Python Scrapy爬虫实战(1):豆瓣网站图书信息案例- Scrapy初体验
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
我们将通过Scrapy实现一个豆瓣网站图书信息案例。
- 在开始爬取之前, 创建一个新的Scrapy项目。
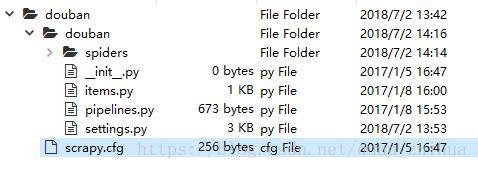
scrapy startproject douban 命令将会创建包含下列内容的目录:
- 定义Item
Item 是保存爬取到的数据的容器;其使用方法和python字典类似; 可以理解为JAVA的javabean,scala的case class。
# -*- coding: utf-8 -*-
import scrapy
class DoubanBookItem(scrapy.Item):
name = scrapy.Field() # 书名
price = scrapy.Field() # 价格
edition_year = scrapy.Field() # 出版年份
publisher = scrapy.Field() # 出版社
ratings = scrapy.Field() # 评分
author = scrapy.Field() # 作者
content = scrapy.Field()
- 编写第一个爬虫(Spider)
Spider是用于从豆瓣网站爬取图书数据。包含一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。为了创建一个Spider,必须继承 scrapy.Spider 类, 且定义以下三个属性:name: 用于区别Spider。 该名字必须是唯一的。start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
# -*- coding:utf-8 -*-
import scrapy
from douban.items import DoubanBookItem
class BookSpider(scrapy.Spider):
name = 'douban-book'
allowed_domains = ['douban.com']
start_urls = [
'https://book.douban.com/top250'
]
def parse(self, response):
# 请求第一页
yield scrapy.Request(response.url, callback=self.parse_next)
# 请求其它页
for page in response.xpath('//div[@class="paginator"]/a'):
link = page.xpath('@href').extract()[0]
yield scrapy.Request(link, callback=self.parse_next)
def parse_next(self, response):
for item in response.xpath('//tr[@class="item"]'):
book = DoubanBookItem()
book['name'] = item.xpath('td[2]/div[1]/a/@title').extract()[0]
book['content'] = item.xpath('td[2]/p/text()').extract()[0]
book['ratings'] = item.xpath('td[2]/div[2]/span[2]/text()').extract()[0]
yield book
- Pipline中解析Item信息。pipelines.py
# -*- coding: utf-8 -*-
class DoubanBookPipeline(object):
def process_item(self, item, spider):
info = item['content'].split(' / ') # [法] 圣埃克苏佩里 / 马振聘 / 人民文学出版社 / 2003-8 / 22.00元
item['name'] = item['name']
item['price'] = info[-1]
item['edition_year'] = info[-2]
item['publisher'] = info[-3]
return item- settings.py配置运行的pipline。
ITEM_PIPELINES = {
'douban.pipelines.DoubanBookPipeline': 300,
}Scrapy开始运行爬虫。
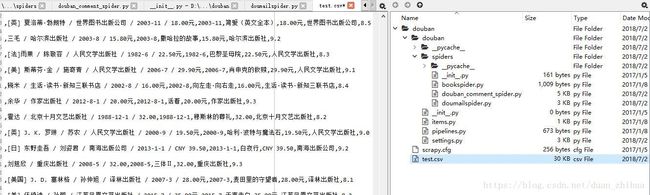
scrapy crawl douban-book -o test.csv1,运行 scrapy crawl douban-book -o test.csv,提示报错。ModuleNotFoundError: No module named 'faker'
D:\PycharmProjects\dzh_July_spyder_robot\class6\douban\douban> scrapy crawl douban-book -o test.csv
Traceback (most recent call last):
File "G:\ProgramData\Anaconda3\Scripts\scrapy-script.py", line 5, in
sys.exit(scrapy.cmdline.execute())
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\cmdline.py", line 108, in execute
settings = get_project_settings()
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\utils\project.py", line 68, in get_project_settings
settings.setmodule(settings_module_path, priority='project')
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\settings\__init__.py", line 292, in setmodule
module = import_module(module)
File "G:\ProgramData\Anaconda3\lib\importlib\__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "", line 994, in _gcd_import
File "", line 971, in _find_and_load
File "", line 955, in _find_and_load_unlocked
File "", line 665, in _load_unlocked
File "", line 678, in exec_module
File "", line 219, in _call_with_frames_removed
File "D:\PycharmProjects\dzh_July_spyder_robot\class6\douban\douban\douban\settings.py", line 19, in
from faker import Factory
ModuleNotFoundError: No module named 'faker'
2)安装 faker安装包。
(g:\ProgramData\Anaconda3) C:\Users\lenovo>pip install faker
Collecting faker
Downloading https://files.pythonhosted.org/packages/e3/d8/e4967bdae2961bb4ab8e23ace6fcef74312fdefae591a46424b8568e16ee/Faker-0.8.16-py2.py3-none-any.whl (742kB)
100% |████████████████████████████████| 747kB 113kB/s
Requirement already satisfied: six>=1.10 in g:\programdata\anaconda3\lib\site-packages (from faker) (1.11.0)
Collecting text-unidecode==1.2 (from faker)
Downloading https://files.pythonhosted.org/packages/79/42/d717cc2b4520fb09e45b344b1b0b4e81aa672001dd128c180fabc655c341/text_unidecode-1.2-py2.py3-none-any.whl (77kB)
100% |████████████████████████████████| 81kB 111kB/s
Requirement already satisfied: python-dateutil>=2.4 in g:\programdata\anaconda3\lib\site-packages (from faker) (2.6.1)
notebook 5.4.0 requires ipykernel, which is not installed.
micropython-markupbase 3.3.3.post1 requires micropython-re-pcre, which is not installed.
jupyter 1.0.0 requires ipykernel, which is not installed.
jupyter-console 5.2.0 requires ipykernel, which is not installed.
ipywidgets 7.1.1 requires ipykernel>=4.5.1, which is not installed.
twisted 17.5.0 has requirement Automat>=0.3.0, but you'll have automat 0.0.0 which is incompatible.
Installing collected packages: text-unidecode, faker
Successfully installed faker-0.8.16 text-unidecode-1.2
D:\PycharmProjects\dzh_July_spyder_robot\class6\douban\douban> scrapy crawl douban-book -o test.csv
Traceback (most recent call last):
File "G:\ProgramData\Anaconda3\Scripts\scrapy-script.py", line 5, in
sys.exit(scrapy.cmdline.execute())
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\cmdline.py", line 141, in execute
cmd.crawler_process = CrawlerProcess(settings)
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\crawler.py", line 238, in __init__
super(CrawlerProcess, self).__init__(settings)
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\crawler.py", line 129, in __init__
self.spider_loader = _get_spider_loader(settings)
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\crawler.py", line 325, in _get_spider_loader
return loader_cls.from_settings(settings.frozencopy())
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\spiderloader.py", line 45, in from_settings
return cls(settings)
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\spiderloader.py", line 23, in __init__
self._load_all_spiders()
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\spiderloader.py", line 32, in _load_all_spiders
for module in walk_modules(name):
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\utils\misc.py", line 71, in walk_modules
submod = import_module(fullpath)
File "G:\ProgramData\Anaconda3\lib\importlib\__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "", line 994, in _gcd_import
File "", line 971, in _find_and_load
File "", line 955, in _find_and_load_unlocked
File "", line 665, in _load_unlocked
File "", line 674, in exec_module
File "", line 781, in get_code
File "", line 741, in source_to_code
File "", line 219, in _call_with_frames_removed
File "D:\PycharmProjects\dzh_July_spyder_robot\class6\douban\douban\douban\spiders\douban_comment_spider.py", line 44
print 'Copy the link:'
^
SyntaxError: Missing parentheses in call to 'print'. Did you mean print(print 'Copy the link:')?
4)修改print代码,运行。
D:\PycharmProjects\dzh_July_spyder_robot\class6\douban\douban> scrapy crawl douban-book -o test.csv
Traceback (most recent call last):
File "G:\ProgramData\Anaconda3\Scripts\scrapy-script.py", line 5, in
sys.exit(scrapy.cmdline.execute())
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\cmdline.py", line 141, in execute
cmd.crawler_process = CrawlerProcess(settings)
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\crawler.py", line 238, in __init__
super(CrawlerProcess, self).__init__(settings)
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\crawler.py", line 129, in __init__
self.spider_loader = _get_spider_loader(settings)
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\crawler.py", line 325, in _get_spider_loader
return loader_cls.from_settings(settings.frozencopy())
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\spiderloader.py", line 45, in from_settings
return cls(settings)
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\spiderloader.py", line 23, in __init__
self._load_all_spiders()
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\spiderloader.py", line 32, in _load_all_spiders
for module in walk_modules(name):
File "G:\ProgramData\Anaconda3\lib\site-packages\scrapy\utils\misc.py", line 71, in walk_modules
submod = import_module(fullpath)
File "G:\ProgramData\Anaconda3\lib\importlib\__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "", line 994, in _gcd_import
File "", line 971, in _find_and_load
File "", line 955, in _find_and_load_unlocked
File "", line 665, in _load_unlocked
File "", line 678, in exec_module
File "", line 219, in _call_with_frames_removed
File "D:\PycharmProjects\dzh_July_spyder_robot\class6\douban\douban\douban\spiders\douban_comment_spider.py", line 5, in
import urlparse
ModuleNotFoundError: No module named 'urlparse' import urlparse
my_url = urlparse.urlparse(url)
改为
import urllib
my_url = urllib.urlparse(url)6)修改代码继续运行,运行OK
D:\PycharmProjects\dzh_July_spyder_robot\class6\douban\douban> scrapy crawl douban-book -o test.csv
2018-07-02 14:26:58 [scrapy.utils.log] INFO: Scrapy 1.3.3 started (bot: douban)
2018-07-02 14:26:58 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'douban', 'FEED_FORMAT': 'csv', 'FEED_URI': 'test.csv', 'NEWSPIDER_MODULE': 'douban.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['douban.spiders'], 'USER_AGENT': 'Opera/9.35.(X11; Linux i686; sk-SK) Presto/2.9.190 Version/11.00'}
2018-07-02 14:26:58 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.feedexport.FeedExporter',
'scrapy.extensions.logstats.LogStats']
2018-07-02 14:26:59 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-07-02 14:26:59 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-07-02 14:26:59 [scrapy.middleware] INFO: Enabled item pipelines:
['douban.pipelines.DoubanBookPipeline']
2018-07-02 14:26:59 [scrapy.core.engine] INFO: Spider opened
2018-07-02 14:26:59 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-07-02 14:26:59 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-07-02 14:26:59 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
2018-07-02 14:26:59 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
2018-07-02 14:27:00 [scrapy.core.engine] DEBUG: Crawled (200) (referer: https://book.douban.com/top250)
2018-07-02 14:27:00 [scrapy.core.engine] DEBUG: Crawled (200) (referer: https://book.douban.com/top250)
2018-07-02 14:27:00 [scrapy.core.engine] DEBUG: Crawled (200) (referer: https://book.douban.com/top250)
2018-07-02 14:27:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://book.douban.com/top250?start=225>
{'content': '(美)鲁思・本尼迪克特 / 吕万和 / 商务印书馆 / 1990-6 / 16.00',
'edition_year': '1990-6',
'name': '菊与刀',
'price': '16.00',
'publisher': '商务印书馆',
'ratings': '8.2'}
2018-07-02 14:27:00 [scrapy.core.engine] DEBUG: Crawled (200) (referer: https://book.douban.com/top250)
2018-07-02 14:27:00 [scrapy.core.engine] DEBUG: Crawled (200) (referer: https://book.douban.com/top250)
2018-07-02 14:27:00 [scrapy.core.engine] DEBUG: Crawled (200) (referer: https://book.douban.com/top250)
2018-07-02 14:27:00 [scrapy.core.engine] DEBUG: Crawled (200) (referer: https://book.douban.com/top250)
2018-07-02 14:27:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://book.douban.com/top250?start=225>
{'content': '张爱玲 / 北京十月文艺出版社 / 2006-12 / 29.80元',
'edition_year': '2006-12',
'name': '倾城之恋',
'price': '29.80元',
'publisher': '北京十月文艺出版社',
'ratings': '8.7'}
2018-07-02 14:27:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://book.douban.com/top250?start=225>
{'content': '[英]毛姆 / 周煦良 / 上海译文出版社 / 2007-3 / 18.00元',
'edition_year': '2007-3',
'name': '刀锋',
'price': '18.00元',
'publisher': '上海译文出版社',
'ratings': '9.0'}
2018-07-02 14:27:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://book.douban.com/top250?start=225>
{'content': '刘慈欣 / 四川科学技术出版社 / 2005-6 / 22.00元',
'edition_year': '2005-6',
'name': '球状闪电',
'price': '22.00元',
'publisher': '四川科学技术出版社',
'ratings': '8.7'}
2018-07-02 14:27:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://book.douban.com/top250?start=75>
{'content': '今何在 / 光明日报出版社 / 2001-4 / 14.80元',
'edition_year': '2001-4',
'name': '悟空传',
'price': '14.80元',
'publisher': '光明日报出版社',
'ratings': '8.4'}
2018-07-02 14:27:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://book.douban.com/top250?start=50>
{'content': '张嘉佳 / 湖南文艺出版社 / 2013-11-1 / CNY 39.80',
'edition_year': '2013-11-1',
'name': '从你的全世界路过',
'price': 'CNY 39.80',
'publisher': '湖南文艺出版社',
'ratings': '7.1'}
2018-07-02 14:27:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://book.douban.com/top250?start=50>
{'content': '郭敬明 / 长江文艺出版社 / 2007-5 / 24.00元',
'edition_year': '2007-5',
'name': '悲伤逆流成河',
'price': '24.00元',
'publisher': '长江文艺出版社',
'ratings': '6.2'}
2018-07-02 14:27:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://book.douban.com/top250?start=225>
{'content': '[美] 斯宾塞·约翰逊 / 吴立俊 / 中信出版社 / 2001-9 / 16.80元',
'edition_year': '2001-9',
'name': '谁动了我的奶酪?',
'price': '16.80元',
'publisher': '中信出版社',
'ratings': '7.1'}
2018-07-02 14:27:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://book.douban.com/top250?start=225>
{'content': '[印] 罗宾德拉纳德·泰戈尔 / 徐翰林 / 哈尔滨出版社 / 2004-6 / 16.80元',
'edition_year': '2004-6',
'name': '飞鸟集',
'price': '16.80元',
'publisher': '哈尔滨出版社',
'ratings': '8.8'} 爬取的结果文件如下: