Apache Spark:大数据处理统一引擎
工业和研究中数据的大幅增长为计算机科学带来了巨大的机会与挑战。由于数据大小超过了单台机器的能力,用户需要新的系统将计算扩展到多个节点。因此,针对不同计算工作负载的新集群编程模型已呈爆炸式增长。
这些模型相对专业化。例如支持批处理的MapReduce,支持迭代图算法的Dreme。在开源Apache Hadoop堆栈中,类似Storm和Impala的系统也是特有的。即使在关系数据库世界中,“一刀切”系统已越来越少。然而,很多大数据应用需要整合许多不同的处理类型。大数据,顾名思义,代表了数据的多样性和复杂性。一个典型的管道需要类似MapReduce的系统进行数据载入,使用类似SQL的语言进行查询。用户不得不将不同的系统整合在一起,并且有时候引擎也不能对应用的需求都满足。
有鉴于此,2009年加州大学伯克利分校团队开始了Apache Spark项目,旨在为分布式数据处理设计一个统一的引擎。 Spark具有类似于MapReduce的编程模型,但是使用称为“弹性分布式数据集”或RDDs的数据共享抽象扩展。通过这个简单的扩展,Spark可以轻松应对之前需要单独引擎处理的高强度工作,包括SQL、流式传输、机器学习和图形处理。Spark使用与专用引擎相同的优化(例如面向列的处理和增量更新),并实现相同的性能,但是编写更为高效。
Spark的通用性有几个重要的好处。
首先,应用程序更容易开发,因为它们使用统一的API。
第二,结合处理任务更有效;而先前的系统需要将数据写入存储以将其传递给另一个引擎,Spark可以在相同的数据(通常在存储器中)上运行不同的功能。
最后,Spark启用了以前系统无法实现的新应用程序(如图形上的交互式查询和流式计算机学习)。自2010年发布以来,Spark已经发展成为最活跃的开源项目或大数据处理,拥有超过1,000名贡献者。该项目已在超过1,000个组织中使用,从技术公司到银行、零售、生物技术和天文学。
随着并行数据处理变得普遍,处理功能的可组合性将是对可用性和性能的最重要关注之一。许多数据分析是探索性的,用户希望将库函数快速组合成一个工作管道。然而,对于“大数据”,特别是在不同系统之间复制数据是对性能不利的。因此,用户需要共性和可组合的抽象。在本文中,我们将介绍Spark编程模型并解释为什么它是高度通用的。我们还讨论了如何利用这种通用性来构建其它处理任务。最后,我们总结了Spark中常见的应用程序。
编程模型
Spark中的关键编程抽象是RDD,它是容错集合,可以并行处理集群中的对象。用户通过“转换”(例如map、filter和groupBy)操作来创建RDD。
Spark通过Scala、Java、Python和R中的函数式编程API来表达RDD,用户可以简单地在集群上运行本地函数。 例如,以下Scala代码通过搜索以ERROR开头的行来创建日志文件中错误消息的RDD,然后打印总错误数:
lines = spark.textFile("hdfs://...")
errors = lines.filter(s => s.startsWith("ERROR"))
println("Total errors: "+errors.count())第一行定义了一个在HDFS上的文本行集合RDD。第二行调用过滤器转换以从行中导出新的RDD。它的参数是一个Scala函数文字或闭包。最后一行调用count函数。另一种类型的RDD操作称为“动作”,返回一个结果给程序(这里,RDD中的元素数量),而不是定义一个新的RDD。
Spark评估RDDs延迟,尝试为用户运算找到一个有效的计划。特别的是,变换返回表示计算结果的新RDD对象,但不立即计算它。当一个动作被调用时,Spark查看整个用于创建执行计划的转换的图。例如,如果一行中有多个过滤器或映射操作,Spark可以将它们融合到一个传递中,或者如果知道数据是被分区的,它可以避免通过网络为groupBy进行数据传递。因此用户可以实现程序模块化,而不会造成性能低下。
最后,RDDs为计算之间的数据共享提供了明确的支持。默认情况下,RDD是“短暂的”,因为它们每次在动作(例如count)使用时被重新计算。但是,用户还可以将所选的RDD保留在内存中或快速重用。(如果数据不适合内存,Spark还会将其溢出到磁盘。)例如,用户在HDFS中搜索大量日志数据集来进行错误调试时,可以通过调用以下函数来载入不同集群的错误信息到内存中:
errors.persist()
随后,用户可以在该内存中数据上运行不同的查询:
// Count errors mentioning MySQL
errors.filter(s => s.contains("MySQL")).count()
// Fetch back the time fields of errors that
// mention PHP, assuming time is field #3:
errors.filter(s => s.contains("PHP")).map(line => line.split('\t')(3)).collect()这种数据共享是Spark和以前的计算模型(如MapReduce)之间的主要区别。
容错
除了提供数据共享和各种并行操作,RDDs还可以自动从故障中恢复。 传统上,分布式计算系统通过数据复制或检查点提供了容错。 Spark使用一种称为“lineage”的新方法。每个RDD跟踪用于构建它的转换图,并对基本数据重新运行这些操作,以重建任何丢失的分区。 例如,图2显示了我们以前的查询中的RDD,其中我们通过应用两个过滤器和一个映射来获取错误的时间字段。 如果RDD的任何分区丢失(例如保存内存分区的错误的节点失败),Spark将通过在HDFS文件的相应块上的应用过滤器来重建它。 对于将数据从所有节点发送到所有其他节点(例如reduceByKey)的“shuffle”操作,发送方在本地保留其输出数据,以防接收器出现错误。
基于沿袭的恢复比数据密集型工作负载中的复制效率高得多。 它节省了时间,因为写入RAM要比通过网络写入数据快。 恢复通常比简单地重新运行程序快得多,因为故障节点通常包含多个RDD分区,这些分区可以在其他节点上并行重建。
另外一个复杂些的例子如图3:
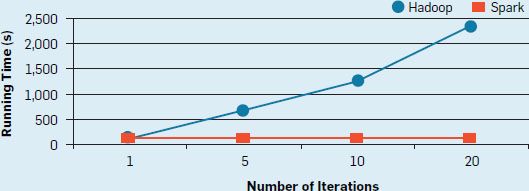
Spark中逻辑回归的实现。 它使用批量梯度下降,一个简单的迭代算法,重复计算数据上的梯度函数作为并行求和。 Spark可以方便地将数据加载到RAM中,并运行多个求和。 因此,它运行速度比传统的MapReduce快。 例如,在100GB作业中(如图4),MapReduce每次迭代需要110秒,因为每次迭代需从磁盘加载数据,而Spark在第一次加载后每次迭代只需要一秒。
与存储系统的整合
与Google的MapReduce非常相似,Spark旨在与多个外部系统一起使用持久存储。Spark最常用于集群文件系统,如HDFS和键值存储,如S3和Cassandra。 它还可以作为数据目录与Apache Hive连接。 RDD通常仅在应用程序中存储临时数据,但某些应用程序(例如Spark SQL JDBC服务器)也在多个用户之间共享RDD。Spark作为存储系统无关引擎的设计,使用户可以轻松地对现有数据进行运算和连接各种数据源。
高级库
RDD编程模型仅提供对象的分布式集合和在其上运行的函数。除此之外,我们在Spark上构建了各种针对专用计算引擎更高级的库。其关键思想是,如果我们控制存储在RDD中的数据结构,跨节点的数据分区以及在其上运行的函数,我们可以在其他引擎中实现许多执行技术。事实上,正如我们在本节中所展示的,这些库通常在每个任务上实现最先进的性能,同时在用户组合使用它们时提供显着的优势。我们现在讨论Apache Spark包含的四个主要库。
SQL和DataFrames。最常见的数据处理范例之一是关系查询。 Spark SQL及其前身Shark使用类似于分析数据库的技术在Spark上实现这样的查询。例如,这些系统支持列式存储,基于成本的优化和用于查询执行的代码生成。这些系统的主要思想是使用与分析数据库相同的数据布局 - 压缩的柱状存储 - 内部RDD。在Spark SQL中,RDD中的每个记录都保存为以二进制格式存储的一系列行,并且系统生成直接针对此布局运行的代码。
除了运行SQL查询之外,我们还使用Spark SQL引擎为称为DataFrames的基本数据变换提供了更高级的抽象,这些变换是具有已知模式的记录的RDD。 DataFrames是R和Python中的表格数据的常见抽象,具有用于过滤,计算新列和聚合的编程方法。在Spark中,这些操作映射到Spark SQL引擎并接收其所有优化。我们稍后讨论DataFrames。
Spark SQL中尚未实现的一种技术是索引,尽管Spark上的其他库(如IndexedRDDs)确实使用它。
Spark Streaming(流)。 Spark Streaming使用称为“离散流”的模型实现增量流处理。为了通过Spark实现流式传输,我们将输入数据分成小批量(例如每200毫秒),我们定期与RDD中存储的状态组合以产生新结果。以这种方式运行流计算比传统的分布式流系统有几个好处。例如,由于使用沿袭,故障恢复更便宜,并且可以将流与批处理和交互式查询组合。
GraphX。 GraphX提供了类似于Pregel和GraphLab的图形计算接口,1通过为其构建的RDD选择分区函数来实现与这些系统相同的布局优化(例如顶点分区方案)。
MLlib。 MLlib,Spark的机器学习库,实现了50多种常见的分布式模型训练算法。例如,它包括决策树(PLANET),Latent Dirichlet分布和交替最小二乘矩阵分解的常见分布式算法。
组合处理任务。 Spark的库都对RDD进行操作,作为数据抽象,使得它们在应用程序中易于组合。例如,图5显示了一个程序,它使用Spark SQL读取一些历史Twitter数据,使用MLlib训练一个K-means聚类模型,然后将该模型应用于一个新的tweet流。每个库返回的数据任务(这里是历史性的tweet RDD和K-means模型)很容易传递给其他库。除了API级别的兼容性,Spark中的组合在执行级别也是高效的,因为Spark可以跨处理库进行优化。例如,如果一个库运行映射函数,并且下一个库对其结果运行映射,则Spark将这些操作融合到单个映射中。同样,Spark的故障恢复在这些库中无缝地工作,重新计算丢失的数据,无论哪个库产生它。
性能
假设这些库运行在同一引擎上,它们是否会失去性能?我们发现,通过实现我们刚刚在RDD中概述的优化,我们通常可以匹配专用引擎的性能。例如,图6比较了Spark对三个简单任务(SQL查询,流字计数和交替最小二乘矩阵分解)与其他引擎的性能。虽然结果随着工作负载的不同而不同,但Spark通常与Storm,GraphLab和Impala等专用系统相当。对于流处理,虽然我们显示了Storm上分布式实现的结果,但是每个节点的吞吐量也可以与商业流引擎如Oracle CEP相媲美。
即使在高度竞争的基准测试中,我们也使用Apache Spark实现了最先进的性能。在2014年,我们进入了Daytona Gray-Sort基准(http://sortbenchmark.org/),涉及在磁盘上排序100TB的数据,并绑定一个专门的系统构建的新记录,仅用于在类似数量的机器上排序。与其他示例一样,这是可能的,因为我们可以实现RDD模型中大规模排序所需的通信和CPU优化。
应用
Apache Spark用于广泛的应用程序。我们对Spark用户的调查发现了超过1,000家使用Spark的公司,从Web服务,生物技术到金融等领域。在学术界,我们也看到了几个科学领域的应用。在这些工作负载中,我们发现用户利用Spark的通用性,并且通常组合其多个库。在这里,我们介绍几个顶级用例。许多用例的演示文稿也可在Spark Summit会议网站(http://www.spark-summit.org)上获取。
批量处理
Spark最常用的应用程序是对大型数据集进行批处理,包括Extract-Transform-Load工作负载,将数据从原始格式(如日志文件)转换为更加结构化的格式,并离线训练机器学习模型。这些工作负载的已发布示例包括Yahoo!的页面个性化和推荐;管理高盛的数据湖;阿里巴巴图表挖掘;金融价值风险计算;和丰田的客户反馈的文本挖掘。我们知道的最大的已发布的用例是在中国社交网络腾讯的8000节点集群,每天摄取1PB的数据。
虽然Spark可以在内存中处理数据,但是此类别中的许多应用程序只能在磁盘上运行。在这种情况下,Spark相对于MapReduce仍然可以提高性能,因为它支持更复杂的运算符图。
交互式查询
互动使用Spark分为三个主要类别。首先,组织通常通过商业智能工具(如Tableau)使用Spark SQL进行关系查询。例子包括eBay和百度。第二,开发人员和数据科学家可以通过shell或可视化笔记本环境以交互方式使用Spark的Scala,Python和R接口。这种交互式使用对于提出更高级的问题和设计最终导致生产应用程序的模型至关重要,并且在所有部署中都很常见。第三,一些供应商已经开发了在Spark上运行的特定领域的交互式应用程序。示例包括Tresata(反洗钱),Trifacta(数据清理)和PanTera(大规模可视化,如图7所示)。
流处理
实时处理也是一种流行的用例,无论是在分析和实时决策应用程序中。 Spark Streaming的已发布使用案例包括思科的网络安全监控,三星SDS的规范分析以及Netflix的日志挖掘。许多这些应用程序还将流式处理与批处理和交互式查询相结合。例如,视频公司Conviva使用Spark持续维护内容分发服务器性能的模型,在跨服务器移动客户端时自动查询,在需要对模型维护和查询进行大量并行工作的应用程序中。
科学应用
Spark还被用于几个科学领域,包括大规模垃圾邮件检测,图像处理,和基因组数据处理。结合批量,交互和流处理的一个例子是Howard Hughes医学院的Thunder平台神经科学,Janelia Farm。它被设计成处理来自实验的脑成像数据,实时地,从生物体(例如斑马鱼和小鼠)扩大到1TB /小时的全脑成像数据。使用Thunder,研究人员可以应用机器学习算法(例如聚类和主成分分析)来识别涉及特定行为的神经元。相同的代码可以在批处理作业中对来自先前运行的数据或在活动实验期间的交互式查询中运行。图8显示了使用Spark生成的示例图像。
使用的Spark组件
因为Spark是一个统一的数据处理引擎,自然的问题是它的图书馆组织实际使用了多少。我们对Spark用户的调查表明,组织确实使用多个组件,超过60%的组织使用至少三个Spark的API。图9概述了Databricks 2015年7月Spark调查中每个组件的使用情况,达到1400名受访者。我们将Spark Core API(只是RDD)列为一个组件,将更高级别的库列为其他组件。我们看到许多组件被广泛使用,Spark Core和SQL最受欢迎。 Streaming在46%的组织中使用,机器学习在54%中使用。虽然在图9中未直接示出,但大多数组织使用多个组件; 88%使用其中至少两个,60%使用至少三个(如Spark Core和两个库),27%使用至少四个组件。
部署环境
我们也看到Apache Spark应用程序运行的地方和它们连接到的数据源的多样性。虽然第一个Spark部署通常在Hadoop环境中,在2015年7月Spark调查中,仅有40%的部署在Hadoop YARN集群管理器上。此外,52%的受访者在公共云上运行Spark。
Spark模型的魅力
虽然Apache Spark演示了统一的集群编程模型是可行和有用的,但是了解集群编程模型的广泛性成因以及Spark的局限性是很有好处的。在这里,我们总结了一个关于Zaharia RDDs的一般性的讨论。我们从两个角度研究RDDs。首先,从能力的角度,我们认为RDDs可以模拟任何分布式计算,并且在多数情况下表现优异,除非计算对网络延迟敏感。第二,从系统的角度来看,RDD能帮助应用程序对集群中最常见瓶颈的资源进行控制 - 网络和存储I/O,从而使得这些资源得到优化。
表达性角度。为了研究RDDs的表达性,我们首先比较RDDs和MapReduce模型。第一个问题是MapReduce本身表达性的计算是什么?虽然有关于MapReduce的限制的许多讨论,这里令人惊讶的是MapReduce可以模拟任何分布式计算。
要看到这一点,请注意任何分布式计算由执行本地计算和偶尔交换消息的节点组成。 MapReduce提供了映射操作,允许本地计算和reduce,这允许全部通信。因此,可以通过将其工作分解为时间步长,运行Map以在每个时间步长中执行本地计算,以及在每个步骤结束时使用reduce来批处理和交换消息,来模拟任何分布式计算,尽管效率并不高。一系列MapReduce步骤将捕获整个结果,如图10所示。
虽然这一行的工作表明MapReduce可以模拟任意计算,但又两个问题会使这种模拟背后的“常数因子”高。首先,MapReduce在跨时间段共享数据方面效率低下,因为它依赖于复制的外部存储系统来实现此目的。由于需在每个步骤之后写出其状态,系统运行将较慢。其次,MapReduce步骤的延迟决定了我们的仿真与真实网络的匹配程度,大多数Map-Reduce实现是针对具有几分钟到几小时延迟的批处理环境设计的。
RDDs和Spark解决了这两个问题。在数据共享方面,RDD通过避免中间数据的复制来快速进行数据共享,并且可以紧密模拟在由长时间运行的进程组成的系统中发生的内存中“数据共享”。在延迟方面,Spark可以在大型集群上以100ms延迟运行MapReduce类似的步骤。虽然一些应用程序需要更细粒度的时间步长和通信,但是这100ms的延迟足以处理许多数据密集型工作负载,在通信步骤之前可以大批量进行计算。
总之,RDDs建立在Map-Reduce模拟任何分布式计算的能力之上,但更有效率。它们的主要限制是由于每个通信步骤中的同步而增加的等待时间,但是该等待时间的损失与所得相比是可以忽略的。
系统观点。独立于表征Spark的通用性的仿真方法,我们可以采用系统方法。集群计算中的瓶颈资源是什么? RDD可以有效地使用它们吗?虽然集群应用程序是多样的,但它们都受底层硬件的相同属性的约束。当前数据中心具有陡峭的存储层次结构,以相似的方式限制大多数应用。例如,典型的Hadoop集群可能具有以下特性:
本地存储。每个节点具有本地存储器,大约50GB/s的带宽,以及10到20个本地磁盘,大约1GB/s到2GB/ s的磁盘带宽。
链接。每个节点具有10Gbps(1.3GB/s)链路,或者比其存储器带宽小约40x,并且比其总的磁盘带宽小2倍。
机架。节点被组织成20到40台机器的机架,每个机架的带宽为40Gbps-80Gbps,或者机架内网络性能的2-5倍。
给定这些属性,在许多应用中最重要的性能问题是在网络中放置数据和计算。幸运的是,RDD提供了控制这种放置的设施;该接口允许应用程序在输入数据附近放置计算(通过用于输入源25的“优选位置”的API),并且RDD提供对数据分区和共置(例如指定数据被给定密钥散列)的控制。因此,库(例如GraphX)可以实现在专门系统中使用的相同的布置策略。
除了网络和I / O带宽,最常见的瓶颈往往是CPU时间,特别是如果数据在内存中。在这种情况下,Spark可以运行在每个节点上的专用系统中使用的相同的算法和库。例如,它使用Spark SQL中的列存储和处理,MLlib中的本机BLAS库等。正如我们之前讨论的,RDD明显增加成本的唯一区域是网络延迟。
从系统角度来看的最后一个观点是,由于容错,Spark可能会对当今某些专用系统产生额外的成本。例如,在Spark中,每个shuffle操作中的map任务将它们的输出保存到它们运行的机器上的本地文件,因此reduce任务可以稍后重新获取。此外,Spark在shuffle阶段实现了一个障碍,所以reduce任务不会开始,直到所有的Map已经完成。这避免了故障恢复所需的一些复杂性,如果一个“推”直接从映射记录以流水线方式减少。虽然删除一些这些功能将加快系统。但默认情况下,我们在Spark中会保持开启容错,以便于对应用程序进行容错处理。
不断探索
Apache Spark仍然是一个快速发展的项目。自2013年6月以来,代码库规模增长了6倍。拥有超过200个第三方可用软件包。在研究社区,Berkeley,MIT和Stanford的多个项目基于Spark,许多新的库(如GraphX和Spark Streaming)来自研究小组。在这里,我们简述四个主要的成果。
DataFrames和更多的声明性API。核心Spark API基于对包含任意类型的Scala,Java或Python对象的分布式集合的函数式编程。虽然这种方法非常具有表现力,但也使程序更难以自动分析和优化。存储在RDD中的Scala/ Java/Python对象可能具有复杂的结构,运行它们的函数可能包括任意代码。在许多应用程序中,如果开发人员没有使用正确的运算符,他们可能会得到不理想的性能;例如,系统本身不能在Map之前推送过滤器功能。
为了解决这个问题,我们在2015年扩展了Spark,以便根据关系代数添加一个名为DataFrames的更具声明性的API。数据帧是Python和R中表格数据的通用API。数据帧是一组具有已知模式的记录,基本上等同于数据库表,支持使用受限“表达式”API进行过滤和聚合等操作。然而,与在SQL语言中工作不同,数据帧操作被调用作为更通用的编程语言(例如Python和R)中的函数调用,允许开发人员使用主语言中的抽象(例如函数和类)。图11和图12显示了API的示例。
Spark的DataFrames提供了类似于单节点程序包的API,但是使用Spark SQL的查询计划程序自动并行化和优化计算。用户代码因此接收在Spark的功能API下不可用的优化(例如谓词下推,运算符重新排序和连接算法选择)。据我们所知,Spark DataFrames是第一个在数据框架API.d下执行这种关系优化的库。
虽然DataFrames仍然是新的,但是这不妨碍它的流行。在我们2015年7月的调查中,60%的受访者报告使用它们。由于DataFrames的成功,我们还开发了一个名为Datasetse的类型安全接口,让Java和Scala程序员将DataFrames视为Java对象的静态类型集合,类似于RDD API,并仍然接收关系优化。我们期望这些API逐渐成为在Spark库之间传递数据的标准抽象。
性能优化。Spark最近的许多工作都是在性能上。在2014年,Databricks团队花费了大量的精力来优化Spark的网络和I/O元操作,在 Daytona GraySort挑战中成功打破赛事记录。挑战是项目是对100TB数据进行排序,Spark的成绩较前冠军快了3倍,但是仅需1/10的设备。这个基准测试不是在内存中执行,而是在(固态)磁盘上执行的。
R语言支持。 SparkR project在2015年被合并到Spark中,在R中提供了一个编程接口。R接口基于DataFrames,使用与R的内置数据框架几乎完全相同的语法。其他Spark库(如MLlib)也很容易从R中调用,因为它们接受DataFrames的输入。
库的研究。 Apache Spark继续努力于构建更高级别的数据处理库。最近的项目包括Thunder神经科学,ADAM基因组学以及Kira天文学图像处理。其他研究库(如GraphX)已被合并到主要代码库。
小结
可扩展数据处理对于下一代计算机应用是必不可少的,但通常涉及不同的计算系统。为了简化这个任务,Spark项目为大数据应用程序引入了统一的编程模型和引擎。实践证明,这样的模型可以有效地支持当前的工作负荷,并为用户带来实质性的好处。希望Apache Spark能增强在大数据编程库中的可组合性,并开发更易于用户使用的库。
本文中描述的所有Apache Spark库都是开源的,可通过http://spark.apache.org/ 查看。 Databricks还制作了所有Spark峰会的视频,可在https://spark-summit.org/ 中免费获得。
原文:Apache Spark: A Unified Engine for Big Data Processing
作者:Matei Zaharia, Reynold S. Xin, Patrick Wendell, Tathagata Das, Michael Armbrust, Ankur Dave, Xiangrui Meng, Josh Rosen, Shivaram Venkataraman, Michael J. Franklin, Ali Ghodsi, Joseph Gonzalez, Scott Shenker, Ion Stoica
Communications of the ACM
翻译:Daisy 责编:仲培艺