基于Keras框架搭建Salient Object Detection模型踩坑之路
定下方向,开始干!
接下来将是较长一段时间的踩坑之路,从零开始,读论文,写代码,记录坑点,以防再次掉进去。
持续更新......
1. 敲代码之前需要注意的问题:
决定了,本CV小白想用Keras框架,后端使用TensorFlow,IDE就用Pycharm,最好用,不接受反驳哈哈。
这里安利一本书《Python 深度学习》,以及Keras中文文档,链接:https://keras-cn.readthedocs.io/en/latest/,有这俩,差不多搭建一个简单的无脑模型是够用了的。
另外,如果要长时间做科研,建议给每一个项目单独设置一个Python运行环境,防止你的项目太多了,环境冲突。比如我就用了virtualenv,给个教程,自己写的,巨简单:https://blog.csdn.net/Dorothy_Xue/article/details/84111775。也可以在用Pycharm创建项目时,在解释器那里搞一下。
多读点论文,张张知识,了解当前方向做到啥程度了,起码最新的那些比较受关注的工作要了解一下。
2. coding时踩过的坑,长征之路开启( 手动按一下超大Enter键
1. 首先遇到的问题就是数据集。数据集有好多的,一扫一大堆。那么问题来了,网上荡下来的那么多数据集,每个数据集的文件夹乱七八糟的,你看


总而言之呢就是一点不统一,你需要把它弄的规范点,划分一下,手动一张一张来那就太不现实了,还是发挥你的代码能力,就当练练手对不,写个代码划分一下,很快就好了。划分成什么样子呢?这样:
- train_img, train_gt
- validation_img, validation_gt
- test_img, test_gt
又整洁又好看,方便模型调用数据,nice。
2. 对着书搭模型时,书上的一看就懂,用到自己的任务里一写就错,脑阔疼,坑很多,许多没有注意到的事。比如,模型的输入。可能对着书,就是简单的调用一下train_data, train_label这样,因为这些数据在keras中人家都已经给你弄好了,你只知道模型需要接收的输入是张量,要存在Numpy数组中(划重点,这个从来没有搭过模型的人真不一定知道,看了书也容易忽略,比如在下)。
另外!把数据送进模型进行训练之前!要记得!归一化一下!(又是小白踩过的一个大坑)因为读取图片数据得到的范围是在0-255之间,GT也是0和255,但是为了模型训练方便,加速收敛,要归一化,不然就我没归一化过的模型来看,loss竟然是负数,负好几百,精度巨低,跟0没差。所以要预处理一下实验数据!就是除一下255归一化到[0,1]之间就好了,easy。
3. 关于优化器,书上各种安利RMSprop,虽然好,但是前辈说像图像显著性检测就不要用RMSprop了,因为这个在有LSTM这样的结构的模型中表现更好,图像显著性就用Adam就好了。
4. 关于Deconv2D。反卷积时卷积核大小要能被步长整除!不然容易出现棋盘效应。给个链接了解一下棋盘效应:https://blog.csdn.net/Dorothy_Xue/article/details/79844990,因为还没正式调效果,就是简单的了解熟悉一下,搭一个简单的模型,所以所以也还没仔细分析原因,但是读过的论文里有提到过这个注意事项。
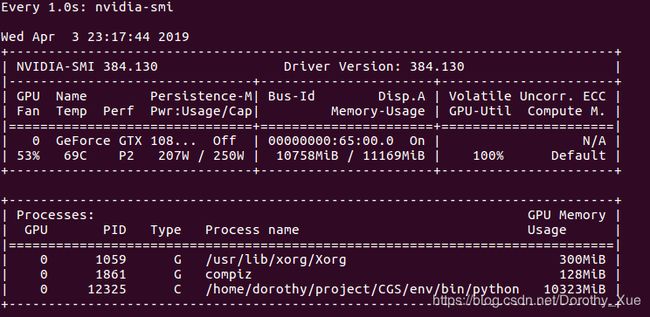
5. 有时候代码运行着运行着就卡机了,咋肥四咧?内存崩了吧!不过用GPU的话,我觉得奥,最好监控GPU的使用情况,终端就能实现:
$watch -n 1 nvidia-smi我设置的是每隔1秒显示一次显存情况,嫌弃太短了把命令中的1改成你想要的就好了。(截图时在跑,100%了
6. 有时候数据集会很大,一次全部加载到内存中会导致崩溃,所以可能需要分开训练。这时候就需要再训练当前子数据集的时候,调用上一批子数据集的权重参数等。咋弄咧?怎样实现断点续训功能咧?
用ModelCheckpoint
首先了解一下ModelCheckpoint:
keras.callbacks.ModelCheckpoint( filepath,
monitor='val_loss',
verbose=0,
save_best_only=False,
save_weights_only=False,
mode='auto',
period=1
)其中,各项参数如下:
- filepath:字符串,保存模型路径
- monitor:要监控的值,val_acc或者val_loss
- verbose:信息展示模式,0是屏蔽,1是打印
- save_best_only:设为True,则保存验证集上性能最好的模型
- save_weights_only:设为True,则只保存模型权重;否则保存整个模型(包括模型结构、配置信息等)
- mode:可以设三种参数“auto”、“min”、“max”,在save_best_only=True时决定性能最佳模型的评判准则,例如,当监测值为val_acc时,模式应为max,当检测值为val_loss时,模式应为min。在auto模式下,评价准则由被监测值的名字自动推断。
- period:Checkpoint之间间隔的epoch数
接下来是代码实现过程:
checkpoint = ModelCheckpoint('{}'.format(model_save_path) + '/{val_loss:.4f}.h5', verbose=1)
history = m.fit(train_img, train_gt, validation_data=(validation_img, validation_gt),
epochs=10, batch_size=1, verbose=1, callbacks=[checkpoint])8. keras模型中处理彩色图片的顺序为:BGR
这里补充一下各种图像库的花边知识:
- 除了opencv读入的彩色图片是以RGB的顺序存储外,其他所有图像库读入彩色图片都以RGB存储
- 除了PIL读入的图片是img类之外,其他库读进来的图片都是numpy矩阵
- 各大图像库的性能,老大哥当属opencv,无论是速度还是图片操作的全面性,都属于碾压的存在,毕竟它是一个巨大的CV专用库
9. 测试阶段的model.predict(),一次只预测一张图,1*224*224*3(自己定的224*224),不能把测试集一下子都扔到predict()一起预测,写个循环,排好队一个一个来。记得加载图片处理数据时减均值。
10. 加载GT时,注意在读取完GT之后,要加一句
f = cv2.cvtColor(f, cv2.COLOR_RGB2GRAY) # 将彩色图变成灰度图完了之后要记得归一化:
f = (f - np.min(f)) / (np.max(f) - np.min(f))