闲谈IPv6-聊聊IPv6端到端分段和MTU探测的问题
浙江温州皮鞋胖,下雨金说不会湿!
我始终相信,新的事物总是好的,它要么是为了解决前任的问题,要么是从零到一引入了一个创举,人性不好说,但科技总是随着时间进步的。然而人总是有惰性,人没有拥抱变化的基因,所以让人接受新的东西,就要付出点代价。
人们会反驳,说新的东西引入了以前曾经没有的问题,但这十有八九是借口,背后其实是再说, 我才不想为支持你这个新玩意儿去改动旧框架呢? 毕竟人都是懒惰的,涉及到工作量的时候,能不动就不动。
IPv6不再支持中间节点分片,仅支持端到端的分片,在我看来,这是好事,因为这必然使得IP层工作地更有效率,把端到端的智能真正交给了端到端,这不光有益于IP层的处理效率:
- 报头瘦身,路由器不再check分片相关的字段;
- 处理简化,路由器再也不用处理分片和重组的逻辑。
而且还有益于TCP层的效率:
- 不分片减小了TCP包级别的乱序概率,不然一个片段乱序,就可能意味着重组延迟造成包乱序;
- 不分片减小了TCP包级别的丢包概率,不然一个片段丢失,就意味着TCP包丢失。
多么好的事情!
但是没有免费的午餐,为了获得上述的收益,总是要做一些改变吧。幸运的是,改变非常简单,就是 你在数据始发端就确定下来端到端路径最小的MTU即可! 然后按照这个 M T U m i n MTU_{min} MTUmin发包即可。
但问题是,在数据发送端确定一个最小的MTU这件事具体怎么来做。
好了,开始撕。先看教科书上怎么说:
- 执行MTU发现,即基于ICMP的PMTU
但是,我们知道PMTU严重依赖路由器回复的ICMP need fragment消息,而ICMP消息在网络上是不保证传输且无回执的。所以我们不能依赖基于ICMP的PMTU。
以上方案被Pass!
然后,如果使用Linux做服务器,还有另一个选择,即配置 net.ipv4.tcp_mtu_probing 参数为2:
- 执行自动PMTU,即在TCP超时时自动按照比例缩减MSS的大小,重传数据包
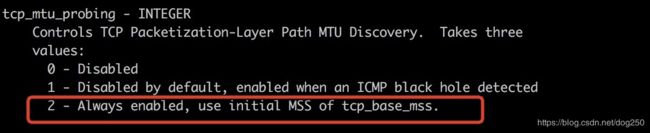
每当TCP发包超时时,又迟迟收不到ICMP need fragment消息时,就会进入这个MSS缩减逻辑,和ICMP need fragment不同,这个缩减比例是拍出来的经验值,不像ICMP need fragment消息会明确告诉协议栈具体的MTU值。算法如下:
static void tcp_mtu_probing(struct inet_connection_sock *icsk, struct sock *sk)
{
/* Black hole detection */
if (sysctl_tcp_mtu_probing) {
if (!icsk->icsk_mtup.enabled) {
icsk->icsk_mtup.enabled = 1;
tcp_sync_mss(sk, icsk->icsk_pmtu_cookie);
} else {
struct tcp_sock *tp = tcp_sk(sk);
int mss;
// 减半
mss = tcp_mtu_to_mss(sk, icsk->icsk_mtup.search_low) >> 1;
// 界定
mss = min(sysctl_tcp_base_mss, mss);
// 下界
mss = max(mss, 68 - tp->tcp_header_len);
icsk->icsk_mtup.search_low = tcp_mss_to_mtu(sk, mss);
tcp_sync_mss(sk, icsk->icsk_pmtu_cookie);
}
}
}
仔细看这个算法,就会发现也有问题。
假设当前的 M T U m i n MTU_{min} MTUmin是1500,由于路由重新收敛,换了另外一条路径后, M T U m i n MTU_{min} MTUmin成了1460,仅仅减少了40个字节,可能是通过了一个隧道。然而按照上面的算法,默认的sysctl_tcp_base_mss配置为512的话,TCP假想的探测到的 M T U m i n MTU_{min} MTUmin就会变为578字节!造成了近1000字节的浪费!
以往一个满负载的报文是1514字节,结果现在被TCP的自动PMTU逻辑推算成了578字节,事实上该路径能承载的报文大小是1514-40=1474字节!这就造成了1474-578=896字节的浪费!
因此,该方案可以让大包不因为不能分片而通过从而保持连接不断开,但是会造成带宽利用率的降低,也不完美。
其实,之所以给出上述两个方案,并且基本上都是在说它们的缺陷,实际上是为了给第三个方案做铺垫,这是业界推崇的方案,即:
- 将MTU设置成IPv6规范规定的最小支持的1280字节。
它基于以下的依据:
来自RFC2460:https://tools.ietf.org/html/rfc2460#section-5

这下有了保底的保证,如果一条链路连1280字节的报文都通不过,那就直接怼ISP吧,它完全不具备部署IPv6的基本条件。
这是 受欢迎 的方案,但是这是 最不负责任 的方案:
- 谢特!链路MTU早就普及1500了,现在却要开历史倒车,退回1280!
我们来看看为什么这么 鲁莽无脑 的方案在业界却如此备受推崇。
原因很简单: 因为它最简单啊,涉及的改动最少啊!
仅仅因为它简单,满足了人们那死不承认的惰性,所以采用了一条逐跳路径上的 可能的但并非事实的 最小瓶颈MTU作为整体的MTU,造成了大量链路资源的浪费!这个和BBR的思想是背道而驰的。
我们简单看一下Why。
- ICMP-Based PMTU事实上很难实施和配置,IPv4几乎很少实施,对于IPv6这简直是一个新东西。
- TCP的PMTU无法解决UDP的问题,甚至很多非TCP的分片问题都无法解决。
- 继续保持1500的MTU,又要迎合兼容IPv6的不能分片,需要软件上的改造。
事实上,没人想改造任何东西!这就是根源。所以,最保守的方案往往就是最保险的方案,除了狂热分子,没人喜欢激进。
然而,其实是IPv4做了它不该做的事,才承担了本来应该由端到端负责的分片功能,这事实上是 帮忙减少了TCP/UDP等四层协议的工作量,友情支持罢了! 现如今,四层协议却将此当成了IP层应该做的!
类似的悲剧我很害怕会在TSO等各种网卡Offload领域产生。
选择1280也只是业界在工程上根据RFC的限定作出的推荐,但也只是一家之谈,用的人多了自然就成了标准,大家跟风,人云亦云,说到底还是因为本来就没有标准。如果IPv6规定所有链路必须全部支持1500的MTU,那么1280这个数字就成了1500,总之,人们按照标准的最宽松下界去设定,就对了。
如果把MTU设置成1280,其它便什么事情都不用做,你要说这会降低带宽利用率,但是who care那么一丢丢。这是个粗放的时代,1500-1280=220,谁会去在意这区区220字节?!
榨取220字节的带宽收益在大多数人看来已经没有意义了,这是互联网的时代,这时代是产品和用户说了算,而不是工程师说了算。220字节,用户买单即可,这无可厚非。
但这不是工程师文化的体现,这反而像是一种销售文化。
统计数据显示,1280这个数字虽然不是一个 长尾下界,但是却也是稀有的下界,但是由于工业界木桶效应使然,人们不得不定义这么一个下界。 可是, 绝大多数IPv6报文由于遇到小MTU链路而被丢弃的原因不是它们真的经过了老式的小MTU链路,而是因为它们经过了软件隧道的封装!
至于上界1500这个值,哈哈,这个只是现如今当前的上界,因为现在使用1500这个MTU的链路太多了(其中也是由于1500是以太网的MTU,而以太网太威风凛凛了的缘故)!正因为这个值和最小下界1280差别不到,只有220字节,所以人们才可以心安理得地拍一个最低下界以确保数据报文不被丢弃。
如果10年以后,链路MTU普遍都是8900了,但是由于木桶效应,1280依然是下界,试问还要使用1280吗?这可是要损失7620字节啊!!也许到了这个时候,人们才会去思考如何去设计一个动态的算法来确定MTU。
说到底,IPv6的MTU问题,就是让人们在两个界限之间作出一个权衡性选择:
- 下界 M T U m i n MTU_{min} MTUmin,即1280:选它意味着资源利用率最低,但通过率最高。
- 上届 M T U m a x MTU_{max} MTUmax,目前1500,未来会更大:选它意味着通过率最低,但资源利用率最高。
所以说, 正确的做法,应该是在1280和 M T U m a x MTU_{max} MTUmax 比如1500之间动态做一个选择。使得 P = 通 过 率 资 源 利 用 率 P=\frac{通过率}{资源利用率} P=资源利用率通过率这个商值最大!
这件事必须通过端到端的探测才能完成,这件事的难度和TCP拥塞控制是一样的,虽然复杂且麻烦,但是我觉得这件事必须要做。
要做的TODO list大致如下:
- 判断何时路由重新收敛到不同的路径,越精确越好
- 判断IPv6报文丢包是因为拥塞,还是因为遇到了小MTU,还是其它
- 如果判断为遇到了小MTU链路,递减报文尺寸,减多少是一个很难确定的问题
- 如果判断为遇到了小MTU链路,也可以oneshot切换到1280的MTU,简单保险
- 如果从含有小MTU链路的路径重新收敛到另外的路径,执行MTU递增,增多少是个问题
所以,我初步先选用Cubic算法。此外,判断路由重新收敛,可以参考下面的point:
- 采集数据并识别Flowlet。
参见 《非常有意思的Flowlet》 https://blog.csdn.net/dog250/article/details/80288664 - 采集RTT,SRTT。
- 采集反向报文TTL的前后变化和方差。
- 结合Flowlet特征,RTT以及TTL方差来确定是否发生了路由重收敛。
换句话说,我是把整条路径的Buffer统一用一个态度对待了,即使用拥塞控制的思路:
- 路由器节点的Buffer:非时间延展缓存,使用BBR避免Bufferbloat。
- 链路MTU:时间延展缓存,使用Cubic探测其全链路瓶颈MTU容量。
泛泛而写,泛泛而谈,因为太复杂。但是复杂确实不是任何人怼它的理由,同时,正是因为目前还没有人去做,也就暂时看不到它的价值,如果说没有价值就不去努力实现它,那么这又是一个不做它的理由。
所以说这个问题本身就是一座围城,但我始终以为,技术问题是肯定能被解决的,技术问题不是设计问题。技术问题没有对错,只有bug!
哦,对了,把MSS改成80会更加 保险和保底!
说了半天,我这里的结论貌似是扯来扯去什么都没有:
- 使用PMTU要改逻辑,使用自动PMTU会影响效率。
- 设置MTU为1280会影响资源利用率。
- 正确的动态探测MTU现在还没有好的算法。
说了半天,貌似我们针对这个MTU导致大包过不去的问题什么都不能做,但这并不是解决问题的方式,为了能使大包过去,目前就先不要考虑资源利用率了,直接设置网卡的MTU为1280即可。
[root@localhost ~]# ip link set dev enp0s3 mtu 1280
直接,粗暴!但不好!这会影响本机从enp0s3这块网卡出去的所有流量,比如IPv4,比如Raw…
我们需要把粒度细化,仅仅对IPv6使能这个1280的MTU,怎么办? 使用路由!
# 找到默认路由的下一跳网关地址
gw=`ip -6 route ls|grep default|cut -d " " -f 3`
# 增加mtu参数,设置为1280
ip -6 route replace ::/0 via $gw mtu 1280
所以,建议每台跑IPv6的设备上都加上上述的配置。此外,除了mtu,还有很多其它参数可以按照路由的粒度来细化配置,比如advmss。我们看看iproute2的route命令相关可配置参数:
不能两全其美就要折中,同时还要在改动最小的前提下把影响限制在最小的范围内,这意味着你要熟悉网络协议栈各个层次的各种工具以及网络协议栈各个层次的实现细节。
近日,埃航空难,人工智能和驾驶员之间对抗导致了悲剧性的结局,令人遗憾,评价之前,先行为遇难者表示哀悼。
但看你怎么看待这件事,在我看来,人工智能完全取代驾驶员是必然的趋势,目前的悲剧只是一个技术问题而不是一个设计问题,仅仅说明目前的技术还不够先进,还远没有达到航空工业级的安全标准,这只是一个bug,但是这个技术bug早晚有一天是会被解决的!
反过来,另一个思路,如果你总觉得人工智能必须辅助以手工操作,比如自动驾驶汽车必须保留驾驶位,那么便永远都不会有所突破,充其量只是把蒸汽机安装在了马车上而已,你永远都会觉得蒸汽机只是一个马车动力的辅助。
技术的能否突破和演进,正是取决于人们能否放弃之前的包袱,忘记过去,彻底推翻现有的逻辑,去拥抱变化,而不要仅仅觉得新技术只是对老技术的改进。然而,拥抱变化的代价,那就是, 你必须作出一点改变,哪怕一点点!
人的心态取决于你是着眼于未来还是着眼于现在,如果是着眼于现在,那么未来的一切将可有可无,充其量只是当前技术的优化。,反过来,如果你着眼于未来,那么现在的一切都将是未来的铺垫。
浙江温州皮湿,下雨进水不会胖!