intellij idea本地开发调试hadoop的方法
转载请注明出处: http://blog.csdn.NET/programmer_wei/article/details/45286749
我的intellij idea版本是14,Hadoop版本2.6,使用《hadoop权威指南》的天气统计源码作为示例。
下面附上源码,数据集在http://hadoopbook.com/code.html可以下载1901和1902两年数据:
- package com.hadoop.maxtemperature;
- import java.io.IOException;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Mapper;
- public class MaxTemperatureMapper
- extends Mapper
- private static final int MISSING = 9999;
- @Override
- public void map(LongWritable key, Text value, Context context)
- throws IOException, InterruptedException {
- String line = value.toString();
- String year = line.substring(15, 19);
- int airTemperature;
- if (line.charAt(87) == '+') { // parseInt doesn't like leading plus signs
- airTemperature = Integer.parseInt(line.substring(88, 92));
- } else {
- airTemperature = Integer.parseInt(line.substring(87, 92));
- }
- String quality = line.substring(92, 93);
- if (airTemperature != MISSING && quality.matches("[01459]")) {
- context.write(new Text(year), new IntWritable(airTemperature));
- }
- }
- }
- package com.hadoop.maxtemperature;
- import java.io.IOException;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Reducer;
- public class MaxTemperatureReducer
- extends Reducer
- @Override
- public void reduce(Text key, Iterable
values, - Context context)
- throws IOException, InterruptedException {
- int maxValue = Integer.MIN_VALUE;
- for (IntWritable value : values) {
- maxValue = Math.max(maxValue, value.get());
- }
- context.write(key, new IntWritable(maxValue));
- }
- }
- package com.hadoop.maxtemperature;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- public class MaxTemperature {
- public static void main(String[] args) throws Exception {
- if (args.length != 2) {
- System.err.println("Usage: MaxTemperature
- System.exit(-1);
- }
- Job job = new Job();
- job.setJarByClass(MaxTemperature.class);
- job.setJobName("Max temperature");
- FileInputFormat.addInputPath(job, new Path(args[0]));
- FileOutputFormat.setOutputPath(job, new Path(args[1]));
- job.setMapperClass(MaxTemperatureMapper.class);
- job.setReducerClass(MaxTemperatureReducer.class);
- job.setOutputKeyClass(Text.class); //注1
- job.setOutputValueClass(IntWritable.class);
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- }
1、首先在hadoop官网上下载hadoop到本地(不需要进行环境变量的配置,仅仅只用下载hadoop的包即可)。
2、打开intellij idea创建一个空项目,并且将源码粘贴进去,如图

2、这时可以看见代码中的许多类是无法识别的,别急。接下来打开project structure,在左侧找到modules
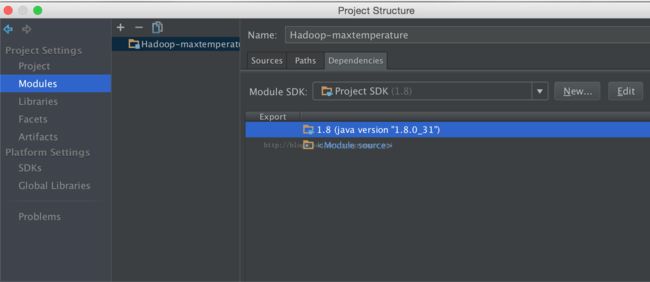
3、点击下方箭头天假jar或目录
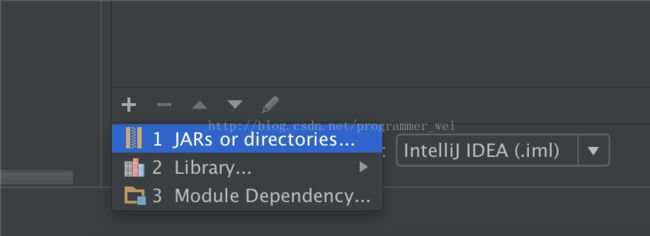
4、将刚才下载的hadoop目录下的share文件夹中的相应目录添加进来
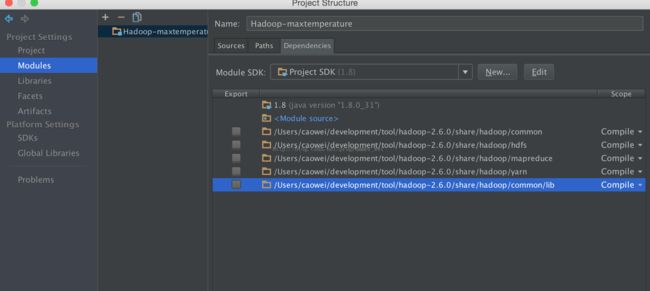
5、点击左侧的artifacts,添加一个空jar

6、输入jar的名称,这里我们输入maxtemperature

7、点击output layout下方的小箭头,选择module output,然后勾选我们的项目,点击确定
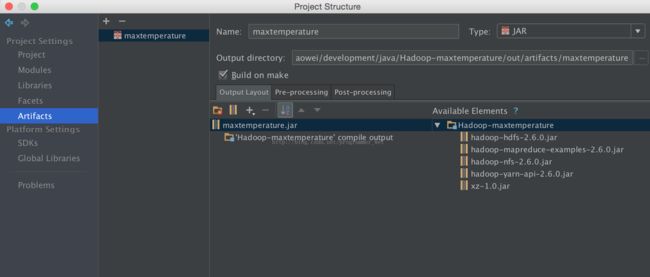
8、这时候,刚才显示的各种包和类的缺失错误信息就全部没有了。
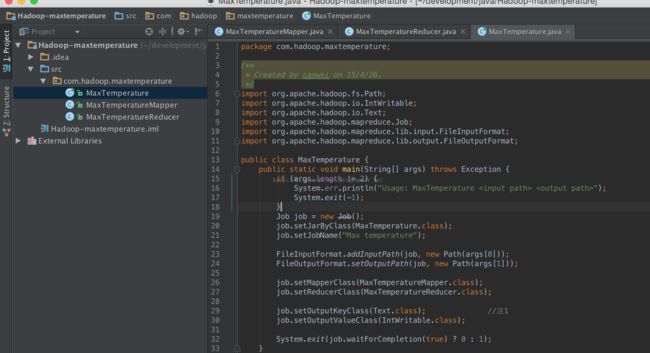
9、接下来,点击右上角的edit configurations,如果当前没有application则新建一个application
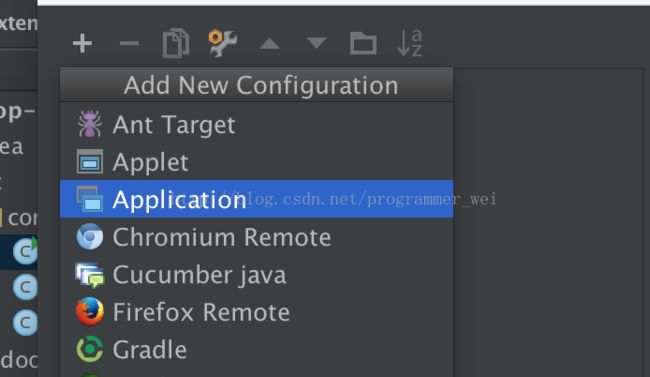
10、application的名字我们这里取MaxTemperature,然后main class需要输入org.apache.hadoop.util.RunJar,再点击program arguments,填写参数,如下:
其中,第一个参数之前在project structure中填写的jar文件路径,第二个参数是输入文件的目录,第二个参数是输出文件的路径
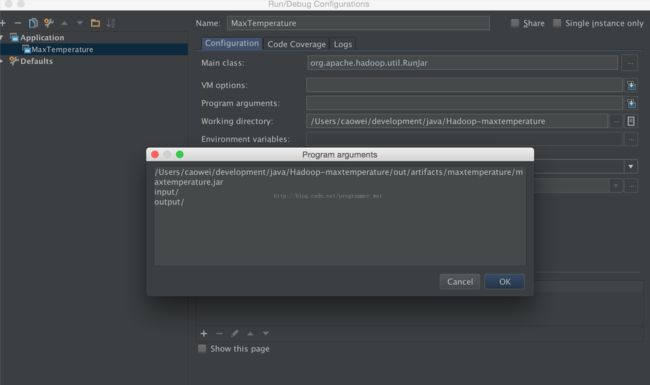
11、然后,我们需要新建一个输入路径,并将输入文件放进去,(输出文件不要创建,这个由系统自己创建)

12、点击运行,却发现有错误提示,显示找不到类:

13、经过查阅资料,发现刚才填写参数的地方着了一个参数,需要将main函数所在类的路径添加进去:

14、再点击运行,发现运行成功

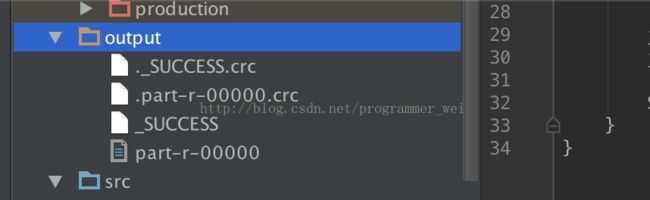
15、这时候,在项目目录下面生成了一个output目录,里面则存放了运行结果

转载请注明出处: http://blog.csdn.Net/programmer_wei/article/details/45286749