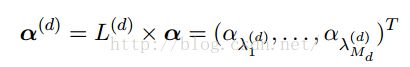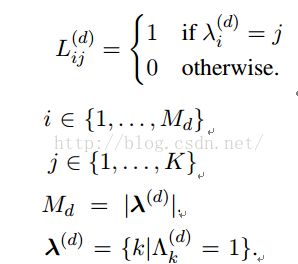主题模型
(一)简介
1.主题模型是对文本中隐含主题的一种建模方法;每个主题其实是词表上单词的概率分布;
2.主题模型是一种生成模型,一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到的;
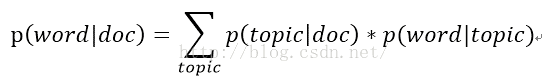
3.常见的主题模型有3种:
(1)PLSA(Probabilistic Latent Semantic Analysis)
(2)LDA(Latent Dirichlet Allocation)
(3)L-LDA(Label Latent Dirichlet Allocation)
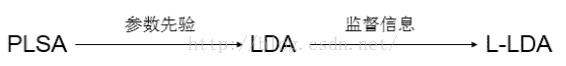
(二)PLSA模型
1.生成过程:
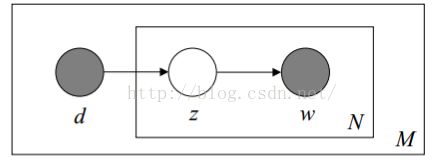
(1)M个doc,N个word;
(2)doc选择topic服从多项式分布,topic选择word也服从多项式分布;
(3)生成模型如下:
其中p(topic|doc)与p(word|topic)属于模型参数;
2.训练过程:由于存在隐藏变量topic,因此选择EM算法;
(三)LDA模型
1.原理:LDA模型是在PLSA模型的基础上引入了参数的先验知识,也就是假设doc到topic的多项分布参数以及topic到word的多项分布参数服从狄利克雷分布;
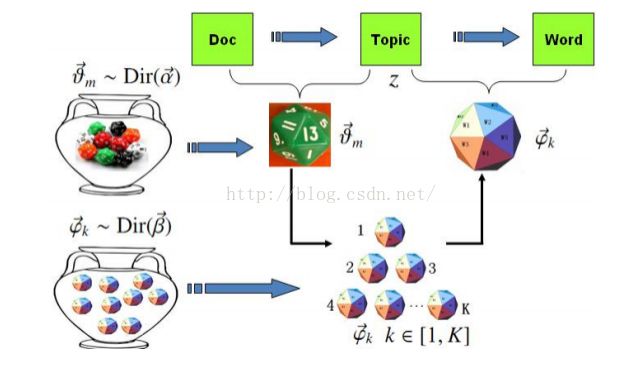
(1)m个doc,k个topic;
(2)α和β属于超参数;
(3)数学解释:
1)贝叶斯公式(后验正比于似然乘以先验)
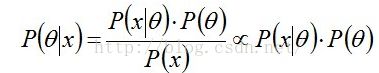
2)在贝叶斯概率理论中,如果后验概率P(θ|x)和先验概率p(θ)满足同样的分布律,那么,先验分布和后验分布被叫做共轭分布,同时,先验分布叫做似然函数的共轭先验分布;
3)Dirichlet分布是多项分布的共轭先验分布:
二项分布:
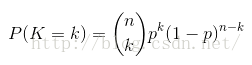
多项分布:
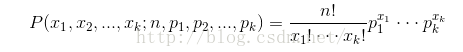
Beta分布:
![]()

Dirichlet分布:

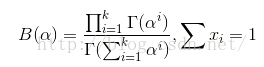
4)选择共轭先验分布可以带来计算上的方便;
2.生成过程:
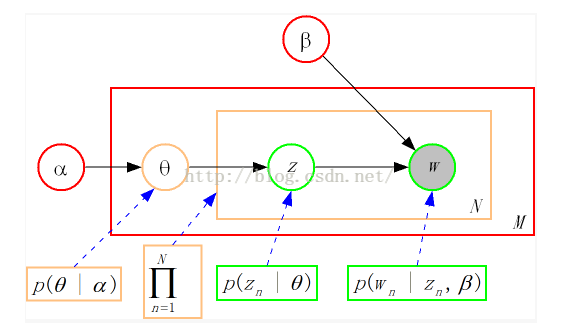
(1)M个doc,N个word;
(2)生成模型如下:

3.训练过程:GibbsSampling
(1)图示:
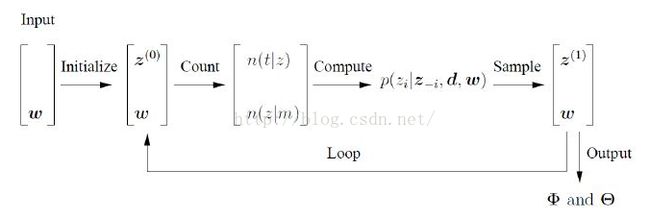
初始时,随机给文本中的每个单词w分配主题z;然后统计每个主题z下出现term t的数量分布以及每个文档m下主题z 的数量分布;然后排除当前词的主题分配,根据其他所有词的主题分配估计当前词的主题;用同样的方法不断更新下一个词的主题,直至每个文档下主题的分布以及每个主题下词的分布收敛,算法停止;这里的核心是如何根据其他所有词的主题分配估计当前词的主题,也就是gibbs 采样公式;
(2)gibbs采样公式:
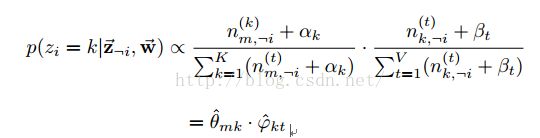
其中zi=k表示第i个词的主题为k,i的形式为(m,n),表示第m篇第n个;¬i 表示去除下标为i的词;
(3)理解
1)概率计算:
对每个D中的文档d,对应到不同Topic的概率θd
对每个T中的topict,生成不同单词的概率φt
2)训练过程:
步骤1:先随机地给θd和φt赋值(对所有的d和t)
步骤2:pj(wi|ds)=p(wi|tj)*p(tj|ds)
枚举T中的topic,得到所有的pj(wi|ds),其中j取值1~k;然后可以根据这些概率值结果为ds中的第i个单词wi选择一个topic;最简单的想法是取令pj(wi|ds)最大的tj(注意,这个式子里只有j是变量),即argmax[j]pj(wi|ds);
步骤3:然后,如果ds中的第i个单词wi在这里选择了一个与原先不同的topic,就会对θd和φt有影响了(根据前面提到过的这两个向量的计算公式可以很容易知道)。它们的影响又会反过来影响对上面提到的p(w|d)的计算;对D中所有的d中的所有w进行一次p(w|d)的计算并重新选择topic看作一次迭代;这样进行n次循环迭代之后,就会收敛到LDA所需要的结果了;
4.推理过程:训练与推理的步骤几乎一样,都需要gibbs采样,但是由于推理时,已知topic下word的分布,因此每次迭代只更新文档下topic的分布,迭代速度是比训练快很多的;
5.效果评估(越小越好)
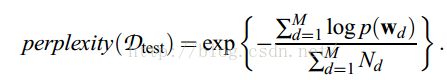
(四)Label LDA
1. Label LDA的label指的是事先给定每个文档的主题类别;
2. Label LDA从topic到word的生成过程与LDA一样,不同的是从doc到topic的生成过程;LDA中从doc到topic的生成服从多项分布θd,而θd又服从Dirichlet分布,每个doc的θd都是包括全部topic,而在label LDA中,每个doc的θd只包括其label中对应的topic,与此同时,θd也服从Dirichlet分布;
3. 生成过程如下:

(1) 第1,2步是从topic到word的生成,与LDA一样;
(2) 第4,5步是生成每个doc的label(监督训练中其实就是样本自带的label);
(3) 第6步是对Dirichlet分布的参数α进行降维,从而约束在每个doc的label下;