常系数齐次线性递推算法学习
文章目录
- 简介
- 求法
- 矩阵快速幂
- 特征多项式
- 一些定义
- Cayley-Hamilton定理
- 递推优化
简介
定义:设有数列 { a n } 满 足 递 推 关 系 a n = ∑ i = 1 k a n − i f i \{a_n\}满足递推关系a_n=\sum\limits_{i=1}^{k}a_{n-i}f_i {an}满足递推关系an=i=1∑kan−ifi,则称该数列满足 k k k阶齐次线性递推关系。
求法
现在我们从最基础的矩阵快速幂开始一步一步优化求 a n a_n an的时间复杂度。
矩阵快速幂
直接上矩阵快速幂来优化递推即可,时间复杂度为 O ( k 3 l o g n ) O(k^3log_n) O(k3logn),非常不优秀,因此我们考虑用更快的方法求出 a n a_n an。
在我们知道了 a 1 , a 2 , . . . a k a_1,a_2,...a_k a1,a2,...ak之后想推出 a n a_n an的方法可以借鉴矩阵快速幂的方法,构造一个 k ∗ k k*k k∗k的矩阵 M M M来完成递推,关键就是优化求 M n M^n Mn的时间复杂度了,这里我们引入一个叫做特征多项式的东西。
特征多项式
一些定义
特征值,特征向量: 对 于 一 个 矩 阵 A , 若 ∃ 常 数 λ 和 向 量 v ⃗ 满 足 λ v ⃗ = A v ⃗ 对于一个矩阵A,若\exist常数\lambda和向量\vec v满足\lambda\vec v=A\vec v 对于一个矩阵A,若∃常数λ和向量v满足λv=Av则称向量 v ⃗ \vec v v为矩阵 A A A的一组特征向量, λ \lambda λ为矩阵 A A A的一组特征值。
特征多项式,特征方程,特征值:我们对上面的关系式进行变换: ( λ E − A ) v ⃗ = 0 (\lambda E-A)\vec v=0 (λE−A)v=0,学过线性代数的都知道这个方程有解的充要条件是 d e t ( λ E − A ) = 0 det(\lambda E-A)=0 det(λE−A)=0,于是我们将 d e t ( λ E − A ) det(\lambda E-A) det(λE−A)看成一个 k k k次多项式 f ( x ) f(x) f(x),我们将 f ( x ) = 0 f(x)=0 f(x)=0这个方程称作特征方程,将 f ( x ) f(x) f(x)称作特征多项式,而特征方程的 k k k个根就是 k k k个特征值。
由于一共有 k k k个解,因此我们可以换一种形式来表示 f ( x ) f(x) f(x): f ( x ) = ∏ i = 1 k ( x − λ i ) , λ i 指 第 i 个 特 征 值 即 第 i 个 解 f(x)=\prod_{i=1}^k(x-\lambda_i),\lambda_i指第i个特征值即第i个解 f(x)=∏i=1k(x−λi),λi指第i个特征值即第i个解
Cayley-Hamilton定理
这是特征根多项式的一个重要性质,叙述如下:
设 A A A是数域 P P P上的 N N N阶矩阵,其特征多项式 f ( λ ) = ∣ λ E − A ∣ = λ N + b 1 λ N − 1 + b 2 λ N − 2 + . . . + b N − 1 λ + b N f(λ)=|λE−A|=λ^N+b_1λ^{N−1}+b_2λ^{N−2}+...+b_{N−1}λ+b_N f(λ)=∣λE−A∣=λN+b1λN−1+b2λN−2+...+bN−1λ+bN。
则 f ( A ) = A N + b 1 A N − 1 + b 2 A N − 2 + . . . + b N − 1 A + b N = O f(A)=A^N+b_1A^{N−1}+b_2A^{N−2}+...+b_{N−1}A+b_N=O f(A)=AN+b1AN−1+b2AN−2+...+bN−1A+bN=O,即 f ( λ ) f(λ) f(λ)为化零多项式。
递推优化
考虑 M M M的特征多项式 f ( x ) f(x) f(x),这是一个 k k k次多项式。
不妨对 M n M^n Mn和 f ( M ) f(M) f(M)做一个多项式除法,令 M n = f ( M ) g ( M ) + r ( M ) M^n=f(M)g(M)+r(M) Mn=f(M)g(M)+r(M),考虑到 f ( x ) f(x) f(x)是 M M M的特征多项式,因此 f ( M ) = O ⇒ r ( M ) = M n f(M)=O\Rightarrow r(M)=M^n f(M)=O⇒r(M)=Mn,于是问题转化成了求 M n % f ( M ) M^n\%f(M) Mn%f(M),并且我们已知这个多项式次数最多是 k − 1 k-1 k−1
然后就只用求出 f ( M ) f(M) f(M)即可。
推导过程摘自 D Z Y O DZYO DZYO的博客:
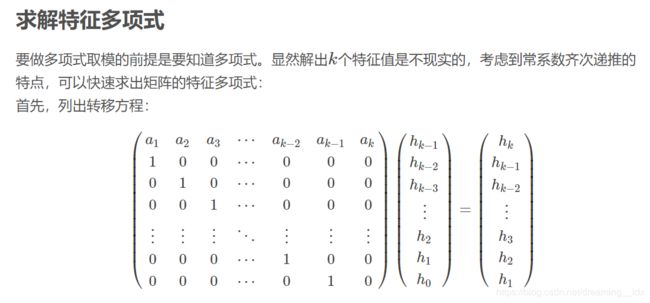

求出来之后对多项式取模即可。
直接 O ( k 2 ) O(k^2) O(k2)取模总时间复杂度是 O ( k 2 l o g n ) O(k^2log_n) O(k2logn)的。
当然可以更加毒瘤,我们用FFT来优化把总时间复杂度降到 O ( k l o g k l o g n ) O(klog_klog_n) O(klogklogn)