PHP缓冲区原理的初步学习
最近在阅读ThinkPHP5.0源码的时候,看到代码:
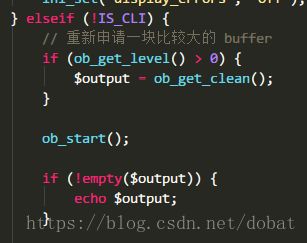
从注释明白功能要申请一块比较大的buffer,但是为什么新申请的就比较大,原来的就小呢?小有什么关系吗?因此着重学习下ob_*系列的函数,想要深入了解下这部分功能。
ob_*函数在以前有了解到是来操作PHP缓冲区的,最先使用场景是,我们要对用户数据进行批量处理,那么使用echo输出信息来展示当前进度无疑是一个简便快捷的办法。但是不管是echo、var_dump、print函数,都不能即时输出,如代码:

必须要等到脚本执行完成,才会同时输出0-10,不能先输出0,等待1秒,再输出1。通过查找PHP如何即时输出,在网上找到类似代码

执行发现,能够逐个数字逐秒输出。
查找两个函数的说明,
ob_flush():把数据从PHP的缓冲(buffer)中释放出来。
flush():把不在缓冲(buffer)中的或者说是被释放出来的数据发送到浏览器。
鸟哥文章:http://www.laruence.com/2010/04/15/1414.html 解释比较清楚,
原来PHP有个所谓的缓冲区,同时必须的执行顺序是先ob_flush()再flush();
ob函数操作PHP缓冲区,flush刷新WebServer缓冲区。
很惭愧,当时的自己还是个入门的小开发,解决了即时输出问题强行背了下这两个函数,就没有了下文。在近日阅读代码过程中又接触到缓冲区概念,那就好好了解一下吧!
PHP脚本输出的流程说明
即:脚本输出 => PHP的缓冲区设置 => 系统的缓冲区设置(apache、nginx) => 浏览器
PHP 缓冲区(buffer)说明
脚本输出信息首先放入buffer,只有当buffer满了或者脚本运行完毕,数据才会往下一阶段转移。在配置文件php.ini可以找到output_buffering设置项,我的默认配置(Windows/XAMPP v3.2.2)是4096
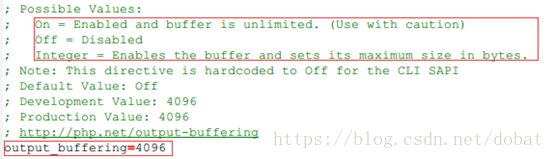
若设置成On,缓冲区可用且无大小限制;
若设置为Off,缓冲区不可用;
若设置为整数,缓冲区可用且为设置大小,单位字节
需要注意的是,ini_set无法设置buffer大小,在初始化脚本运行环境时,已经做好了buffer的定义;cli模式下始终默认output_buffering为Off。
那么问题来了,缓冲区关闭和打开有什么区别?缓冲区初始设置的大小有什么作用?cli模式默认关闭若业务需要能开启吗?缓存区存在有什么好处?
1. 缓冲区关闭和打开有什么区别?
通过代码检验
output_buffering配置为4096时,运行代码

输出结果:在等待3秒钟后,同时输出了start和end
Output_buffering配置为Off时,运行相同代码
输出结果:先输出了start,等待3秒钟后,输出了end
单一看结果一模一样啊~但是观察其运行过程发现了很惊讶的不同点。若缓冲关闭,先输出“start”,等待3秒后再输出“end”。而缓冲开启,会等待脚本执行完成,一并输出结果
这个例子中,flush用于刷新apache的缓冲区,类似让PHP buffer与浏览器建立直接联系,好让我们的注意力能够专注PHP buffer本身。
通过一个形象的例子比喻,PHP的缓冲区像一个大房子,每次echo等输出函数执行时,将数据扔到这个大房子里,直到脚本执行完成或执行ob_flush函数,将数据从大房子中释放,扔给了WebServer缓冲区。关闭了PHP缓冲区后,echo函数执行,没有大房子可以放怎么办呢,就只好直接交给WebServer缓冲区了。
通过例子和代码执行结果,我们能够明白,所谓PHP buffer,是PHP本身开辟的数据存储中枢站,一系列的ob函数都是为此操作。(举几个例子函数)
ob_clean(); //删除内部缓冲区的内容,不关闭缓冲区(不输出)。
ob_end_clean(); //删除内部缓冲区的内容,关闭缓冲区(不输出)。
ob_get_contents(); //返回缓冲区的内容,不输出
ob_get_length(); //返回内部缓冲区的长度,如果缓冲区未被激活,该函数返回FALSE。
2. 缓冲区初始设置的大小有什么作用?
将output_buffering从4096改为5,方便执行测试
执行代码

输出说明:等待3秒后,输出1234end
执行代码
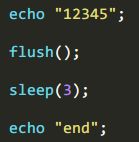
输出说明:输出12345,等待3秒后,输出end
通过输出的比较,很能说明区别了。
缓冲区只能放5字节的数据,放进来的小于这个最大值,还能先存存放放,要是大于等于临界值,那就只好将数据踢出去了,这就跟我们手动执行了ob_flush函数一个效果。
3. cli模式默认关闭若业务需要能开启吗?
这个问题可以做个补充,非cli模式下,如果php.ini设置缓冲区关闭,但是业务需要用到buffer,咋整呢,难不成还要去改配置。当然不会那么难搞了,这时候又一个ob函数来了,
ob_start(); //打开一个输出缓冲区,所有的输出信息不再直接发送到浏览器,而是保存在输出缓冲区里面。
知道了PHP buffer类似数据临时存储区的概念,回过头再来看看TP5源码。
先看看ob_get_level和ob_get_clean函数解释
ob_get_level() :返回输出缓冲机制的嵌套级别。
ob_get_clean():得到当前缓冲区的内容并删除当前输出缓冲区。
从代码中也能得知一二,若level获取大于0,获取缓冲区的内容并删除缓冲区,再通过ob_start打开一个新的,这也很符合注释里说明的“重新申请”。
这里解释下所谓的嵌套,至于level的值啥时候会为0,并且非0的话是什么呢,请将php.ini output_buffering关闭,输出看看结果。另外多次ob_start,多次ob_get_level,来试试对比输出结果吧。
先来看看两种模型

在多次ob_start打开新的缓冲区时,数据结构的构造为第二种,这就是嵌套了。ob_get_level返回了嵌套的级别。
个人理解,嵌套可以套用Java的流机制来类比,一个缓冲区的数据输出到下一个缓冲区,然后可以对数据做定制化的操作。
现在看TP5源码,思路就比较清晰了。如果系统初始化了缓冲区,因为大小可能会有限制,所以先删除再重新打开。而执行ob_start打开的缓存区,它的大小“足够大”,但是到底有多大,暂时没有查到具体的说明,只知道,不管写入数据多大,都会直到脚本结束才会发送。
4. 缓存区存在有什么好处?
PHP输出数据发送到WebServer,若echo执行一次发送一次,这加大了资源消耗,不如存储在内存中,统一发送更有效率。
Web请求包含HTTP头部,头部在设置之前不能有任何的输出。PHP缓冲区替我们做好了这步工作,在头部发送前输出各种数据,缓冲区会先将头部信息发送到WebSever,再统一发送数据报文。
最后再转一篇文章,觉得写的很好,可以学习到很多:
https://gywbd.github.io/posts/2015/1/php-output-buffer-in-deep.html