Linux用户态进程如何监控内存被写事件
上周了解到一个很好玩的问题,即 如何捕获到“一块特定的内存的内容变成某一个特定的值”这么一个事件。
嗯,还是那位暴雨天穿着意尔康皮鞋给我们送伞皮鞋湿了的同事,感谢他能提供一些好玩的东西来折腾。
我并不想快速解决问题,我只是想能多玩一会儿。
正好,也碰到了一个JVM踩内存的问题,就思考了一把,完成了一个简单的demo,可以 监控每一个内存写事件。 至于内存的内容是否变成特定的值,那就在每一次捕获到内存写事件后加以判断呗。
好了,下面开始思路描述。
如果是在Windows平台,这很容易用 结构化异常处理(SEH) 来解决,简单来讲就是 Windows允许应用程序为每一个“可能出现异常”的地方定义一系列的回调函数,当该潜在的异常真的出现时,便会去调用特定的回调函数来处理。
Windows平台上这个牛逼的机制是以下三大件共同支持的:
- 操作系统内核
- 编译器
- 编程语言
现在回到Linux平台。
说实在话,同样作为现代操作系统,Linux远没有Windows先进。Linux依然保持着1980年代4.4BSD现代操作系统的朴素原始特征,而Windows系统则是基于在1996年重新设计的Windows NT 4.0的,这其中存在着明显的技术代差。
所以,当Windows更进一步实现了SEH时,Linux依然在兼容Posix信号机制,所以,要想解本文开始提出的问题,还要从朴素的信号处理入手。
解题思路的第一步,很明显。
将内存设置为不可写,当有某个线程写这块内存时,会触发内核发出SIGSEGV信号指示段错误,而该信号是可以捕获并处理的。
顺着这个思路,下一步,那就是 在SIGSEGV信号处理函数中将该内存恢复可写状态。
【注:为什么系统触发的信号不可忽略?因为此类信号如果忽略了,就会不断触发。】
在SIGSEGV处理中恢复内存可写后,系统会重新尝试完成写操作,在写操作顺利完成后,必须找个机会将内存重新设置为不可写用以捕获下一次的写事件,否则这个机制就是oneshot一次性的。
这里就需要点技巧了。
如果是Windows平台,一个try块就是一个异常处理的基本范围单位:
try {
// 可能触发异常的逻辑
} catch (...){
// 异常处理
}
编译器和操作系统可以识别到try-catch包围着的那块代码区域,并把catch块作为一个异常处理HOOK链到系统的线程控制块中。
我们现在需要的异常处理步骤:
- 写不可写的内存触发SIGSEGV信号。
- 内核将信号处理路由到用户态信号处理HOOK。
- 信号处理HOOK 记录写操作日志 后恢复内存为可写状态,信号处理返回。
- 系统重新写内存,写入成功。
- 重新将该内存设置为不可写状态,以捕获下一次写操作。
- 返回正常的处理逻辑,就好像没有发生异常信号处理一样。
难点在上面第5个步骤!
但是Linux平台普通的GCC编译器和兼容Posix信号的Linux内核,没有机制可以支持它。Linux平台拥有的只有常规的函数调用。换句话说, GCC编译器,操作系统,CPU以函数调用的栈帧来组织逻辑。
- GCC编译器不会对C代码进行预处理,以识别出类似try-catch的块。
- Linux内核在触发信号后不会对异常进行任何前处理和后处理,只是单纯向进程发信号。
- 信号处理基于用户的异常栈帧,这是唯一可以做点事情的地方。
既然系统不会主动帮我们转移逻辑到特定的地方,我们只能靠最原始最朴素的现代微处理器支持的方法自行转移逻辑:
- 替换栈帧下面函数返回的指令!
是的,比较原始,一般栈溢出啥的都利用过这个。
下面是一个例子:
#include 执行结果如下:
[root@localhost make_1]# ./a.out
call function
stub
段错误
可见,执行流没有返回到main函数,而是到了stub_func,至于说为什么后面发生了段错误,我们后面再说。现在明白下面的要点就可以了:
- 替换栈帧rbp下面的返回地址,可以改变函数返回后的执行流!
这意味着,我们要做内存写事件监控,只能做到函数级别!没有编译器和操作系统的原生支持,很难做到比函数粒度更细的try-catch块级别。
我们已经确定了可以利用的机制,接下来我们需要把这一切拼接起来。
花开两朵,各表一枝。下面说说另一个关键的点, Linux的信号处理函数是在触发信号时的栈帧上堆叠的。
这就意味着, 在信号处理函数的栈帧下面一个栈帧,就是触发信号时线程执行流所属的栈帧。在本例中,就是写不可写内存触发SIGSEGV段错误信号的函数所在栈帧。
跳过信号处理函数的栈帧,再跳过触发信号的指令所在函数的栈帧,下面就是该函数的返回地址了。理论上是如此之简单!
可是实际上却不简单!
因为 我们不知道触发信号的指令所在的函数的栈帧有多大!!
如果对处理器执行函数的细节以及编译器的行为有所了解,就可以换个思路,我们实际上不需要知道触发信号的指令所在的栈帧有多大, 我们只需要找到该函数的RBP(32位系统则是EBP)即可!
而这个寄存器是在触发信号陷入内核时包含在寄存器上下文中被保存在进程/线程内核栈了的!记住, 每一个task_struct都会对应有一个内核栈。
Linux的信号处理机制非常巧妙地构建了一个新的信号处理函数栈帧,将这个保存在内核栈的寄存器上下文打包堆叠在了这个栈帧上。它就是 rt_sigframe结构体 :
struct rt_sigframe {
char __user *pretcode;
struct ucontext uc;
struct siginfo info;
/* fp state follows here */
};
其中的uc字段中就包含着触发信号时的寄存器上下文 sigcontext结构体 :
struct sigcontext {
__u64 r8;
__u64 r9;
__u64 r10;
__u64 r11;
__u64 r12;
__u64 r13;
__u64 r14;
__u64 r15;
__u64 rdi;
__u64 rsi;
__u64 rbp;
__u64 rbx;
__u64 rdx;
__u64 rax;
__u64 rcx;
__u64 rsp;
__u64 rip;
__u64 eflags; /* RFLAGS */
__u16 cs;
__u16 gs;
__u16 fs;
__u16 __pad0;
__u64 err;
__u64 trapno;
__u64 oldmask;
__u64 cr2;
struct _fpstate __user *fpstate; /* zero when no FPU context */
#ifdef __ILP32__
__u32 __fpstate_pad;
#endif
__u64 reserved1[8];
};
我们索引它的rbp字段即可。
我来画一下信号处理函数栈帧的大致样子:
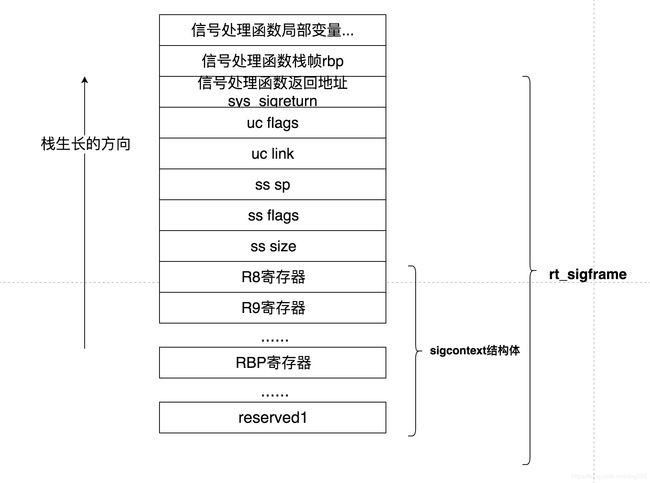
很容易就能索引到触发信号的指令所在函数的栈帧位置,进而替换它的返回地址。我们将其替换为一个 stub函数 ,该stub函数的逻辑有两个:
- 将内存重新设置为不可写,用来捕获下一次内存写事件;
- 跳转到原始的函数返回地址,继续执行常规逻辑。
换句话中,我们需要在触发异常信号的指令所在函数返回时 插入一段我们的stub代码 ,但是执行完这段stub代码后,并不影响程序原有的流程。
在成功找到机制替换函数返回地址之后,这又是一个问题,怎么恢复到程序原有的逻辑。
已经到了这一步,这已经不是事了。任何问题的解决过程都不是一下子解决的,都是一连串的过程,且一般越往后越顺手。
我们可以这么做,stub的半伪不伪的代码如下:
void sig_handler(int signo)
{
...
saved_orig_ret_addr = *(rbp+1);
*(rbp+1) = stub;
mprotect(buff, len, READWRITE);
}
void stub()
{
push %rbp
mprotect(buff, len, READONLY);
// 暂存stub的rbp
pop %r12
move saved_orig_ret_addr, %r13
push %13
push %12
pop %rbp
ret
}
为了验证上面的一系列想法,进而把这一切连接起来。我们先用小测试程序做实验。
我们的实验要完成的事情如下:
- 通过替换函数返回地址改变函数返回后的执行流到stub函数。
- 在stub函数完成额外处理后,重新返回到正常的执行流。
- 一切正常运行,不能有任何报错。
还记得上面的那个发生段错误的小程序吗?为什么会发生段错误呢?
原因很简单,我们替换了func的返回地址后,func就返回到stub_func了,覆盖了func调用的下一条指令之后,在stub_func执行完返回时,没有任何线索可以找到它,所以我们需要替换它之前先保存,然后在stub_func里面恢复它。
于是,现在第二个版本来了:
#include 执行效果如下:
[root@localhost make_1]# ./a.out
call function
stub
function return
段错误
OK,成功返回了main,然而在main返回的时候,段错误了!
Why?
因为堆栈没有平衡导致栈帧被破坏!
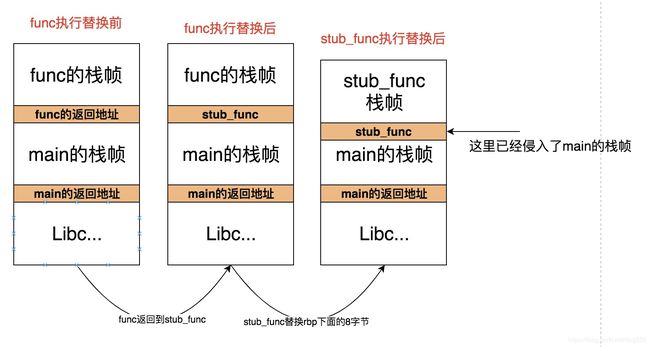
正常来讲,stub_func函数是call指令执行的,call指令会push一个返回地址到栈上,函数返回时ret指令对应pop出这个返回地址并跳转过去。
我们比如明白call和ret指令必须是要配对的,不然就会破坏堆栈的平衡。要理解这个,必须掌握push/pop/call/ret的细节:
push:
sub $8, %rsp
mov SRC, (%rsp)
pop:
mov (%rsp), DST
add $8, %rsp
call:
push %rip
jmp DST
ret:
pop %rip
jmp (%rip)
然而在我们的例子中,stub_func并非call过去的,而是直接通过func的替换后的返回地址直接跳过去的,所以就没有call指令的push操作,然而在ret中却多了一个pop指令,stub_func函数导致堆栈不平衡了!
平衡堆栈这一点非常重要!
如何来做平衡堆栈呢?很简单,基本就是一个关于栈底RBP寄存器,栈顶RSP寄存器的save/restore操作!
于是,第三个版本来了:
#include 执行效果如下:
[root@localhost make_1]# ./a.out
call function
stub
function return
这是一个见招拆招的版本,即stub_func重用了func的栈帧,在stub_func看来,它就像是func的影子。当然,这个版本需要对func函数进行修改,保存其栈寄存器用来在stub_func被重用。
如果不修改func,那么就需要就问题的本质来直击!
少了一个call指令的push,那也少一个pop,直接jmp呗:
#include OK,完美结束!
关于这个话题先暂且结束,在后面正餐之后,关于这个话题还有更多的信息,但这里不展开,后面再说。
对了,还有最后一个问题。那就是 func函数返回值的保存和恢复。
如果stub_func函数仅仅是做一些 “额外” 的工作,它便需要静悄悄地执行,执行完交回控制权的时候,它需要返回func函数原先返回的值。因此,除了保存栈帧寄存器RBP,RSP之外,我们需要保存RAX寄存器的值。事实上,我们需要保存所有寄存器的值!
实验做完了,我们接下来把上面的实验连同我们最终要解决的问题,连同信号的处理,把它们串起来,就解决了本文开头提出的问题了。
我接下来会直接给出代码。
先看一个正常的程序代码 main.c :
#include 执行这个程序的效果如下:
[root@localhost make_1]# ./a.out
curr seq is:2
curr seq is:32
curr seq is:152
0 1 2 3 4 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0
seq:316
但是我们不知道这些写操作是哪个函数做的。
我们发现,有两个函数会操作内存,这还算简单的,如果是个多线程程序,超级多的线程函数操作同一个内存区域,谁在什么时候写入了什么,就很难捕获,因此我们需要监控这块内存的写入情况。
按照上面的实验里说清楚的逻辑,我将其改造成了下面的样子:
#include 还有一小段纯汇编函数,关于它的用途以及为什么要有这段小汇编,我后面会解释。
先看汇编代码:
# stub.S
.data
# 引用C语言变量
.extern saved_return_value
.extern stub_resume
# global相当于export,被C语言引用
.global stub
.text
stub:
# 采用可重定向相对地址,以便作为共享库被使用!
movq saved_return_value@GOTPCREL(%rip), %r13
movq %rax, (%r13)
movq stub_resume@GOTPCREL(%rip), %rax
movq (%rax), %rax
push %rax
retq
现在再来看下效果:
[root@localhost make_1]# gcc pro1.c stub.S
[root@localhost make_1]#
[root@localhost make_1]# ./a.out
caller at 400697 [stack:4006ea] 2
curr seq is:2
caller at 4006c5 [stack:40072d] 10
caller at 400697 [stack:4006ea] 20
curr seq is:32
caller at 4006c5 [stack:40072d] 4c
caller at 400697 [stack:4006ea] 98
curr seq is:152
caller at 4006c5 [stack:40072d] 13c
0 1 2 3 4 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0
seq:316
详细信息全部出来的,栈的信息,指令RIP的信息,等等,当然你还可以把stack也trace出来,非常随意。
现在我来讲一下那一小段汇编的用途。为什么不能在 stub_2 函数的开头用内联汇编来做这种事呢?
我们知道,RAX作为原始函数的原始返回值,需要 第一时间被保存!!
我们在信号处理函数中如果直接把stub函数换成stub_2,那么你能在stub_2里写的第一行内联汇编就已经不是现场了!C编译器会在每一个函数的开头和结尾处做一些 例行 的操作,这个我们从objdump的结果中可以看出来:
0000000000000a35 :
a35: 55 push %rbp
a36: 48 89 e5 mov %rsp,%rbp
a39: 48 8b 05 00 06 20 00 mov 0x200600(%rip),%rax
类似以上的这些操作,都是 C编译器给强行安排的例行操作 。也就是说,当执行到你写的代码的时候,RAX寄存器就已经被touch过了,这便不再是第一现场!
所以我们用纯汇编,我们看看纯汇编的objdump:
0000000000000bf6 :
bf6: 4c 8b 2d d3 03 20 00 mov 0x2003d3(%rip),%r13 # 200fd0
bfd: 49 89 45 00 mov %rax,0x0(%r13)
c01: 48 8b 05 90 03 20 00 mov 0x200390(%rip),%rax # 200f98
c08: 48 8b 00 mov (%rax),%rax
c0b: 50 push %rax
c0c: c3 retq
对比一下纯汇编源文件stub.S,完全一模一样!信可乐也。
到了目前为止,我们基本上解决了问题,但是还可以更进一步。
我们知道,如果要把这种方式变得通用,那就不要去改 new_func1,new_func2 这些函数,当然,我们也没有改它们。
这是不是意味着,我们可以动态地使能或者禁用内存写事件的监控能力呢?既然这么问了,答案当然是肯定的。
我们只需要替换malloc函数的实现即可。用LD_PRELOAD环境变量载入本地动态库即可。
说时迟,那时快,让我来演示一番究竟。
主程序 main.c :
#include 和我们前面的实验程序代码没有任何改变。该代码是可以被编译成可执行程序直接执行的。但是我们希望通过加载一个动态库,在不改变main.c程序的前提下可是实现内存写监控。
如果想使能内存写监控,只需要用自己定义的malloc替换原始的malloc即可。
动态库主程序代码 memchecker.c :
#include 当然,它也有一段小小的纯汇编 stub.S :
.data
.extern saved_return_value
.extern stub_resume
.global stub
.text
stub:
movq saved_return_value@GOTPCREL(%rip), %r13
movq %rax, (%r13)
movq stub_resume@GOTPCREL(%rip), %rax
movq (%rax), %rax
push %rax
retq
一共3个文件,为了统一编译生成,我这里有个写的很low逼的完全是bash命令封装的Makefile:
all:
gcc -fPIC -c stub.S
gcc -fPIC -c memchecker.c
gcc -fpic memchecker.o stub.o -shared -o libmemchecker.so
gcc main.c -o main
rm -f *.o
start:
LD_PRELOAD=$(PWD)/libmemchecker.so ./main
clean:
rm -f *.o *.so main
值得注意⚠️的是,我们没有改 new_func1,new_func2 ,这很OK,但是共享库里 stub_resume_perm函数 的栈帧平衡方法 却不通用! 这意味着,在你的环境里,这个代码可能并不能符合预期。我们看看为什么。
先看stub_resume_perm函数栈帧平衡的方法:
// 用r12,r13寄存器保存原始调用
asm ( "movq %%r12, %0 \n\t"
"movq %%r13, %1 \n\t"
"popq %%r12 \n\t"
"movq %2, %%r13 \n\t"
"pushq %%r13 \n\t"
"pushq %%r12 \n\t"
: "=m"(r12), "=m"(r13)
: "m" (var));
// 恢复原始函数返回值
asm ( "movq %0, %%r12 \n\t"
"movq %1, %%r13 \n\t"
"movq %2, %%rax \n\t"
"popq %%rbp \n\t"
"retq \n\t"
:
: "m" (r12), "m" (r13), "m" (saved_return_value));
之所以上面的方法能奏效,那是因为 new_func1,new_func2 并没有伸展自己的栈帧:
000000000040055d :
40055d: 55 push %rbp
40055e: 48 89 e5 mov %rsp,%rbp
400561: 89 7d fc mov %edi,-0x4(%rbp)
400564: 89 75 f8 mov %esi,-0x8(%rbp)
400567: 48 8b 15 d2 0a 20 00 mov 0x200ad2(%rip),%rdx # 601040
40056e: 8b 05 d4 0a 20 00 mov 0x200ad4(%rip),%eax # 601048
400574: 48 98 cltq
400576: 48 01 c2 add %rax,%rdx
400579: 8b 05 c9 0a 20 00 mov 0x200ac9(%rip),%eax # 601048
40057f: 88 02 mov %al,(%rdx)
400581: 8b 45 fc mov -0x4(%rbp),%eax
400584: 01 c0 add %eax,%eax
400586: 5d pop %rbp
400587: c3 retq
这意味着,栈顶部就是RBP的值,stub_resume_perm函数便可以通过:
- 弹出栈顶
- 压入原始返回值
- 压入栈顶
这三个步骤来完成栈的平衡。然而,一般情况下,函数对栈帧的操作不是这样的,而是如下:
0000000000400559 :
# 栈帧pre操作
400559: 55 push %rbp
40055a: 48 89 e5 mov %rsp,%rbp
40055d: 48 83 ec 10 sub $0x10,%rsp # 栈帧的伸展!
..... # 函数的正式逻辑
# 栈帧post操作
4005a0: c9 leaveq
4005a1: c3 retq
我们上述的实验代码中,就是这种方式,关键在于:
sub $0x10,%rsp
如果是这样,在C代码中我们就无法在编译前获取伸展的大小,也就无法在函数返回前对堆栈进行平衡。
如果如此,那么在动态库版本的代码中,不修改原始被监控函数的前提下,stub_resume_perm函数便需要自己 第一时间创建自己的栈帧! 也就是完成:
# 栈帧pre操作
400559: 55 push %rbp
40055a: 48 89 e5 mov %rsp,%rbp
40055d: 48 83 ec 10 sub $XXX,%rsp # XXX 视函数而定
为了第一时间,就不能依赖编译器,这就又要用到纯汇编了。 保险起见,stub_resume_perm要用纯汇编编写
但是写纯汇编除了在外行人前炫技巧之外并不是一件特别有技术含量的事。我们还是希望用C和内联汇编来完成。
好吧,除了上述实验代码的最后一个版本之外,这里还有一个版本:
#include 最后关于这个话题,还有一个细节问题: 什么时候伸展栈帧,什么时候不伸展栈帧呢?
这里抛一块砖:
- 叶子函数使能no-red-zone编译选项时会不伸展栈帧。【关于red zone的介绍,自行wiki】
- 没有局部变量或者unused局部变量的函数会不伸展栈帧。
看一个例子:
int no_local_var(int a)
{
return a + 2;
}
int unused_local_var(int a)
{
int b;
return a + 2;
}
int local_var(int a)
{
int b = 9;
no_local_var(b);
return a + b;
}
不再详细解释,我们用 “-O0” 编译,objdump获取其汇编指令:
0000000000000000 :
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 89 7d fc mov %edi,-0x4(%rbp)
7: 8b 45 fc mov -0x4(%rbp),%eax
a: 83 c0 02 add $0x2,%eax
d: 5d pop %rbp
e: c3 retq
000000000000000f :
f: 55 push %rbp
10: 48 89 e5 mov %rsp,%rbp
13: 89 7d fc mov %edi,-0x4(%rbp)
16: 8b 45 fc mov -0x4(%rbp),%eax
19: 83 c0 02 add $0x2,%eax
1c: 5d pop %rbp
1d: c3 retq
000000000000001e :
1e: 55 push %rbp
1f: 48 89 e5 mov %rsp,%rbp
22: 48 83 ec 18 sub $0x18,%rsp
26: 89 7d ec mov %edi,-0x14(%rbp)
29: c7 45 fc 09 00 00 00 movl $0x9,-0x4(%rbp)
30: 8b 45 fc mov -0x4(%rbp),%eax
33: 89 c7 mov %eax,%edi
35: e8 00 00 00 00 callq 3a
3a: 8b 45 fc mov -0x4(%rbp),%eax
3d: 8b 55 ec mov -0x14(%rbp),%edx
40: 01 d0 add %edx,%eax
42: c9 leaveq
43: c3 retq
非常简单,自己体会。
当本文激昂的内容快要收尾的时候,我要给所谓企图使用 栈保护机制 的泼一盆冷水。
也许你会认为只要一个gcc编译选项,上面所有的机制将全部失效。该gcc选项就是 -fstack-protector :
-fstack-protector
Emit extra code to check for buffer overflows, such as stack smashing attacks. This is done by adding a guard variable to functions with vulnerable objects. This includes functions
that call “alloca”, and functions with buffers larger than 8 bytes. The guards are initialized when a function is entered and then checked when the function exits. If a guard check
fails, an error message is printed and the program exits.
-fstack-protector-all
Like -fstack-protector except that all functions are protected.
-fstack-protector-strong
Like -fstack-protector but includes additional functions to be protected — those that have local array definitions, or have references to local frame addresses.
-fstack-protector-explicit
Like -fstack-protector but only protects those functions which have the “stack_protect” attribute.【最后这个好玩】
看一个例子。
先看源代码:
int test()
{
return 3;
}
我们先什么参数都不带常规编译后,看看objdump的汇编:
0000000000000000 :
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: b8 03 00 00 00 mov $0x3,%eax
9: 5d pop %rbp
a: c3 retq
很简单,很清晰。
现在,用 -fstack-protector-all 修饰编译选项,再看结果:
0000000000000000 :
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp
8: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
f: 00 00
11: 48 89 45 f8 mov %rax,-0x8(%rbp)
15: 31 c0 xor %eax,%eax
17: b8 03 00 00 00 mov $0x3,%eax
1c: 48 8b 55 f8 mov -0x8(%rbp),%rdx
20: 64 48 33 14 25 28 00 xor %fs:0x28,%rdx
27: 00 00
29: 74 05 je 30
2b: e8 00 00 00 00 callq 30
30: c9 leaveq
31: c3 retq
OK,在栈上直接插入了一个随机数。然而这只是用来防止栈溢出的,而栈溢出只是鲁莽的大摆拳。
然而我们这里是 使用汇编 精准地替换栈上的某个地址的内容,stack-protector将完全失效!况且,我们可以用汇编修改这个随机数或者干脆将它移除!
我们来看一下:
#include 执行结果如下:
[root@localhost make_1]# gcc -fstack-protector-all gaurd.c
gaurd.c: 在函数‘main’中:
gaurd.c:31:7: 警告:赋值时将指针赋给整数,未作类型转换 [默认启用]
orig = stub_func;
^
[root@localhost make_1]#
[root@localhost make_1]# ./a.out
call function
stub
段错误
完全被绕过!这就是所谓的降维打击!JNI不是也可以对JVM进行降维打击吗?汇编当然也可以对任何C代码以及携带的C编译选项进行降维打击!层次不同,底层对细节把控力更强。
好了,结束了!
下面的内容是程序员最不喜欢的形而上的东西。
以上的篇幅,通篇都在使用内联汇编,纯汇编与C语言混合编程。为什么要用汇编?
因为C语言无法操作寄存器!而涉及很多 非常规逻辑跳转 的,都需要寄存器协助,最简单的方法就是,使用汇编!
汇编于C/C++的内联汇编,正如C/C++于Java的JNI! 你看,它们多么得像!
Java比C更在上层,C比汇编更在上层,每提高一个抽象层,在得到 通用性收益 的同时,付出的是 本地功能丧失的代价。
说到降维打击,有一首歌叫做《咱们工人有力量》,其实工人不光有力量干活,还有力量打经理,打老板,因为工人更底层,工人靠的就是纯粹的力量,而更上层的经理更多地是靠逻辑和规则,然而规则嘛,在底层看来,就是用来被违背的。力量可以绕开任何规则,直击经理的西装。
另外,小区物业打业主也同样。秀才遇到兵有理说不清,不用说理,跑或者求饶就是了,不在一个层次。
好了,说回汇编。
必须用内联汇编吗?问这话就像问Java的某个功能必须JNI实现吗?比如不规则GUI组件。对于Java,Java Swing可以不借助JNI实现自己绘制的不规则组件。对于C,能实现控制函数返回值的完美跳转吗?
能!但不直观!
想想看,哪些C语言机制,可以改变RBP,RSP的?貌似没有!因为寄存器对C语言根本就不可见。
那么,有没有哪些封装好的C函数可以做到操作寄存器呢?大大的有啊! setjmp/longjmp 就可以, swapcontext 也可以!
这么点一笔觉得不过瘾吗?想知道究竟?看看下面三篇文章,嗯,整整一个月前写的:
Linux C实现纯用户态抢占式多线程! https://blog.csdn.net/dog250/article/details/89642905
Linux C实现用户态协作式多线程! https://blog.csdn.net/dog250/article/details/89709706
彻底理解setjmp/longjmp并DIY一个简单的协程 https://blog.csdn.net/dog250/article/details/89742140
如果Java调用本地代码叫做JNI,那么C的内联汇编,就叫CNI吧~~
文章写了四个小时了,没啥思路了…总结收尾一下。后续再勘误,再补充。
若干年前,我就在想,如果Linux下能有一种操作系统级别的异常处理框架该有多好。
当我知道类似Windows的SEH在Linux并不支持的时候,我就觉得好玩的东西来了。
我并不想快速解决问题,我只是想能多玩一会儿。
如果一个try-catch块就能搞定的事情,我是不会去写这篇文章的,但凡我写的这些东西,都是比较折腾的东西。
有意思,比较折腾但不重复的事还是希望有人能多多提供。
浙江温州皮鞋湿,下雨进水不会胖!!!