机器学习与深度学习系列连载: 第四部分 对抗网络GAN (四) 对抗网络 Cycle GAN
对抗网络GAN (四) 对抗网络 Cycle GAN
我们目前看到的GAN都是有正确结果做参照的GAN(Supervised),但是如果没有正确结果做参照(Unsupuervised)的。
最典型的例子就是风格迁移了(和Style Transfer算法不通,我们这里考虑用GAN),我们要把普通的照片迁移成梵高的画作,以前是没有这样的例子的,无从参考。

我们还可以把进行声音转换:男人的声音转换成女人的

以上就是非监督条件下的结构化数据生成。
1. 直接转换 Direct Transfermation
首先我们需要一个鉴别器D,能够区分正常画作和梵高的画作。 这样,生成器G就需要生成的图片能够“骗过” D

直接转换过程中,我们是有个前提条件的,并不是生成梵高的画作就是好的,我们还有尊重原来照片的内容。

我们需要增加Y到X的生成,进行内容的一致设定,确保照片内容不变形。
这个时候我们需要两个鉴定器Dx(鉴定是不是梵高的画作)和Dy(鉴定是不是普通照片),
还有两个生成器Gx(照片到梵高),Gy(梵高到照片)
-
对于普片转换成梵高的画作,我们针对结果进行限制,是不是很像AutoEncoder
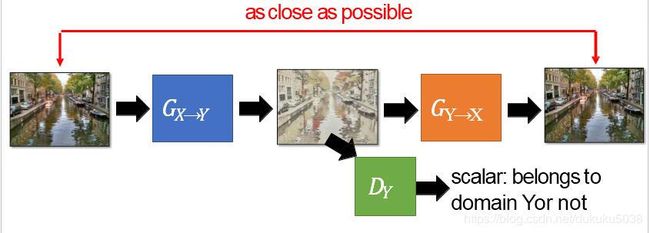
-
对于梵高的画作转换成普通图片,我们结果限制,是不是很像AutoEncoder
-
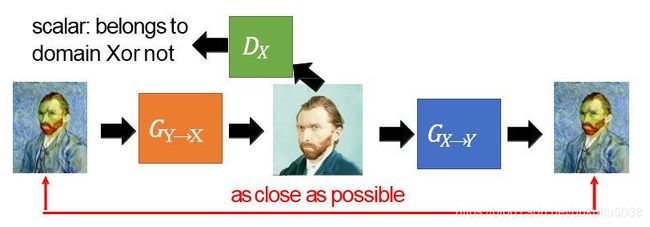
把以上两个结合起来,就是Gycle GAN

2. Star GAN
在Cycle GAN中有Domain X 和 Domain Y之间的互相转换,如果Domain特别多,转换起来的复杂度非常大。 是 C n 2 C^{2}_{n} Cn2中转换方式。 我们需要统一集中的转换。
Star GAN(来自论文Yunjey Choi, arXiv, 2017)就是做一个中心转换节点:
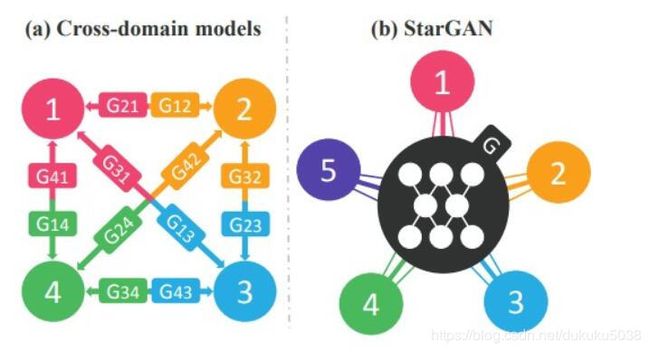
我们举一个实际例子说明问题:
我们的目标是生成一个棕色长发的男子。

lable就是 00101,每一位代表一个domain
同样,我们有不通情绪的domain

然后通过Star GAN进行不通domain间的转换(中间reconstruction的目的是保证图片的内容不失真)
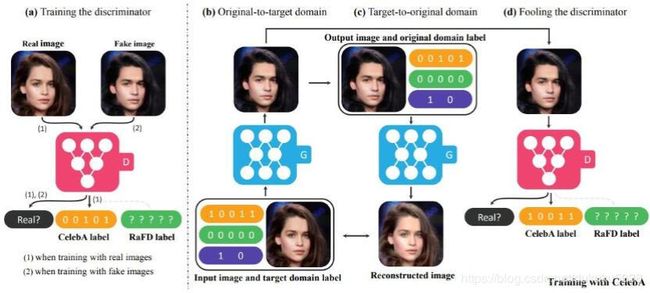
我们修改图片表情也这样:

3.直接投射到普通空间 Projection to Common Space
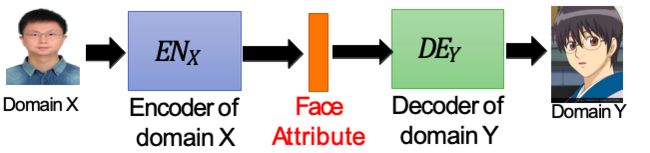
投射的过程很像是Autoencoder的过程。从DomainX (照片)到 DomainY(动漫)
训练的过程:
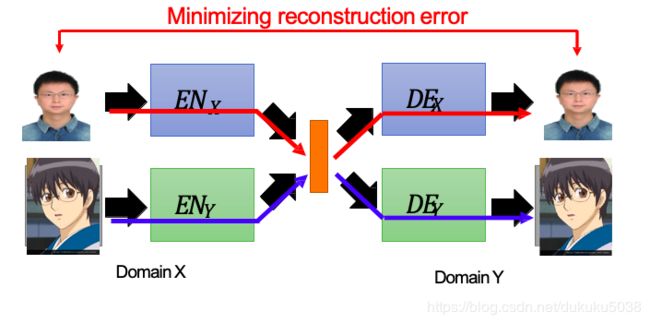
但是上图的训练过程会造成一个现象,两个Autoencoder相对独立,并没有将图片投射到同一个空间。而且没有鉴别器D。
实际上,我们训练的过程:

目标是: encoder 和 Decoder的 参数共享。
训练模型是:(参考
Couple GAN[Ming-Yu Liu, et al., NIPS, 2016]
UNIT[Ming-Yu Liu, et al., NIPS, 2017]
)

4. 声音互转应用
我们从图片的的框框跳出来,用一个人的声音转换成另一个人的声音。
一般的,我们如果用监督学习,必须将两个都都请过来,一起念一些文字(必须是同样的内容),记录声音,然后用监督学习硬train。
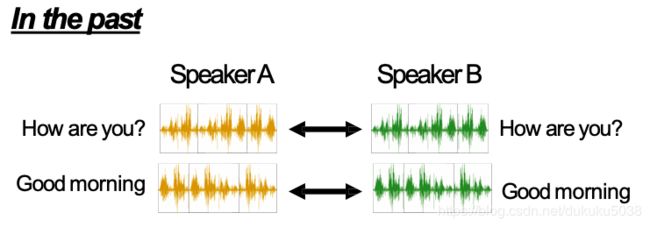
但是使用GAN后,两个人甚至使用的不同语言,说不同的事情(训练数据),都可以用声音互转。(英语发音的人就会用洋腔洋调说中文哦)

本专栏图片、公式很多来自台湾大学李宏毅老师的深度学习课程,在这里,感谢这些经典课程,向李老师致敬!