比较接近。
PBFT 算法:区块链技术所使用的共识算法之一,适用于私有链的共识。 - 问题2:由公钥生成比特币地址的算法是SHA256。这个过程具体是怎么实现的?
- 问题2解决方案:
由公钥生成比特币地址的总体过程如下图所示:
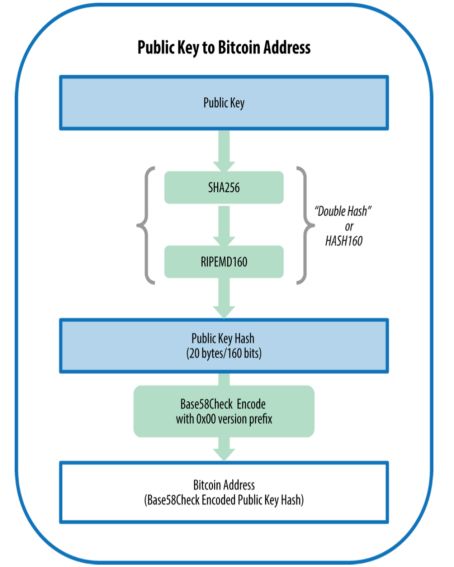
给定公钥K,先进行SHA256哈希,再对SHA256的结果进行RIPEMD160哈希(RACE原始完整性校验讯息摘要),得到的值A就是比特币地址, 即A = RIPEMD160(SHA256(K))。A值进一步压缩, 我们就得到了比特币地址, 形如1J7mdg5rbQyUHENYdx39WVWK7fsLpEoXZy。比特币选择的压缩算法是Base58Check。比特币源码的主要语言是C++,测试代码语言主要是Python。
哈希函数类定义如下, 主体是状态s,由8个32位无符号整数组成。缓冲buf用于批量读入和计算数据。
/** A hasher class for SHA-256. */
class CSHA256
{
private:
uint32_t s[8];
unsigned char buf[64];
uint64_t bytes;
public:
static const size_t OUTPUT_SIZE = 32;
CSHA256();
CSHA256& Write(const unsigned char* data, size_t len);
void Finalize(unsigned char hash[OUTPUT_SIZE]);
CSHA256& Reset();
};SHA256的主体代码,数据data每64字节读入一次,写入buff,经过Transform处理,得到s值。
CSHA256& CSHA256::Write(const unsigned char* data, size_t len)
{
const unsigned char* end = data + len;
size_t bufsize = bytes % 64;
if (bufsize && bufsize + len >= 64) {
// Fill the buffer, and process it.
memcpy(buf + bufsize, data, 64 - bufsize);
bytes += 64 - bufsize;
data += 64 - bufsize;
Transform(s, buf, 1);
bufsize = 0;
}
if (end - data >= 64) {
size_t blocks = (end - data) / 64;
Transform(s, data, blocks);
data += 64 * blocks;
bytes += 64 * blocks;
}
if (end > data) {
// Fill the buffer with what remains.
memcpy(buf + bufsize, data, end - data);
bytes += end - data;
}
return *this;
}一些基本运算的定义,如Ch, Maj, Sigma0, Sigma1, sigma0, sigma1等。
uint32_t inline Ch(uint32_t x, uint32_t y, uint32_t z) { return z ^ (x & (y ^ z)); }
uint32_t inline Maj(uint32_t x, uint32_t y, uint32_t z) { return (x & y) | (z & (x | y)); }
uint32_t inline Sigma0(uint32_t x) { return (x >> 2 | x << 30) ^ (x >> 13 | x << 19) ^ (x >> 22 | x << 10); }
uint32_t inline Sigma1(uint32_t x) { return (x >> 6 | x << 26) ^ (x >> 11 | x << 21) ^ (x >> 25 | x << 7); }
uint32_t inline sigma0(uint32_t x) { return (x >> 7 | x << 25) ^ (x >> 18 | x << 14) ^ (x >> 3); }
uint32_t inline sigma1(uint32_t x) { return (x >> 17 | x << 15) ^ (x >> 19 | x << 13) ^ (x >> 10); }1初始化8个32位的无符号整数,作为初始状态。
/** Initialize SHA-256 state. */
void inline Initialize(uint32_t* s)
{
s[0] = 0x6a09e667ul;
s[1] = 0xbb67ae85ul;
s[2] = 0x3c6ef372ul;
s[3] = 0xa54ff53aul;
s[4] = 0x510e527ful;
s[5] = 0x9b05688cul;
s[6] = 0x1f83d9abul;
s[7] = 0x5be0cd19ul;
}
/** One round of SHA-256. */
void inline Round(uint32_t a, uint32_t b, uint32_t c, uint32_t& d, uint32_t e, uint32_t f, uint32_t g, uint32_t& h, uint32_t k, uint32_t w)
{
uint32_t t1 = h + Sigma1(e) + Ch(e, f, g) + k + w;
uint32_t t2 = Sigma0(a) + Maj(a, b, c);
d += t1;
h = t1 + t2;
}Transform函数:函数输入一个64字节的chunk和状态s,每次从chunk读入4字节,根据当前状态s,做16次Round计算;完成后再做三轮16次Round;最后,8个无符号整数都加上上述64次Round的结果,更新状态s。经过上述计算,我们就得到了数据chunk的SHA256哈希值。
/** Perform a number of SHA-256 transformations, processing 64-byte chunks. */
void Transform(uint32_t* s, const unsigned char* chunk, size_t blocks)
{
while (blocks--) {
uint32_t a = s[0], b = s[1], c = s[2], d = s[3], e = s[4], f = s[5], g = s[6], h = s[7];
uint32_t w0, w1, w2, w3, w4, w5, w6, w7, w8, w9, w10, w11, w12, w13, w14, w15;
// 步骤一:
Round(a, b, c, d, e, f, g, h, 0x428a2f98, w0 = ReadBE32(chunk + 0));
Round(h, a, b, c, d, e, f, g, 0x71374491, w1 = ReadBE32(chunk + 4));
// 中间省略...
Round(c, d, e, f, g, h, a, b, 0x9bdc06a7, w14 = ReadBE32(chunk + 56));
Round(b, c, d, e, f, g, h, a, 0xc19bf174, w15 = ReadBE32(chunk + 60));
// 步骤二:
Round(a, b, c, d, e, f, g, h, 0xe49b69c1, w0 += sigma1(w14) + w9 + sigma0(w1));
Round(h, a, b, c, d, e, f, g, 0xefbe4786, w1 += sigma1(w15) + w10 + sigma0(w2));
// 中间省略
Round(c, d, e, f, g, h, a, b, 0x06ca6351, w14 += sigma1(w12) + w7 + sigma0(w15));
Round(b, c, d, e, f, g, h, a, 0x14292967, w15 += sigma1(w13) + w8 + sigma0(w0));
// 步骤三:
Round(a, b, c, d, e, f, g, h, 0x27b70a85, w0 += sigma1(w14) + w9 + sigma0(w1));
Round(h, a, b, c, d, e, f, g, 0x2e1b2138, w1 += sigma1(w15) + w10 + sigma0(w2));
// 中间省略
Round(c, d, e, f, g, h, a, b, 0xf40e3585, w14 += sigma1(w12) + w7 + sigma0(w15));
Round(b, c, d, e, f, g, h, a, 0x106aa070, w15 += sigma1(w13) + w8 + sigma0(w0));
// 步骤四:
Round(a, b, c, d, e, f, g, h, 0x19a4c116, w0 += sigma1(w14) + w9 + sigma0(w1));
Round(h, a, b, c, d, e, f, g, 0x1e376c08, w1 += sigma1(w15) + w10 + sigma0(w2));
// 中间省略
Round(c, d, e, f, g, h, a, b, 0xbef9a3f7, w14 + sigma1(w12) + w7 + sigma0(w15));
Round(b, c, d, e, f, g, h, a, 0xc67178f2, w15 + sigma1(w13) + w8 + sigma0(w0));
s[0] += a;
s[1] += b;
s[2] += c;
s[3] += d;
s[4] += e;
s[5] += f;
s[6] += g;
s[7] += h;
chunk += 64;
}
}3.本次讲座的学习感悟、思考等
在上这节课之前,我只是从别人口中听说过比特币和区块链的概念,围绕的关键词不外乎两个:火爆和泡沫。
今天通过张健毅老师提纲挈领式的讲解,我不仅了解了比特币的产生和发展,它神秘的创始人中本聪,还了解了它的技术原理,一切都没有我想象的那么复杂。下课后,我查阅了该领域的一些顶会论文,阅读并学习了比特币的源码及框架,一块一块将它拆开,我才真正地理解了比特币和区块链技术的魅力所在,也会在未来持续关注。也许在10年,20年之后,是“黄金”还是“沙子”才能一见分晓。
我查阅资料时,看到网友们对于比特币为什么能洗钱的讨论。实际上,比特币的交易单是只允许一进一出,但是实际上比特币的协议允许无数个进,无数个出,只要进出总额相等就可以。以贩毒的买卖过程为例:
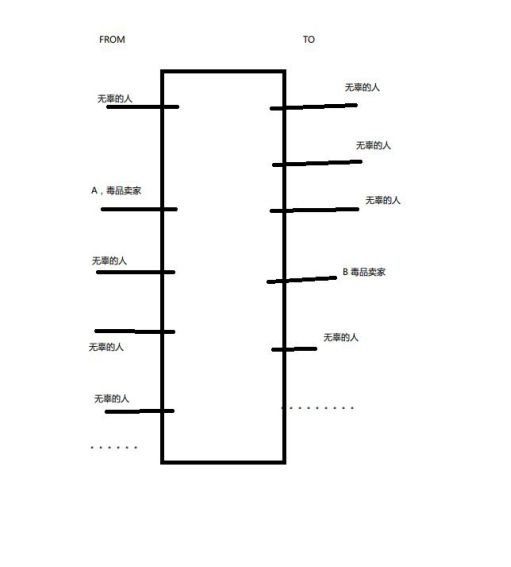
如果一个从事毒品交易的人A要想卖家B付款,可以搞一个这样的交易,左边无数个无辜的人,就一个毒品买家,右边无数个无辜的人,就一个卖家。当FBI知道毒品卖家账户的时候,要想查源头,需要追溯无数个无辜的人,挨个去核实他是不是买家,实际情况下,楼上这种交易可以重复几百次,于是最后想回溯金钱来源变的很困难,因为可能涉及几万几十万人,这些人又有可能分部在全世界各个国家。
4.“Bitcoin and Block Chain”最新研究现状(由于数据库限制,博客中所查找的论文均为IEEE收录的期刊或会议论文)
Bitcoin: A Peer-to-Peer Electronic Cash System
论文来源:
| www.bitcoin.org(这是中本聪在2008年第一次提出比特币概念的经典论文) |
作者信息:
•[Satoshi Nakamoto]
学习与思考:
1.比特币本质上是一种点对点的电子货币系统, 它提出的本质目的是为了解决互联网贸易依赖金融机构作为可信任第三方来处理电子支付的固有缺点。而基于密码学原理的比特币交易系统可以保证交易在计算上的不可撤销,也能保护卖家不被欺诈,买家的程序化合约机制也比较容易实现。
2. 工作量证明解决的是在多数决定中确定投票方式的问题。如果多数是按 IP 地址投票来决定,那么它将可能被能分配大量 IP 地址的人破坏。实际上工作量证明本是按CPU 投票。 最长的链代表了多数决定,因为有最大的计算工作量证明的精力投入到这条链上。如果多数的CPU算力被诚实节点控制,诚实的链就会增长得最快并超过其他的竞争链。要修改过去的某区块,攻击者必须重做这个区块以及其后的所有区块的工作量证明从而赶上并超过诚实节点的工作。但是随着后续的区块被添加,一个更慢的攻击者赶上诚实节点的概率将呈指数级递减。
3.比特币的交易系统中存在回收磁盘空间的问题。一旦某个货币的最新交易已经被足够多的区块覆盖,这之前的支付交易就可以被丢弃以节省磁盘空间。为便于此而又不破坏区块的哈希值,交易将被哈希进默克尔树,只有根节点被纳入到区块的哈希值。老的区块可通过剪除树枝的方式被压缩。树枝内部的哈希不需要被保存。
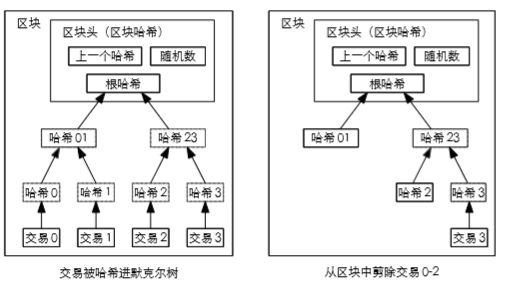
| 补充:什么是默尔克树? |
默克尔树是一种二叉树,由一组叶节点、一组中间节点和一个根节点构成,最下面的大量的叶节点包含基础数据;每个中间节点是它的两个叶子节点的哈希,根节点也是由它的两个子节点的哈希,代表了默克尔树的顶部。
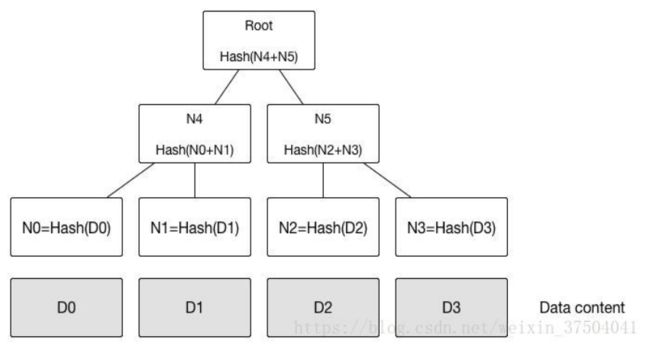
从默克尔树的结构可以看出,任意一个叶子节点的交易被修改,叶子节点hash值就会变更,最终根节点的hash值就会改变。所以确定的根节点的hash值可以准确的作为一组交易的唯一摘要。
默克尔树的特点可以总结如下:
(1)首先是它的树的结构,默克尔树常见的结构是二叉树,但它也可以是多叉树,它具有树结构的全部特点。
(2)默克尔树的基础数据不是固定的,想存什么数据由你说了算,因为它只要数据经过哈希运算得到的hash值。
(3)默克尔树是从下往上逐层计算的,就是说每个中间节点是根据相邻的两个叶子节点组合计算得出的,而根节点是根据两个中间节点组合计算得出的,所以叶子节点是基础。
4.比特币交易系统中的隐私问题:传统的银行模型通过限制参与方和可信任第三方对信息的访问来满足用户对隐私的要求。交易要公开发布就不能使用这个方法,但隐私仍可在其他地方通过阻断信息流的方式来保护:那就是保持公钥匿名。公众能看到有人正在发送一定量货币给其他人,但是不能将交易关联到某个人。这和证券交易所发布的信息级别类似,每笔交易的时间和交易量,即行情是公开的,但是不会显示交易双方是谁。
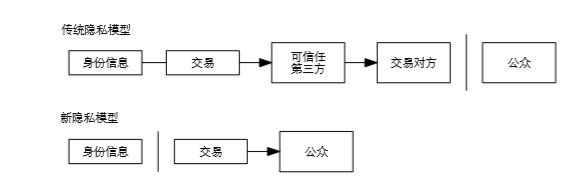
Enhancing Anonymity of Bitcoin Based on Ring Signature Algorithm
论文来源:
| 2017 13th International Conference on Computational Intelligence and Security (CIS) |
作者信息:
•[Yi Liu]
•[Ruilin Li]
•[Xingtong Liu]
研究进展:
比特币是一种去中心化的数字货币,因其匿名性而被广泛使用,近年来已迅速流行起来。比特币以用户的笔名在公共分类账中公布完整的交易历史。这是防止双重支出攻击而不是中央政府的另一种方法。因此,如果在现实世界中,用户的假名与他们的身份相关联,比特币的匿名性将是一个严重的弱点。有必要通过硬币混合服务或比特币协议中的其他修改来增强比特币的匿名性。但是,在混合服务中,输入和输出地址之间的关系不会被混合服务提供者隐藏。因此混合服务器仍然能够跟踪比特币用户的交易记录。为了解决这个问题,文章提出了一种新的硬币混合方案,以确保混合服务器看不到任何用户的输入和输出地址之间的关系。本文作者使用一个环签名算法来确保混合服务器不能区分特定事务和所有这些地址。环签名确保签名是由环中的某个用户签名的,并且不会泄漏有关签名者的任何信息。此外,该方案与现有比特币协议完全兼容,易于对大量用户进行扩展。
2001年,rivest提出了一种新的匿名传递秘密信息的签名算法,称为环签名。环签名作为一种特殊的群签名,没有可信中心和群的建立过程。对于验证者,签名者是完全匿名的。
环签名的步骤包括:生成、签名与验证。
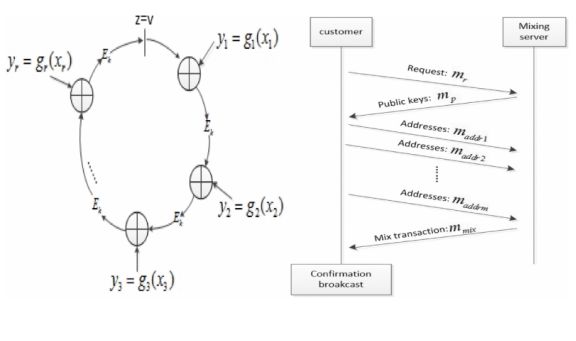
在文章所用的混合服务中,使用一个中间服务器来生成一个混合事务,它聚合了所有输入请求事务和所有输出地址。虽然集中式服务器与比特币理念不一致,但它不会破坏分布式结构或比特币。服务器只是提供一个补充服务,而不是占据主导地位。
文章对系统的性能进行了分析,主要包括以下几点:
1)匿名性
混合方案仍然可以确保参与者的匿名性,即使混合服务器受到威胁。由于环签名算法的特性,即使混合服务器也无法区分属于特定客户的地址和所有比特币地址。由于返回的地址通过有效的环签名逐个发送到混合服务器,混合服务器只能确保一个地址来自合法成员,但无法区分哪个地址属于哪个成员。外部攻击者只能拦截单独的事务和地址。它们也不能将地址链接到相应的事务。
2)抵抗DoS攻击
一个客户可以在许多分布式混合协议中启动DoS攻击,通过初始化混合服务而不响应地址请求,导致整个协议失败。为了解决这个问题,在混合方案中,每个客户只建立到混合服务器的连接。任何不符合协议规定的行为不端的用户都可以被发现并排除在外。攻击者还可以执行另一种DoS攻击,以防止区块链包含混合事务。然而,攻击者在现实中很难做到这一点,因为他们必须接管比特币网络中至少51%的现有计算资源。
3)可扩展性
根据比特币规定,在混合交易中添加更多客户是很容易的,因为输入交易和输出地址没有限制。混合服务器可以在不同的混合事务中分离不同客户的请求,同时适合大量客户。通过改进服务器配置,如处理器和带宽,可以缓解混合服务器的瓶颈问题。
4)优势
与集中式混合业务相比,该方案不仅能够防止混合服务器偷币,而且可以防止混合服务器将输入和输出连接起来。与分布式混合服务相比,本文中所提出的方案更易于部署,开销更低。
Machine Learning Models Comparison for Bitcoin Price Prediction
论文来源:
| 2018 10th International Conference on Information Technology and Electrical Engineering (ICITEE) |
作者信息:
• Thearasak Phaladisailoed
• Thanisa Numnonda
研究进展:
近年来,比特币是加密货币市场上最有价值的货币。然而,比特币的价格波动很大,很难预测。因此,本研究旨在找出最有效和最精确的模型,以预测不同机器学习算法的比特币价格。利用2012年1月1日至2018年1月8日比特币交易网站Bitstamp上的1分钟区间交易数据,对Scikit-IEARN和Keras库的不同回归模型进行了实验。结果表明,均方误差(MSE)低至0.00002,R平方误差(R 2)高达99.2%。
有两个最常用的度量用于测量连续变量的精度,均方误差(MSE)和R平方(R2)。表1显示了所有实现模型的MSE和R2,而表2显示了所有实现模型的计算时间。结果表明,基于深度学习的GRU和LSTM回归模型比泰尔森回归和胡伯回归模型有更好的效果。GRU在0.00002和0.992或99.2%时的MSE结果最好。然而,Huber回归使用的计算时间远小于LSTM和GRU。

Robust Password-keeping System Using Block-chain Technology
论文来源:
| 2018 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM) |
作者信息:
• Daniel Tse
• Kecong Huang
• Bin Cai
研究进展:
大多数网络信息系统要求用户提供身份信息作为身份验证的一种方式,通常身份信息是一对用户名和密码。由于有如此多的信息系统可供访问,人们需要记住数百个用户名和密码。因此,他们经常忘记自己的用户名或密码,必须经过一个耗时且麻烦的过程才能找到他们。在本文中提出了一种使用区块链以加密格式存储用户用户名和密码的解决方案。当特定网站的用户名或密码丢失时,可以通过区块链访问它们。因此,人们不再需要记住不同网站的用户名和密码。存储在区块链中的密码不会受到任何网络攻击的影响,因为区块链是不可变的。
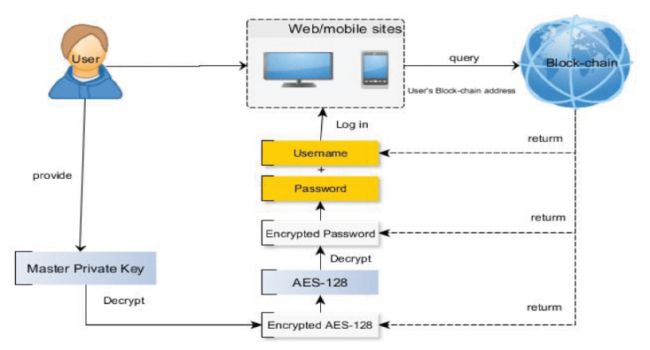
系统设计的主体思路是:首先用对称的AES-128密钥对用户密码进行加密,然后用称为主公钥的非对称密钥对AES-128密钥进行加密,最后将对称的AES-128密钥和非对称的主密钥存储在块中。此外,该块还包含网站域名和用户名。当用户想要访问忘记密码的网站时,使用其拥有的主私钥对加密的AES-128密钥进行解密并获得AES-128,然后使用以前获得的AES-128对加密的密码进行解密。解密过程完成后,区块链返回网站的用户名和密码,自动完成登录过程。该系统作为第三方解决方案不仅效率高、方便,而且解决了AES-128的随机性和高安全性以及区块链的透明性和不可变性带来的信任问题。系统示意图如下:
Process Memory Investigation of the Bitcoin Clients Electrum and Bitcoin Core
论文来源:
| IEEE Access ( Volume: 5 ) |
作者信息:
• Luuc Van Der Horst
• Kim-Kwang Raymond Choo
• Nhien-An Le-Khac
研究进展:
文章研究了比特币核心和Electrum钱包两种流行的比特币客户端的过程存储器,旨在识别潜在的来源和潜在的相关数据类型(如比特币密钥、交易数据和密码)。从进程内存获得的人工制品也与从客户端设备获得的其他人工制品(磁盘上的应用程序文件和内存映射文件以及注册表项)一起进行研究。这项研究的结果表明,比特币核心和Electrum的进程内存都是一个有价值的证据来源,进程内存中发现的许多人工制品也可以从客户端设备(磁盘)上的应用程序和钱包文件中获得。
An efficient bitcoin fraud detection in social media networks
论文来源:
| 2017 International Conference on Circuit ,Power and Computing Technologies (ICCPCT) |
• Anju Viswam
• Gopu Darsan
研究进展:
如今,人们经常使用多个社交网站,因此越来越多的人在网络上拥有多个帐户。在网络上识别匿名用户是一项挑战。基于朋友关系的技术被用来识别多个社交网站上的同一用户。它基于这样一个概念,即朋友关系不能被他人伪造。基于FRUI(朋友关系用户识别)算法,开发了多站点用户匹配算法。它计算多个站点上具有相同屏幕名称的所有用户的匹配度,匹配度最高的用户将被视为相同的用户。将该方法推广到包括比特币概念在内的社交媒体网站中的欺诈识别。
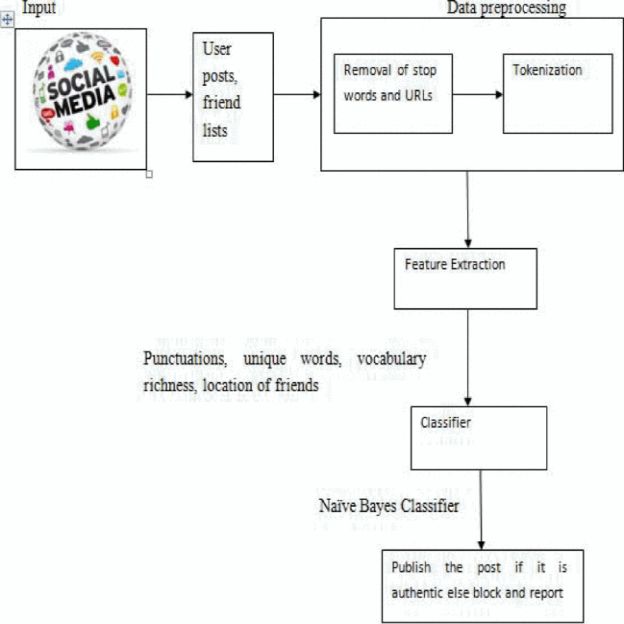
如图,显示了所提出系统的体系结构。该系统主要分为在线数据提取、特征提取和分类三个阶段。在线数据将是网站上发布的帖子和好友列表。获取的数据经过预处理,然后将所需数据特征提取到后端数据库。然后使用naive bayes分类器对提取的特征数据进行分类。因此,分类完成后,将保存更准确的分类输出,并删除其他输出。在朴素贝叶斯分类器中,选择了多项式朴素贝叶斯分类器,因为它是一种更适合分类的多类分类器,简单且适用于大型数据集。
系统主要由五个模块组成。在线数据提取包括用户发布的各种帖子以及他们的朋友圈。应进行数据预处理,将在线数据转换为结构化格式。它包括删除停止字和URL,以及字的标记化技术。然后必须从中提取所需的特性。然后建立了分类器训练数据集。这里使用的是NaiveBayes分类器。然后将测试数据输入分类器以产生预期的结果。模块解释如下。
A.在线数据提取
在线数据包括用户发布的各种帖子以及他们的朋友圈。所有提取的数据都存储在数据库中。数据库将包括从中提取的在线数据,这些数据将被用于进一步处理和分类。
B.数据预处理
数据预处理是特征提取前的重要步骤之一。在线数据的格式不适合处理和训练分类器。应将其转换为适当的格式以提取所需的功能。在线数据的数据预处理包括删除链接、停止字和标记化技术。
C.特征提取
从数据库中获取的数据现在可以进行特征提取了。特定用户可以根据某些特定功能进行分类。这些独特的特性有助于识别文本的作者。在用户注册期间跟踪的IP地址有助于提取用户的位置。训练集是根据这些提取的特征创建的。
D.训练集
训练集是手工制作的,这样我们就可以根据需要对模型进行培训。根据提取的特征,在数据库中为每个人的档案建立一个训练集。通过组合所有提取的特征来创建训练集。由提取的数据组成的训练集将提供给分类人员进行分类。
E.分类
采用朴素贝叶斯分类器进行分类。训练集和测试集是分类器的输入。训练集已手动创建,测试集是用于区分特定用户的已注册用户的配置文件详细信息。测试集的分类基于训练集。
多项式NaiveBayes是一种为文本文档设计的NaiveBayes类型。它也适用于大型数据集,并且易于应用。它计算给定文档的类概率。让一组类用C表示,N是词汇表的大小,然后用下式表示朴素贝叶斯公式:
小结
通过调研和查阅文献资料,我深入理解了比特币和区块链技术,也了解到这一领域存在的争议远远大于其发展与应用的潜力。
虽然比特币和区块链可以说是一脉相承,但是区块链远远大于比特币本身。比特币推动了区块链的发展,但从未来趋势上看,区块链的发展空间更大。同时,华尔街的加入、山寨币的兴起、ICOs的爆发增长、政府和监管机构的压制以及黑客成倍增加都是影响区块链技术未来发展方向的因素。未来怎样,还要拭目以待!
参考资料
Bitcoin: A Peer-to-Peer Electronic Cash System
Enhancing Anonymity of Bitcoin Based on Ring Signature Algorithm
Machine Learning Models Comparison for Bitcoin Price Prediction
Robust Password-keeping System Using Block-chain Technology
Process Memory Investigation of the Bitcoin Clients Electrum and Bitcoin Core
An efficient bitcoin fraud detection in social media networks