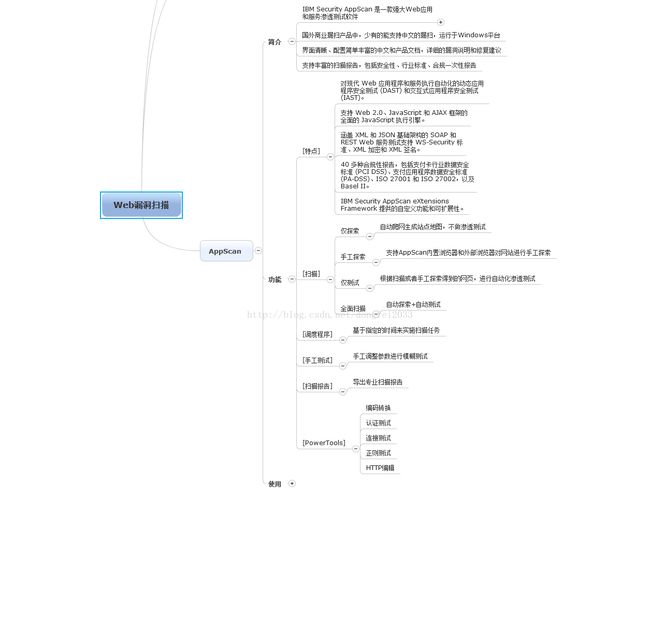
商业web漏扫神器——appscan篇
很快,已经到了三大商业漏扫的最后你一个了
burpsuite高扩展性,APPscan报告输出能力强,漏洞处理建议完备,AWVS的webscan 功能强大且操作傻瓜、方便
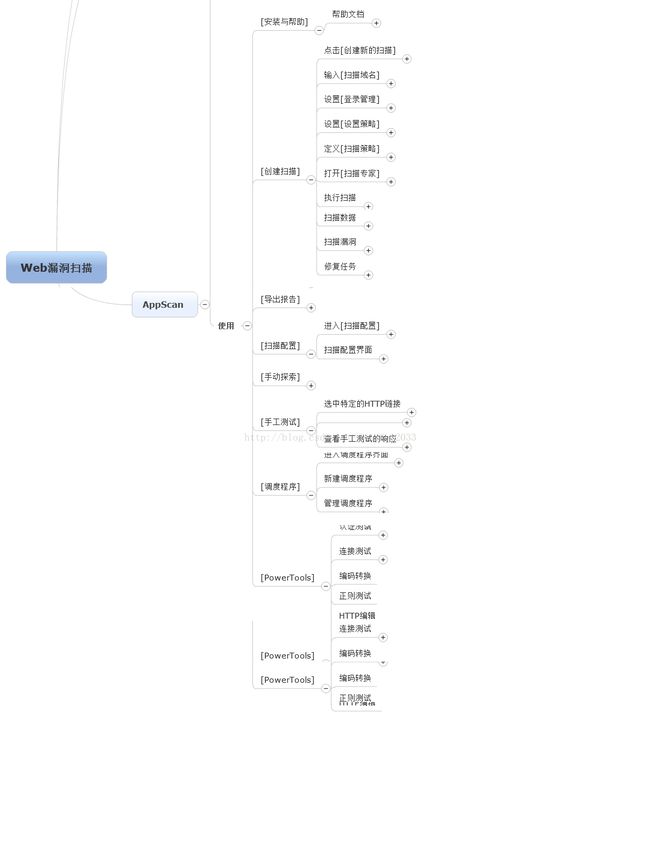
下面将按照以下几个部分展开

由于图片篇幅过大,不一一展开,其实工具里面的帮助文档已经很详细了
AppScan其实是一个产品家族,包括众多的应用安全扫描产品,从开发阶段的源代码扫描的AppScan source edition,到针对WEB应用进行快速扫描的AppScan standard edition.以及进行安全管理和汇总整合的AppScan enterprise Edition等,我们经常说的AppScan就是指的桌面版本的AppScan,即AppScan standard edition.其安装在Windows操作系统上,可以对网站等WEB应用进行自动化的应用安全扫描和测试。
使用AppScan来进行扫描
我们按照PDCA的方法论来进行规划和讨论; 建议的AppScan使用步骤:PDCA: Plan,Do,check, Action and Analysis.
计划阶段:明确目的,进行策略性的选择和任务分解。
1) 明确目的:选择合适的扫描策略
2) 了解对象:首先进行探索,了解网站结构和规模
3) 确定策略:进行对应的配置
a) 按照目录进行扫描任务的分解
b) 按照扫描策略进行扫描任务的分解
执行阶段:一边扫描一遍观察
4) 进行扫描
5) 先爬后扫(继续仅测试)
检查阶段(Check)
6) 检查和调整配置
结果分析(Analysis)
7) 对比结果
8) 汇总结果(整合和过滤)
AppScan的工作原理
当我们单击“扫描”下面的小三角,可以出现如下的三个选型“继续完全扫描”,“继续仅探索”,“继续仅测试“,有木有?什么意思? 理解了这个地方,就理解了AppScan的工作原理,我们慢慢展开:
还没有正式开始,所以先不管“继续“,直接来讨论’完全扫描”,“仅探索”,“仅测试”三个名词:
AppScan是对网站等WEB应用进行安全攻击,通过真刀真枪的攻击,来检查网站是否存在安全漏洞;既然是攻击,肯定要有明确的攻击对象吧,比如北约现在的对象就是卡扎菲上校还有他的军队。对网站来说,一个网站存在的页面,可能成千上万。每个页面也都可能存在多个字段(参数),比如一个登陆界面,至少要输入用户名和密码吧,这就是一个页面存在两个字段,你提交了用户名密码等登陆信息,网站总要有地方接受并且检查是否正确吧,这就可能存在一个新的检查页面。这里的每个页面的每个参数都可能存在安全漏洞,所有都是被攻击对象,都需要来检查。
这就存在一个问题,你领命来检查一个网站的安全性,这个网站有多少个页面,有多少个参数,页面之间如何跳转,你可能很不明确,如何知道这些信息? 看起来很复杂,盘根错节;那就更需要找到那个线索,提纲挈领; 那就想一想,访问一个网站的时候,我们需要知道的最重要的信息是哪个?网站主页地址吧? 从网站地址开始,很多其他频道,其他页面都可以链接过去,对不对,那么可不可以有种技术,告诉了它网站的入口地址,然后它“顺藤摸瓜”,找出其他的网页和页面参数? OK,这就是”爬虫” 技术,具体说,是”网站爬虫“,其利用了网页的请求都是用http协议发送的,发送和返回的内容都是统一的语言HTML,那么对HTML语言进行分析,找到里面的参数和链接,纪录并继续发送之,最终,找到了这个网站的众多的页面和目录。这个能力AppScan就提供了,这里的术语叫“探索”,explorer,就是去发现,去分析,了解未知的,记录。
在使用AppScan的时候,要配置的第一个就是要检查的网站的地址,配置了以后,AppScan就会利用“探索”技术去发现这个网站存在多少个目录,多少个页面,页面中有哪些参数等,简单说,了解了你的网站的结构。
“探索”了解了,测试的目标和范围就大致确定了,然后呢,利用“军火库”,发送导弹,进行安全攻击,这个过程就是“测试”;针对发现的每个页面的每个参数,进行安全检查,检查的弹药就来自AppScan的扫描规则库,其类似杀毒软件的病毒库,具体可以检查的安全攻击类型都在里面做好了,我们去使用即可。
那么什么是“完全测试呢”,完全测试就是把上面的两个步骤整合起来,“探索”+ “测试”;在安全测试过程中,可以先只进行探索,不进行测试,目的是了解被测的网站结构,评估范围; 然后选择“继续仅测试”,只对前面探索过的页面进行测试,不对新发现的页面进行测试。“完全测试”就是把两个步骤结合在一起,一边探索,一边测试。
上图更容易理解:
步骤1:探索(爬行,爬网)
步骤2:真对找到的页面进行测试,生成安全攻击
AppScan扫描大型网站
经常有客户抱怨,说AppScan无法扫描大型的网站,或者是扫描接近完成时候无法保存,甚至保存后的结果文件下次无法打开?;同时大家又都很奇怪,作为一款业界出名的工具,如此的脆弱?是配置使用不当还是自己不太了解呢?我们今天就一起来讨论下AppScan扫描大型网站会遇到的问题以及应对。
什么叫大型网站,顾名思义,网站规模大,具体说是页面很多,内容很全。比如www.sina.com.cn,比如http://music.10086.cn/,都包括上万个页面。而且除了这个,可能还有一个特点---页面参数多,即要填写的地方多,和用户的交互多;比如一个网站如果都是静态页面(.html,.jpg等),没有让用户输入的地方,那么可以利用,可以作为攻击点的地方也就不多。如果页面到处都是有输入,有查询,要求用户来参与的,你输入的越多,可能泄露的信息也越多,可能被别人利用的攻击点也就越多,所以和页面参数也是有关系的。AppScan声称测试用例的时候,也是根据每个参数来产生的,简单说,如果一个参数,对应了200个安全攻击测试用例,那么一个登陆界面至少就对应400个了,为什么?登陆界面至少有用户名和密码两个字段吧? 每个字段200个攻击用例。
这个简单吧,还可以更复杂:如果遇到下面的两个地址,那要扫描多少次呢?
http://www.cnblogs.com/fnng/focus/satisfy/file.jsp?id=1
http://www.cnblogs.com/fnng/focus/satisfy/file.jsp?id=2
上面的两个地址有类似的,“?”号以前的URL地址完全一样,”?”号后面带的参数不同,这种可以认为是重复页面,那么对于重复页面,是否要重复测试呢?
这取决于“冗余路径设置”,默认的是最多测试5次;即,这种类型URL出现的前5次,那么就是要测试1000个攻击用例了。
如果再继续修改下:遇到下面的URL呢
http://www.cnblogs.com/fnng/focus/satisfy/file.jsp?id=1&Item=open
http://www.cnblogs.com/fnng/focus/satisfy/file.jsp?id=2&Item=close
每个URL里面都有2个参数,测试的次数就更多了。想象下,如果这个网页里面的参数如果是10个,或者更多的呢?比如很多网站提交注册信息的时候,要填写的内容足够多吧?
要进行的安全测试用例也就随之不断增加…
这是网站规模的影响,还有一个问题,就出在“每个参数,发送200个安全测试用例”这个假设上。这个假设的前提来源于哪里? 来源于我们选择的扫描规则库。即你关心那些安全威胁,这个需要在测试策略里面选择。同样来参照杀毒软件,你会用杀毒软件来查找一些专用的病毒吗,比如CIH,比如木马;应用安全扫描也是一样的道理,如果有明确的安全指标或者安全规则范围,那么就选择之。这些可能来源于企业的规范,来源于政府的法律法规。就要根据你的理解,在这里选择。
很多时候,我们也很难在最开始的阶段,就把扫描规范制定下来,按照项目经理们的口头禅“渐进明细”,“滚动式规划”,在实践中,更多时候也是摸着石头过河,选择了一个扫描策略,然后根据结果分析,看是否需要调整,不断优化。比如选择默认的“缺省值’扫描策略,对网站进行扫描,发现其”敏感信息“里面会去检查页面上是否含有Email地址,是否含有信用卡号码等,如果我们觉得这些信息,显示在页面上是正常的业务需要, 我们就可以取消掉这些规则,所以扫描规则也很大程度上影响着我们的扫描效率。