The Universal Recommender
The Universal Recommender (UR) is a new type of collaborative filtering recommender based on an algorithm that can use data from a wide variety of user taste indicators—it is called the Correlated Cross-Occurrence algorithm. Unlike the matrix factorization embodied in things like MLlib's ALS, The UR's CCO algorithm is able to ingest any number of user actions, events, profile data, and contextual information. It then serves results in a fast and scalable way. It also supports item properties for filtering and boosting recommendations and can therefor be considered a hybrid collaborative filtering and content-based recommender.
The use of multiple types of data fundamentally changes the way a recommender is used and, when employed correctly, will provide a significant increase in quality of recommendations vs. using only one user event. Most recommenders, for instance, can only use "purchase" events. Using all we know about a user and their context allows us to much better predict their preferences.
用户单一行为举例
| User | Action | Item |
|---|---|---|
| u1 | view | t1 |
| u1 | view | t2 |
| u1 | view | t3 |
| u1 | view | t5 |
| u2 | view | t1 |
| u2 | view | t3 |
| u2 | view | t4 |
| u2 | view | t5 |
| u3 | view | t2 |
| u3 | view | t3 |
| u3 | view | t5 |
整理后得到以下关系:
u1=> [ t1, t2, t3, t5 ]
u2=> [ t1, t3, t4, t5 ]
u3=> [ t2, t3,t5 ]
个性化推荐的一般模型
$r=(P^{T}P)h_{p}$
- $r=rcommendations$
-
$h_{p}$= 某一用户的历史动作(比如购买动作)
- $h_{u1}=\begin{bmatrix}1 & 1 & 1 & 0 & 1\end{bmatrix}$
- $h_{u2}=\begin{bmatrix}1 & 0 & 1 & 1 & 1\end{bmatrix}$
- …
-
针对某个item的动作在史来情况下是有可能重复的,如果表达???
$h_{u1}=\begin{bmatrix}1 & 2 & 1 & 0 & 1\end{bmatrix}$ 2代表了购买item2两次
如果这么表示,那么问题来了,近期的动作和久远的动作,意义是不同的。偶尔受伤买个了拐,是不能根据这个动作就推荐拐的,LLR是不是可以消减这类情况呢?
-
$P$ = 历史所有用户的主动作(主事件)构成的矩阵
- primary action:主动作在COO模型下才有意义,单一指标推荐,就无所谓主动作了。
- 行代表矩阵, 列代表items
$P=\begin{bmatrix}1 & 1 & 1& 0 & 1\\ 1 & 0 & 1 & 1 &1 \\ 0& 1& 1 & 0 & 1\end{bmatrix}$
-
$(P^{T}P)$ = compares column to column using log-likelihood based correlation test
- $P=\begin{bmatrix}1 & 1 & 1& 0 & 1\\ 1 & 0 & 1 & 1 &1 \\ 0& 1& 1 & 0 & 1\end{bmatrix}$ $P^{T}=\begin{bmatrix}1 & 1 &0 \\ 1& 0 & 1\\ 1& 1 &0 \\ 0&1 & 1\\ 1& 1 &1 \end{bmatrix}$ $P^{T}\cdot P=\begin{bmatrix}- & 1 & 2 & 1 & 2\\ 1& - & 2 &0 &2\\2& 2& - & 1 &3 \\1& 0 & 1 & - &1\\2&2&3&1 & -\end{bmatrix}$ $P^{T}代表矩阵转置$
- 其中$P^{T}\cdot P$ 中元素$C_{3,5}=3$ 代表有三个用户浏览$t_{3}$ 的用户同时浏览了$t_{5}$
COOCCURRENCE WITH LLR
-
Let's call ($P^{T}P$) an indicator matrix for some primary action like purchase
- Rows = items, columns = items, element = similarity/correlation score
- The score is row compared to column using a "similarity" or "correlation" metric
-
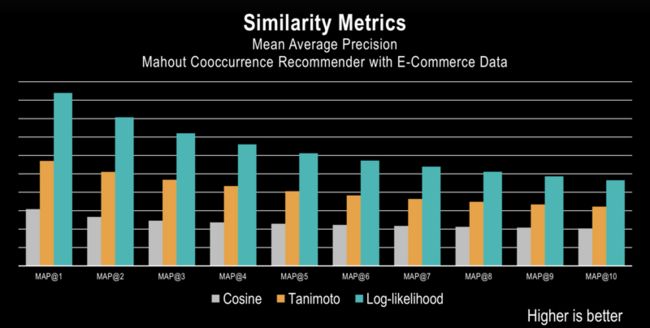
Log-likelihood Ratio(LLR对数似然比) finds important/correlating cooccurrences and filters out the rest —a major improvement in quality over simple cooccurrences or other similarity metrics.
根据两个事件的共现关系计算LLR值,用于衡量两个事件的关联度:
$P^{T}\cdot P=\begin{bmatrix}- & 1 & 2 & 1 & 2\\ 1& - & 1 &1 &1\\2& 1& - & 1 &2 \\1& 1 & 1 & - &1\\2&1&2&1 & -\end{bmatrix}\overset{LLR}{\rightarrow}\begin{bmatrix}-& 1.05 & 3.82 & 1.05 &3.82 \\ 1.05 & - &1.05 &1.05 &1.05 \\ 3.82& 1.05 & - & 1.05&3.82 \\1.05&1.05 &1.05 & - &1.05 \\3.82& 1.05 & 3.82 & 1.05&-\end{bmatrix}$
注意:我们发现每个用户都有点击广告a4,但a4的LLR值却是0,也就是a4跟任何帖子都没有关联,这看上去很奇怪。但其实这是LLR的特点,LLR对于热门事件有很大的惩罚,简单来说它认为浏览t1和点击广告a4这两个事件共同发生的原因不是因为浏览t1和点击a4有关联,而仅仅只是因为点击a4本身是一个高频发生的事件。
- Experiments on real-world data show LLR is significantly better than ohter similarity metrics
LLR AND SIMILARITY METRICS PRECISION (MAP@K)
FROM COOCCURRENCE TO RECOMMENDATION
$r=(P^{t}P)h_{p}$
- This actually means to take the user's history $h_{p}$ and compare it to rows of the cooccurrence matrix $(P^{t}P)$
$h_{p}$ =P动作历史行为
- TF-IDF weigthing of cooccurrence would be nice to mitigate the undue influence of popular items
- Find items nearest to the user's history
- Sort these by similarity strength and keep only the highest — you have recommendations
- Sound familair? Find the k-nearest neighbors using cosine and TF-IDF?
- That's exactly what a search engine does!
USER HISTORY + COOCCURRENCES + SEARCH = RECOMMENDATIONS
$r=(P^{t}P)h_{p}$
- The final calculation uses $h_{p}$ as the query on the Cooccurrence matrix $(P^{T}P)$ , returns a ranked set of items
- Query is a "similarity" query, not relational or key based fetch
- Uses Search Engine as Cosine-based K-Nearest Neighbor(KNN) Engine with norms and TF-IDF weighting
- Highly optimized for serving these queries in realtime
- Serveral (Solr,Elasticsearch) have High Availability , massively scalable clustered auto-sharding features like the best of NoSQL DBs
UR的突破性思想
- 几乎所有的协同过滤推荐仅仅根据一个偏好指标计算所得:
$r=(P^{t}P)h_{p}$
-
基于 CCO 的协同过滤推荐可以表示为:
$r=(P^{T}P)h_{p}+(P^{T}V)h_{v}+(P^{T}C)h_{c}+…$
- $(P^{T}P)$ =P与P的关联矩阵 $ (P^{T}V)$ =P与V的关联矩阵
- $(P^{T}V)h_{v}+(P^{T}C)h_{c}$ 代表了CROSS-OCCURRENCE
- $h_{p}$ =P动作历史行为 $h_{v}$ =V动作历史行为
- 基于COO推荐,只要我们能够想到的用户指标都可以提升推荐效果—购买行为,观看行为,类别偏好,位置偏好,设备偏好,用户性别...
CORRELATED CROSS-OCCURRENCE: SO WHAT?
- Comparting the history of the primary action to other actions finds actions that lead to the one you want to recommend
-
Given strong data about user preferences on a general population we can also use
- items clicked
- terms searched
- categories viewed
- items shared
- people followed
- items disliked (yes dislikes may predict likes)
- location
- device perference,设备偏好
- gender
- age bracket,年龄段, people in the 10~20 age bracket
- Virtually any anything we know about the population can be tested for correlation and used to predict a particular users preferences
CORRELATED CROSS-OCCURRENCE; ADDING CONTENT MODELS
-
Collaborative Topic Filtering
- Use Latent Dirichlet Allocation(LDA) to model topics directly from the textual content
- Calculate based on Word2Vec type word vectors instead of bag-of-words analysis to boost quality
- Create cross-occurrence indicators from topics the user has preferred
- Repeat periodically
-
Entity Preferences:
- Use a Named Entity Recognition(NER) system to find entities in textual content
- Create cross-occurrence indicators for these entities
- Entities and Topics are long lived and richly describle user interests, these are very good for use in the Universal Recommender
THE UNIVERSAL RECOMMENDER ADDING CONTENT-BASED RECS
Indicators can also be based on content similarity
$r=(TT^{t})h_{t}+I\cdot L$
$(TT^{t})$ is a calculation that compares every 2 documents to each other and finds the most similar—based upon content alone
INDICATOR TYPES
-
Cooccurences
- Find the best indicator of a user preference for the item type to be recommended: examples are "buy", "read", "video_watch", "share", "follow", "like"
-
Cross-occurrence
- Item metadata as "user" preference, for example : treat item category as a user category-preferences
- Calculated from user actions on any data that may give information about user— category-preferences, search terms, gender, location
- Create with Mahout-Samsara
SimilarityAnalysis.cooccurences
-
Content or metadata
- Content text, tags, categories, description text , anything describing an item
- Create with Mahout-Samsara
SimilarityAnalysis.rowSimilarity
-
Intrinsic
- Popularity rank, geo-location, anyting describing an item
- Some may be derived from usage data like popularity rank , or hotness
- Is a known or specially calculated property of the item
THE UNIVERSAL RECOMMENDER AKA THE WHOLE ENCHILADA
"Universal" means one query on all indicators at once
$r=(P^{T}P)h_{p}+(P^{T}V)h_{v}+(P^{T}C)h_{c}+…(TT^{T}h_{t})+I\cdot L$
Unified query:
- purchase-correlator: users-history-of-purchase
- view-correlator: user-history-of-views
- category-correlator: user-history-of-categories-viewed
- tags-correlator: user-history-of-purchases
- geo-location-correlator: user-location
- ...
Once indicators are indexed as search fields this entire equation is a single query
Fast!
THE UNIVERSAL RECOMMENDER: BETTER USER COVERAGE
- Any number of user actions — entire user clickstream
- Metadata—from user proflie or items
- Context— on-site, time, location
- Content— unstructured text or semi-structured categorical
- Mixes any number of "indicators" to increase quality or tune to specific context
-
Solution to the "cold-start" problem—items with too short a lifespan or new users with no history
how to solve ??
- Can recommend to new users using realtime history
- Can use new interaction data from any user in realtime
- 95% implemented in Universal Recommender
v0.3.0—most current release
POLISH THE APPLE
- Dithering for auto-optimize via explore-exploit:
Randomize some returned recs, if they are acted upon they become part of the new training data and are more likely to be recommended in the future
-
Visibility control:
- Don't show dups, blacklist items already shown
- Filter items the user has already seen
- Zero-downtime Deployment: deploy prediction server once the hot-swap new index when ready
- Generate some intrinsic indicators like hot, populay— helps solve the "cold-start" problem
- Asymmetric train vs query—query with most recent user data, train on all historical data
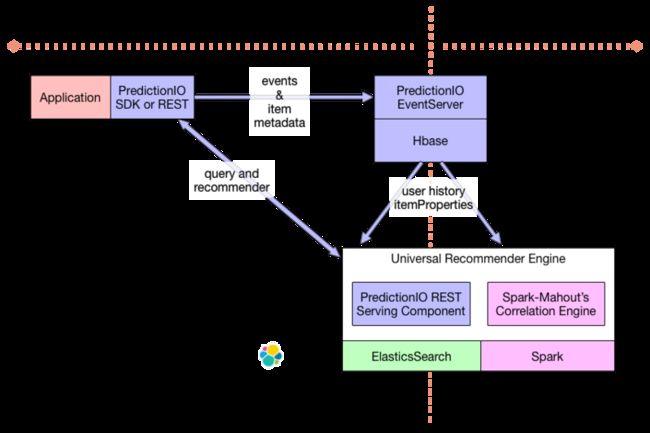
基于PredictionIO的UR推荐架构
参考
- http://ssc.io/wp-content/uploads/2011/12/rec11-schelter.pdf
- http://actionml.com/docs/ur
- http://hejunhao.me/archives/1083