大数据Spark“蘑菇云”项目实战第63课: 广告点击系统高可用性和性能优化 checkpoint wal driver高可用 并行度配置
大数据Spark“蘑菇云”项目实战第63课: 广告点击系统高可用性和性能优化
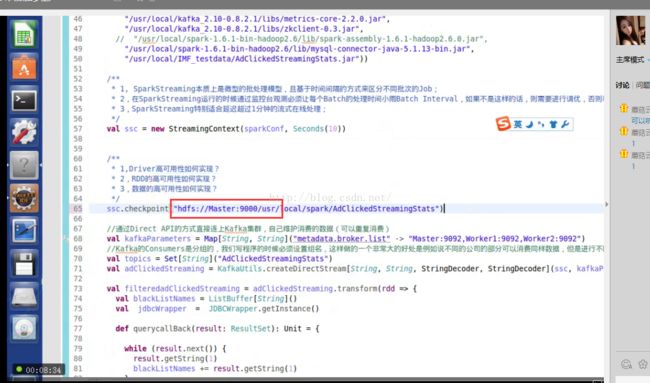
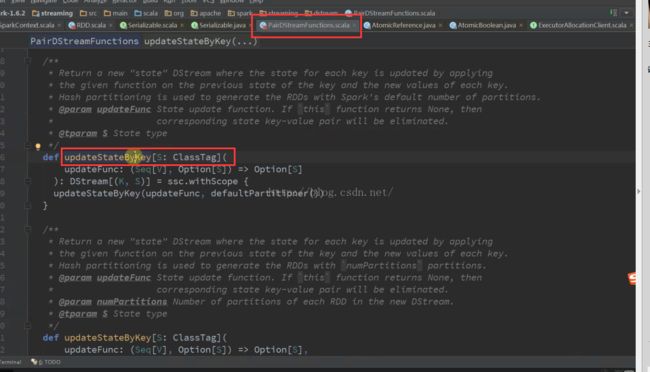
1, 对于window、updateStateByKey等DStream的状态操作,采用HDFS的checkpoint机制;
61课程:时间函数
62课程:
分层代码
63课程 高可用性
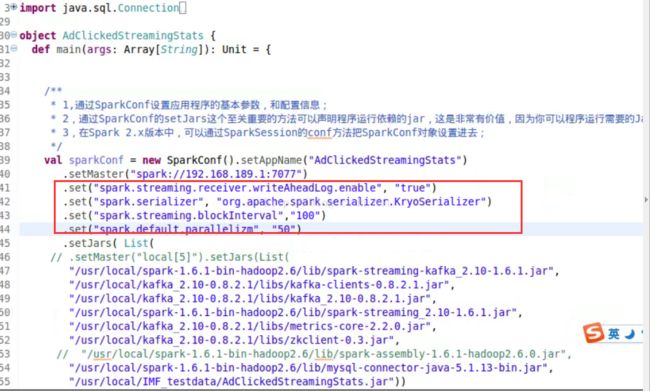
1、checkpoint 存放hdfs
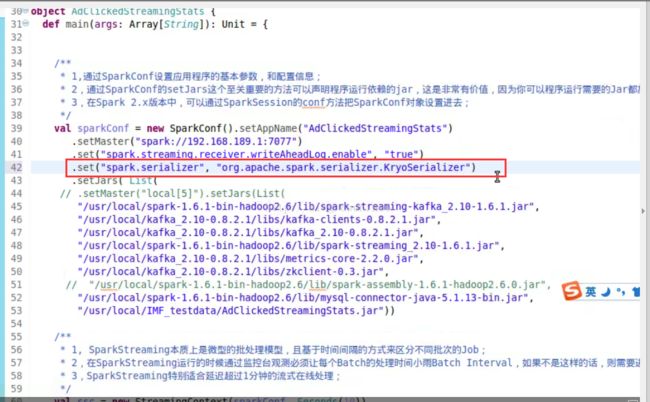
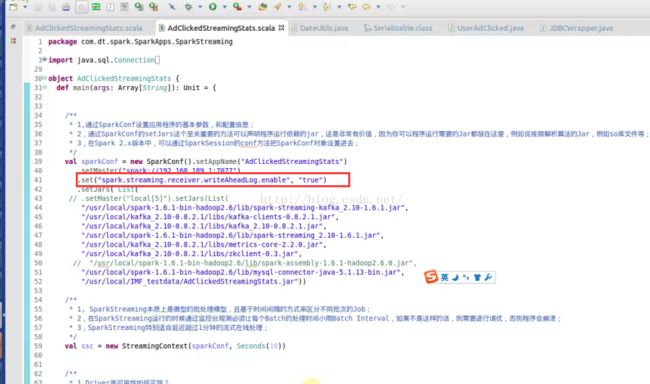
2、 RDD高可用性,WAL 的高可用性 配置
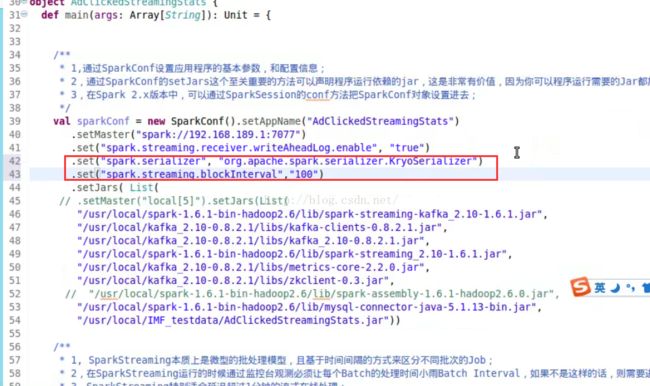
writeAheadLog.enable true
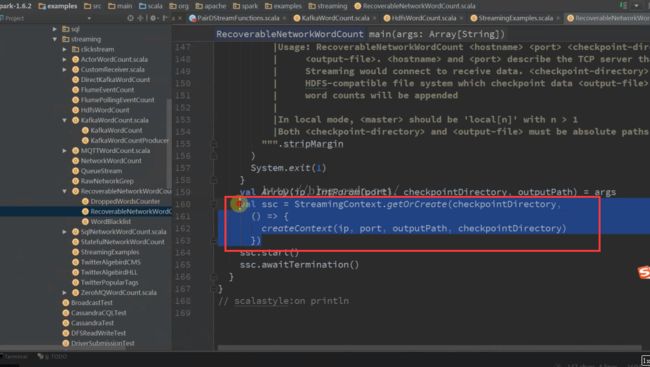
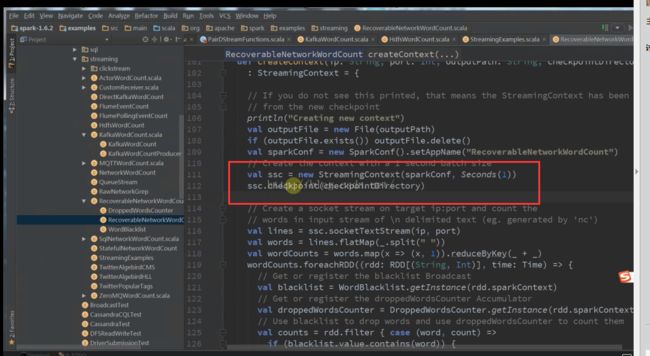
3、driver的可用性
Driver的高可用性 val ssc = StreamingContext.getOrCreate(checkpointDirectory,
() => {
createContext(ip, port, outputPath, checkpointDirectory)
})
4、配置spark streaming的副本 副本用多一点,使用数据本地性 空间换时间
性能优化
1,提升并行度:减少spark.streaming.blockInterval的时间,例如说变成100ms,使用多个DStream并行化接受数据,
spark.default.parallelism
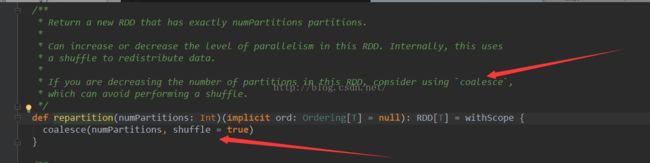
2,如果进行多次filter操作之后需要coalesce