【Keras之父】总结篇
深度学习(deep learning)是机器学习的众多分支之一。它的模型是一长串的几何函数,各个都作用在数据上。这些运算组组成了模块叫做层。DL模型通常都是层的堆叠,也可以说是层组成的图。这些层由权重(weight)来参数化,权重是训练过程中需要学习的参数。模型的知识(knowledge)保存在它的权重中,学习的过程就是为这些权重找到正确的值。
在深度学习中,一切都是向量,即一切都是几何空间(geometric space)中的点(point)。首先将模型输入(文本、图像等)和目标向量化(vectorize),即将其转换为初始输入向量空间和目标函向量空间。DL模型的每一层都对通过它的数据做一个简单的几何变换。模型中的层链共同形成了一个非常复杂的几何变换,它可以分解为一系列简单的几何变换。这个复杂变换试图将输入空间映射到目标空间。,每次映射到一个点。这个变换由层的权重来参数化,权重根据模型当前表现进行迭代更新。这种几何变换有一个关键性质,就是它必须是可微的/differentiable,这样才可以通过梯度下降来学习其参数。约束条件是:从输入到输出的几何变形必须是平滑且连续的。 导数和微分的基础----数学很有魅力!
【引用原文】
Deep-learning models are mathematicalmachines for uncrumpling complicated manifolds of high-dimensional data.
深度学习模型是解开高维数据复杂流形的数学机器。
That’s the magic of deep learning:turning meaning into vectors, into geometric spaces, and then incrementallylearning complex geometric transformations that map one space to another. Allyou need are spaces of sufficiently high dimensionality in order to capture thefull scope of the relationships found in the original data.
深度学习的魅力:将意义转换为向量、几何空间,然后逐步学习将一个空间映射到另一空间的复杂几何变换。你需要的只是维度足够大的空间,以便捕捉到原始数据中能够找到的所有关系。
===============================================================================================
【机器学习的通用工作流程】
(1) 定义问题:有哪些数据可用?你想要预测什么? 你是否需要收集更多数据或雇人为数据集手动添加标签?
(2) 找到能够可靠评估目标成功的方法。对于简单任务,可以用预测精度,但很多情况都需要与领域相关的复杂指标。
(3) 准备用于评估模型的验证过程。训练集、验证集和测试集是必须定义的。验证集和测试集的标签不应该泄漏到训练数据中。举个例子,对于时序预测,验证数据和测试数据的时间都应该在训练数据之后。
(4) 数据向量化。方法是将数据转换为向量并预处理,使其更容易被神经网络所处理(数据标准化等)。
(5) 开发第一个模型,它要打败基于常识的简单基准方法,从而表明机器学习能够解决你的问题。事实上并非总是如此!
(6) 通过调节超参数和添加正则化来逐步改进模型架构。仅根据模型在验证集(不是测试集或训练集)上的性能来进行更改。请记住,你应该先让模型过拟合(从而找到比你的需求更大的模型容量),然后才开始添加正则化或降低模型尺寸。
(7) 调节超参数时要小心验证集过拟合,即超参数可能会过于针对验证集而优化。我们保留一个单独的测试集,正是为了避免这个问题!
===============================================================================================
【关键网络架构】
三种常见网络架构:密集连接网络、卷积网络和循环网络,每种类型的网络都针对于特定的输入模式,网络架构(密集网络、卷积网络、循环网络)中包含对数据结构的假设,即搜索良好模型所在的假设空间。
输入模式与之对应的网络架构选择:
| 输入模式 |
架构选型 |
| 向量数据 Vector Data |
Dense层(密集连接网络) |
| 图像数据 Image Data |
Conv2D (二为卷积神经网络) |
| 声音数据Sound Data比如波形 |
Conv1D (首选)和RNN |
| 文本数据Text Data |
Conv1D (首选)和RNN |
| 时间序列数据 Timeseries Data |
RNN (首选)和 Conv1D |
| 视频数据 Video Data |
Conv3D(捕捉运动效果) 或 帧级 Conv2D 和 Conv1D (首选)和RNN |
| 立体数据 Volumetric Data |
Conv3D |
| 其他类型序列数据 Sequence Data |
RNN (时间序列)和 Conv1D |
【三种常见网络架构对比】
1.密集连接网络Densely Connected Networks
密集连接网络是Dense层的堆叠,用于处理向量数据(向量批量)。这种网络假设输入特征中没有特定结构。之所以叫做密集连接,是因为Dense层的每个单元都和其他所有单元相连接。这种层试图映射任意两个输入特征之间的关系,与Conv2D不同,后者仅查看局部关系。
| 问题类型 |
层堆叠 |
损失函数 |
| 二分类 |
最后一层是sigmoid激活且只有一个单元的Dense层 |
binary_crossentropy |
| 单标签多分类 |
最后一层是softmax激活且单元个数=类别个数的Dense层 |
目标是one-hot编码:categorical_crossentropy |
| 多标签多分类 |
最后一层是sigmoid激活且单元个数=类别个数的Dense层 |
目标是k-hot 编码 |
| 连续值回归 |
最后一层是不带激活函数且单元个数 = 要预测的值个数的Dense层 |
常见的损失函数: 1. mean_squred_error MSE 2. mean_absolute_error MAE |
SampleCode:
1.二分类问题:

2.单标签多分类

3.多标签多分类

4.连续值向量的回归

2.卷积神经网络Convnets :平移不变性
卷积层能看到空间局部模式,其方法是对输入张量的不同空间位置(图块)应用相同的几何变换。这使得卷积层能够高效利用高维数据,并且能够高度模块化,适用于任何维度的空间,包括一维(序列)、二维(图像)、三维(立体数据)等。
卷积神经网络或卷积网络是卷积层和最大池化层的堆叠。池化层可以对数据进行空间下采样,这么做有两个目的:随着特征数量的增大,需要让特征图的尺寸保持在合理范围内; 让后面的卷积层能够“看到”输入中更大的空间范围。卷积神经网络的最后通常是一个 Flatten 运算或全局池化层,将空间特征图转换为向量,再是 Dense 层,用于实现分类或回归。
【注意】大部分或者全部普通卷积不久会被深度可分离卷积(depth-wise separable convolution,SeparableConv2D)替代,会得到一个更小、更快的网络,在任务上的表现更好。其优点:速度更快并且效率更高。
SampleCode:

3.循环神经网络RNNs 循环神经网络(RNN,recurrent neural network)的工作原理是对输入序列每次处理一个时间步,并且自始至终保存一个状态(state,这个状态通常是一个向量或一组向量,即状态几何空间中的点)。如果序列中的模式不具有时间平移不变性(比如时间序列数据,最近的过去比遥远的过去更加重要),应该优先使用循环神经网络,而不是一维卷积神经网络。
Keras 中有三种 RNN 层: SimpleRNN、GRU 和 LSTM。对于大多数实际用途,应该使用 GRU 或 LSTM。两者中 LSTM 更加强大,计算代价也更高。可以将 GRU 看作是一种更简单、计算代价更小的替代方法。
想要将多个 RNN 层逐个堆叠在一起,最后一层之前的每一层都应该返回输出的完整序列 (每个输入时间步都对应一个输出时间步)。如果不再堆叠更多的 RNN 层,那么通常只返回最后一个输出,其中包含关于整个序列的信息。

===============================================================================================
机器学习最基本的任务是分类和回归任务。虽然在所有这些任务上都可以训练一个模型,但在某些情况下,这样的模型可能无法泛化到训练数据之外的数据。
【应用场景如下(能做什么)】
1.将向量数据映射到向量数据
· 预测性医疗保健:将患者医疗记录映射到患者治疗效果的预测。
· 行为定向:将一组网站属性映射到用户在网站上所花费的时间数据。
· 产品质量控制:将与某件产品制成品相关的一组属性映射到产品明年会坏掉的概率。
2.将图像数据映射到向量数据
· 医生助手:将医学影像幻灯片映射到是否存在肿瘤的预测。
· 自动驾驶车辆:将车载摄像机的视频画面映射到方向盘的角度控制命令。
· 棋盘游戏人工智能:将围棋和象棋棋盘映射到下一步走棋。
· 饮食助手:将食物照片映射到食物的卡路里数量。
· 年龄预测:将自拍照片映射到人的年龄。
3.将时间序列数据映射为向量数据
· 天气预报:将多个地点天气数据的时间序列映射到某地下周的天气数据。
· 脑机接口:将脑磁图(MEG)数据的时间序列映射到计算机命令。
· 行为定向:将网站上用户交互的时间序列映射到用户购买某件商品的概率。
4.将文本映射到文本
· 智能回复:将电子邮件映射到合理的单行回复。
· 回答问题:将常识问题映射到答案。
· 生成摘要:将一篇长文章映射到文章的简短摘要。
5.将图像映射到文本
-
图像描述:将图像映射到描述图像内容的简短说明。
-
将文本映射到图像
-
条件图像生成:将简短的文字描述映射到与这段描述相匹配的图像。
-
标识生成 / 选择:将公司的名称和描述映射到公司标识。
-
将图像映射到图像
-
超分辨率:将缩小的图像映射到相同图像的更高分辨率版本。
-
视觉深度感知:将室内环境的图像映射到深度预测图。
-
将图像和文本映射到文本
-
视觉问答:将图像和关于图像内容的自然语言问题映射到自然语言答案。
-
将视频和文本映射到文本
-
视频问答:将短视频和关于视频内容的自然语言问题映射到自然语言答案
【局限性(不能做什么)】
一般来说,任何需要推理(比如编程或科学方法的应用)、长期规划和算法数据处理的东西,无论投入多少数据,深度学习模型都无法实现。即使是排序算法,用深度学习网络来学习也是非常困难的。
原因:深度学习模型只是将一个向量空间映射到另一个向量空间的简单而又连续的几何变换链。能做的只是将一个数据流形X映射到另一个流形Y,前提是从X到Y存在任何可学习的连续变换。深度学习模型可以看作是一种程序,但是反过来说,大多数程序都不能被表示为深度学习模型。
1.将ML拟人化的风险
对于大多数任务而言,要么不存在相应的深度学习神经网络能够解决任务,要么即使存在这样的网络,它可能是不可学习的(learnable)。后一种情况的原因可能是响应的几何变换过于复杂,也可能是没有合适的数据用于学习。通过堆叠更多的层并使用更多训练数据来扩展当前的深度学习技术,只能在表面上缓解一些问题,无法解决更根本的问题,比如深度学习模型可以表示的内容非常有限,比如大多数想要学习的程序都不能被表示为数据流形的连续几何变形。
人类的一个基本特征就是我们的心智理论:我们倾向于将意图、信念和知识投射到身边的事物上----这有点儿心理学了。对抗样本尤其能够突出说明这一点,对抗样本是深度学习网络的输入样本,其目的在于欺骗模型对它们进行错误归类。
深度学习模型并不理解它们的输入,至少不是人类所说的理解。人类头脑中的原始模型是从人类作为具身主体的体验发展而来的。避免入坑:即相信神经网络能够理解它们所执行的任务---它们不理解,至少不是我们可以理解的方式。
2.局部泛化与极端泛化
2.1 人类认知---->极端泛化
人类是从具身体验中自我学习的,而不是通过观察显式的训练样例来学习的。人类都是用了一个复杂的抽象模型,并可以利用这些模型来预测各种可能的未来并执行长期规划,可以将已知的概念融合在一起来表示之前从未体验过的事物。比如绘制一匹穿着牛仔裤的马,或者想象我们如果中了彩票会做什么。这种处理假想情况的能力,将人类的心智模型空间扩展到远远超出我们能够直接体验的范围,让我们能够进行抽象和推理,这种能力可以说是人类认知的决定性特征。极端泛化:即只用很少的数据,甚至没有新数据,就可以适应从未体验过的新情况的能力。
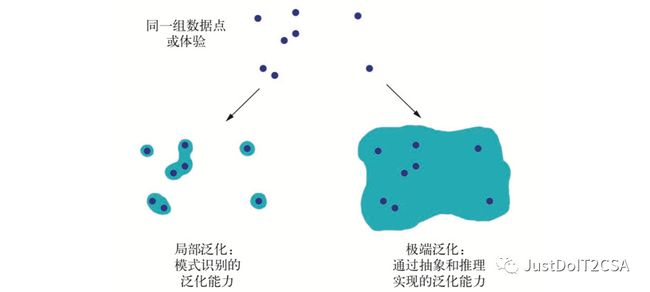
2.2机器学习---->局部泛化
深度学习执行从输入到输出的映射,如果新的输入与网络训练时所见到的输入稍有不同,这种映射就会立刻变得没有意义。两者区别如下:
这个例子挺有意思:如果要开发一个能够控制人体的深度网络,并且希望它学会再城市里安全行走,不会被汽车撞上。那么这个网络不得不再各种场景中死亡数千次,才能推断出汽车是危险的,并做出适当的躲避行为。将这个网络放到一个新城市,它将不得不重新学习已知的大部分知识。但是人类不需要死亡就可以学会安全行为,这也要归功于人类对假想情景进行抽象建模的能力。
深度学习唯一的真正成功之处就是:给定大量的人工标注数据,它能够使用连续的几何变换将空间X映射到空间Y。若想创造出与人类大脑匹敌的人工智能,需要抛弃简单的从输入到输出的映射,转而研究推理和抽象。对各种情况进行抽象建模,一个合适的基础可能是计算机程序,机器学习模型可以被定义为可学习的程序。
【未来前瞻(Keras之父的设想)】
1. 与通用的计算机程序更加接近的模型,它建立在比当前可微层更加丰富的原语之上。这也是实现推理和抽象的方法,当前模型的致命弱点就是缺少推理和抽象。
2. 使上一点成为可能的新学习形式,让模型抛弃可微变换。
3. 需要更少人类工程师参与的模型。不停的调节模型应该是机器的工作,而不是工程师的工作
4. 更好地、系统性地重复使用之前学到的特征和架构,比如使用可复用和模块化子程序的元学习系统。
【Keras之父的言外之意】
A. 模型即程序
将来的一个必要转型:抛弃只能进行纯模式识别并且只能实现局部泛化的模型,转而研究能够进行抽象和推理并且能够实现极端泛化的模型。目前的人工智能程序能够进行基本形式的推理,它们都是由人类程序猿硬编码的,如依赖于搜索算法、图操作和形式逻辑的软件等,如DeepMind的AlphaGo。
一方面将不再使用硬编码的算法智能(手工软件),另一方面不再使用学到的几何智能(深度学习)。将正式的算法模块和几何模块融合在一起,前者可以提供推理和抽象能力,后者可以提供非正式的直觉与模式识别能力。整个系统的学习过程只需要很少人参与,甚至不需要人参与。
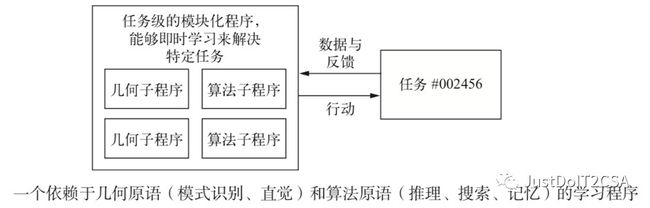
===============================================================================================
程序合成:是指利用搜索算法(在遗传编程中也可能是遗传搜索)来探索可能程序的巨大空间,从而自动生成简单的程序,特别是神经程序合成。
机器学习:程序的巨给定输入/输出作为训练数据,找到一个程序能够将输入映射到输出,还能够泛化到新的输入。
【区别】:程序合成是通过离散的搜索过程来生成源代码,机器学习是通过硬编码的程序(神经网络)中学习参数值。
===============================================================================================
B. 超越反向传播和可微层
如果机器学习模型变得更像程序,那么通常就不再是可微的了。这些程序仍然使用连续的几何层作为子程序,这些子程序是可微的,但整个模型是不可微的。因此,使用反向传播在固定的硬编码的网络中调节权重值,可能不是未来训练模型的首选方法,至少不会只用这种方法。需要找到能够有效地训练不可微系统的方法。目前的方法包括遗传算法、进化策略、某些强化学习方法和交替方向乘子法(ADMM)。当然梯度下降也不会被淘汰,梯度信息对于可微的参数化函数的最优化总是很有用的。但模型会变得越来越不满足于可微的参数化函数,因此模型的自动开发(即机器学习中的学习)需要的也不仅仅是反向传播。
此外,反向传播是端到端的,这对于学习良好的链式变换是很有用的,但它没有充分利用深度网络的模块化,所以计算效率很低。为了提高效率,有一个通用的策略:引入模块化和层次结构。因此可以引入解耦的训练模块以及训练模块之间的同步机制,并用一种层次化的方式来组织,从而使反向传播更加高效。模型在全局上是不可微的(但部分是可微的),使用一种有效的搜索过程(不使用梯度)来训练(生长)模型,而可微的部分则利用更高效版本的反向传播得到的梯度进行训练,其训练速度更快。
C. 自动化机器学习AutoML
第一、超参数调节是一个简单的搜索过程,它由所调节网络的损失函数来定义,建立基本的自动化机器学习(AutoML)系统可以调节堆叠的层数、层的顺序以及每一层中单元或过滤器的个数。
第二、联合学习模型架构和模型权重。每次尝试一个略有不同的架构都要从头训练一个新模型,这种方法效率很低,因此真正强大的AutoML在训练数据上进行反向传播来调节模型特征的同时,还能够不断调节其模型架构。
D.终身学习与模块化子程序复用
如果模型变得更加复杂,并且构建于更加丰富的算法原语之上,对于这种增加的复杂度,需要在不同的任务之间实现更多的复用,而不是每次面对一个新任务或新数据集时,都从头开始训练一个新模型。模型可以自由地操作这些原语来扩展其处理功能:比如if 分支、while语句、变量创建、长期记忆的磁盘存储、排序运算符、高级数据结构(如List、Graph和HashTable)等。
Keras之父经验之谈:训练同一个模型同时完成几个几乎没有联系的任务,这样得到的模型在每个任务山的效果都更好。如联合训练一个图像分类模型和一个图像分割模型,二者共享相同的卷积基,这样得到的模型在两个任务上的表现都变得更好。这是很符合直觉的: 看似无关的任务之间总是存在一些信息重叠,与仅在特定任务上训练的模型相比,联合模型可以获取关于每项任务的更多信息。
如果一个子程序在不同任务和不同领域中都很有用,可以说它对解决问题的某些方面进行了抽象化(abstract)。
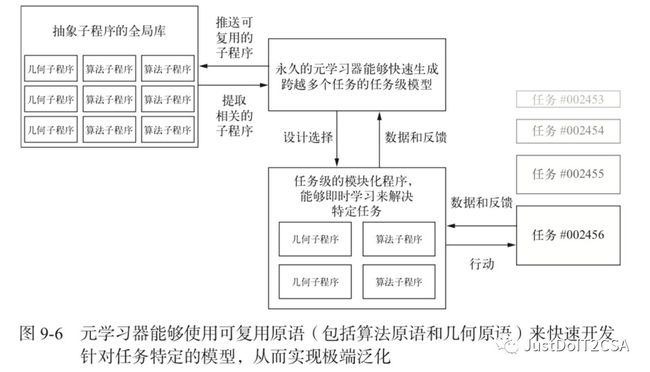
Keras之父长期愿景:
· 模型将变得更像程序,其能力将远远超出目前对输入数据所做的连续几何变换。这些程序可以说是更加接近于人类关于周围环境和自身的抽象心智模型。因为它们具有丰富的算法特性,所以还具有更强的泛化能力。
· 具体而言,模型将会融合算法模块与几何模块,前者提供正式的推理、搜索和抽象能力,后者提供非正式的直觉和模式识别能力。AlphaGo(这个系统需要大量的手动软件工程和人为设计决策)就是这种符号人工智能和几何人工智能融合的一个早期例子。
· 通过使用存储在可复用子程序的全局库(这个库随着在数千个先前任务和数据集上学习高性能模型而不断进化)中的模块化部件,这种模型可以自动成长(grow),而不需要人类工程师对其硬编码。随着元学习系统识别出经常出现的问题解决模式,这些模式将会被转化为可复用的子程序(正如软件工程中的函数和类),并被添加到全局库中。这样就可以实现抽象。
· 这个全局库和相关的模型成长系统能够实现某种形式的与人类类似的极端泛化:给定一个新任务或新情况,系统使用很少的数据就能组合出一个适用于该任务的新的有效模型,这要归功于丰富的类似程序的原语,它具有很好的泛化能力,还要归功于在类似任务上的大量经验。按照同样的方法,如果一个人具有很多以前的游戏经验,那么它可以很快学会玩一个复杂的新视频游戏,因为从先前经验得到的模型是抽象的、类似程序的,而不是刺激与行动之间的简单映射。
· 因此,这种永久学习的模型生长系统可以被看作一种通用人工智能(AGI,artificial general intelligence)。但是不要指望会出现奇点式的机器人灾难,那纯粹只是幻想,自于人们对智能和技术的一系列深刻误解。