QTreeView使用总结13,自定义model示例,大大优化性能和内存
1,简介
前面简单介绍过Qt的模型/视图框架,提到了Qt预定义的几个model类型:
QStringListModel:存储简单的字符串列表
QStandardItemModel:可以用于树结构的存储,提供了层次数据
QFileSystemModel:本地系统的文件和目录信息
QSqlQueryModel、QSqlTableModel、QSqlRelationalTableModel:存取数据库数据
一般情况下满足需求了,不过有时候需要一些定制功能,或者是大量数据下对性能和开销比较注重,觉得自带的model无用功能太多效率比较低,这时候自定义model就比较适合了。
我使用自定义model 同时出于这两方面需要,既为了性能也为了特殊功能。
2,参考资料
豆子《Qt学习之路2》中的几篇关于自定义model的文章:
自定义model之一: 自定义只读模型
自定义model之二: 自定义可编辑模型
自定义model之三: 布尔表达式树模型
3,效果
本篇文章写的费了点功夫,为了演示本章内容,花了几个小时的时间整理代码和示例。
因为技术都应用在我的项目里,实际所用的model实现了很多特殊功能,非常复杂,我要提炼出一个简单可读的demo。
如图,分别演示了以常规的 QStandardItemModel 和使用自定义的model的效果。
示例中只使用了10W行的数据量级
运行程序你就会发现,常规model在初始化tree的过程就比自定义model慢很多,更可怕的是,它所占用的内存开销是自定义model的数倍甚至数十倍!数据量越大内存差距越明显。
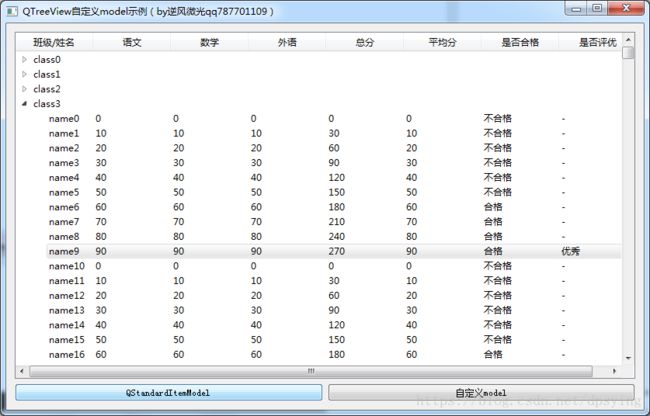
这里以10个一级节点班级,每个班级1W个学生,共10W条记录的数据量测试:
QStandardItemModel 方法程序占用总内存大概160多M,而自定义model 占用的30多M。
而Qt一个简单窗口程序本身有20多M内存。
可见自定义model显示这10W条记录基本没使用多少内存,如果考虑百万、千万级别的数据,不使用自定义model或比较有效的优化方法,内存将很快耗尽。
4,构造演示数据
我演示的例子为一级节点班级、二级节点学生信息。
其中学生信息原始数据只有姓名、三门课成绩,需显示的列多一些,包含:
班级/姓名、语文、数学、外语、总分、平均分、是否合格、是否评优
其中后面几列是根据学生成绩计算得出的:
所有课成绩都>60则合格,所有课成绩都>90则优秀。
定义数据类型:班级、学生
//学生信息
typedef struct _STUDENT{
QString name; //姓名
int score1; //语文成绩
int score2; //数学成绩
int score3; //外语成绩
_STUDENT()
{
name = "";
score1 = score2 = score3 = 0;
}
}STUDENT,*PSTUDENT;
//班级信息
typedef struct _CLASS{
QString name; //班级
QVector students;
_CLASS()
{
name = "";
}
}CLASS; MainWindow::MainWindow(QWidget *parent) :
QMainWindow(parent),
ui(new Ui::MainWindow)
{
ui->setupUi(this);
//初始化模拟数据:学生成绩
//10个班级、每个班级10000个学生,共10W行记录
int nClass = 10;
int nStudent = 10000;
for(int i=0;i<nClass;i++)
{
CLASS* c = new CLASS;
c->name = QString("class%1").arg(i);
for(int j=0;j<nStudent;j++)
{
STUDENT* s = new STUDENT;
s->name = QString("name%1").arg(j);
s->score1 = s->score2 = s->score3 = (j%10)*10;
c->students.append(s);
}
mClasses.append(c);
}
}其中mClasses为存放模拟数据的变量:
QVector<CLASS*> mClasses; //模拟数据5,QStandardItemModel 常规model
void MainWindow::on_btn1_clicked()
{
//1,QTreeView常用设置项
QTreeView* t = ui->treeView;
// t->setEditTriggers(QTreeView::NoEditTriggers); //单元格不能编辑
t->setSelectionBehavior(QTreeView::SelectRows); //一次选中整行
t->setSelectionMode(QTreeView::SingleSelection); //单选,配合上面的整行就是一次选单行
// t->setAlternatingRowColors(true); //每间隔一行颜色不一样,当有qss时该属性无效
t->setFocusPolicy(Qt::NoFocus); //去掉鼠标移到单元格上时的虚线框
//2,列头相关设置
t->header()->setHighlightSections(true); //列头点击时字体变粗,去掉该效果
t->header()->setDefaultAlignment(Qt::AlignCenter); //列头文字默认居中对齐
t->header()->setDefaultSectionSize(100); //默认列宽100
t->header()->setStretchLastSection(true); //最后一列自适应宽度
t->header()->setSortIndicator(0,Qt::AscendingOrder); //按第1列升序排序
//3,构造Model
QStringList headers;
headers << QStringLiteral("班级/姓名")
<< QStringLiteral("语文")
<< QStringLiteral("数学")
<< QStringLiteral("外语")
<< QStringLiteral("总分")
<< QStringLiteral("平均分")
<< QStringLiteral("是否合格")
<< QStringLiteral("是否评优");
QStandardItemModel* model = new QStandardItemModel(ui->treeView);
model->setHorizontalHeaderLabels(headers);
foreach (CLASS* c, mClasses)
{
//一级节点:班级
QStandardItem* itemClass = new QStandardItem(c->name);
model->appendRow(itemClass);
foreach (STUDENT* s, c->students)
{
//二级节点:学生信息
int score1 = s->score1;
int score2 = s->score2;
int score3 = s->score3;
int nTotal = score1 + score2 + score3;
int nAverage = nTotal/3;
bool bPass = true;
if(score1 < 60 || score2 < 60 || score3 < 60)
{
//任意一门课不合格则不合格
bPass = false;
}
bool bGood = false;
if(score1 >= 90 && score2 >= 90 && score3 >= 90)
{
//每门课都达到90分以上评优
bGood = true;
}
QList<QStandardItem*> items;
QStandardItem* item0 = new QStandardItem(s->name);
QStandardItem* item1 = new QStandardItem(QString::number(score1));
QStandardItem* item2 = new QStandardItem(QString::number(score2));
QStandardItem* item3 = new QStandardItem(QString::number(score3));
QStandardItem* item4 = new QStandardItem(QString::number(nTotal));
QStandardItem* item5 = new QStandardItem(QString::number(nAverage));
QStandardItem* item6 = new QStandardItem(bPass ? "合格" : "不合格");
QStandardItem* item7 = new QStandardItem(bGood ? "优秀" : "-");
items << item0 << item1 << item2 << item3 << item4 << item5 << item6 << item7;
itemClass->appendRow(items);
}
}
//4,应用model
t->setModel(model);
}6,自定义model
Qt提供一个基础的model类QAbstractItemModel,前面几种常用model也基本从此类而来。
我们写一个自定义的TreeModel,继承自该类,实现里面的一些重载函数:
#include "TreeItem.h"
#include 这些函数基本作用在注释内注明了,主要需要根据自己的情况写好data函数,其它的内容可以参考我的示例代码,略微调整。
其中TreeItem 为我们自定义的指代一个节点的类:
#include mChildItems; //子节点
TreeItem *mParentItem; //父节点
int mLevel; //该节点是第几级节点
void* mPtr; //存储数据的指针
int mRow; //记录该item是第几个,可优化查询效率
}; 其中只需存一个真实数据的指针void* mPtr 即可,这样便大大减少了因为常规Model内重复存储数据所带来的内存开销,这也是该方法能节约内存的主要原因。
另外介绍几个核心函数实现:
TreeModel::data():视图获取数据时调用的函数,里面通过具体的TreeItem::data()获取最终数据
QVariant TreeModel::data(const QModelIndex &index, int role) const
{
if (!index.isValid())
return QVariant();
TreeItem *item = static_cast(index.internalPointer());
if (role == Qt::DisplayRole)
{
return item->data(index.column());
}
return QVariant();
} QVariant TreeItem::data(int column) const
{
if(mLevel == 1)
{
//一级节点,班级
if(column == 0)
{
CLASS* c = (CLASS*)mPtr;
return c->name;
}
}
else if(mLevel==2)
{
//二级节点学生信息
STUDENT* s = (STUDENT*)mPtr;
switch (column)
{
case 0: return s->name;
case 1: return QString::number(s->score1);
case 2: return QString::number(s->score2);
case 3: return QString::number(s->score3);
case 4: return QString::number(s->score1 + s->score2 + s->score3);
case 5: return QString::number( (s->score1 + s->score2 + s->score3)/3 );
case 6:
{
if(s->score1 < 60 || s->score2 < 60 || s->score3 < 60)
{
//任意一门课不合格则不合格
return QStringLiteral("不合格");
}
else
{
return QStringLiteral("合格");
}
}
case 7:
{
if(s->score1 >= 90 && s->score2 >= 90 && s->score3 >= 90)
{
//每门课都达到90分以上评优
return QStringLiteral("优秀");
}
else
{
return QStringLiteral("-");
}
}
default:
return QVariant();
}
}
return QVariant();
}
看到这里,可以发现,自定义model实际需要存储的数据,比界面所显示的列数要少的多!
只要能通过现有数据推算出来的列的数据,都可以不存储!
比如我们只存储了基本的3门课程分数,其他内容全为显示时视图向我们的自定义model获取数据时实时计算得出的!
可能你会担心,这样计算量会不会变大,导致反应速度变慢?
其实视图只会对当前需要显示的数据来请求,意思就是,无论总数据多少,只对当前可见的内容进行计算,你想想电脑屏幕就那么大,这个计算量简直毫无压力。
因此,由于实际需要存储列数变少,内存占用又得到可观的缩减。
不过这种好处只适用于多列的数据有关联可推算的情况。
我的项目内存在大量此类数据,获得收益较大。
进一步了解可以阅读源码。
7,源码
TreeDemo13 自定义model示例
源码我使用Qt5.8.0 mingw版本在win7编译通过,如有编译问题尝试使用相同环境试试。