爬虫实战5—分布式数据库及应用
文章说明:本文是在学习一个网络爬虫课程时所做笔记,文章如有不对的地方,欢迎指出,积极讨论。
一、分布式爬虫
(一)分布式爬虫系统
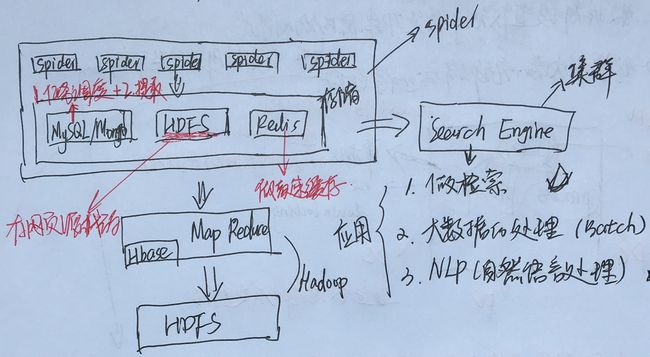
Map Reduce:是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
NLP(Natural Language Processing):自然语言处理。
批处理(Batch):也称为批处理脚本。就是对某对象进行批量的处理,通常被认为是一种简化的脚本语言,它应用于DOS和Windows系统中。批处理文件的扩展名为bat 。
(二)分布式爬虫的作用
1)解决目标地址对IP访问频率的限制
2)利用更高的带宽,提高下载速度 (解决I/O bound)
3)大规模系统的分布式存储和备份
4)数据的扩展能力
(三)将多进程爬虫部署到多台主机上

1)将数据库地址配置到统一的服务器上
2)数据库设置仅允许特定IP来源的访问请求
AGRANT ALL PRIVILIGES ON *.*TO ‘root’@’%’ IDENTIFIED BY ‘password’WITH GRANT OPTIION ; FLUSH PRIVILEGES; (打开外网权限)
Amy.cnf (配置文件)
#bind-address=127.0.0.1
3)设置防火墙,允许端口远程连接
Aiptables –A INPUT –i eth0 –p tcp –m tcp –dport 3306 –j ACCEPT (Linux上设置)
二、分布式爬虫系统—存储
数据库类型
| Type |
Databases |
| RDBMS |
Oracle,MySQL |
| Key-Value |
BerkeleyDB |
| In Memory Key-Value |
MemoryCached,Redis |
| Document |
MongoDB |
| Column |
Hbase |
| Graphic |
Neo4j,Titan |
|
|
行数据库 |
列数据库 |
| 存储方式 |
按数据行存储 |
按数据列存储 |
| 索引方式 |
稠密索引 |
稀疏索引、自动索引化 |
| 查询方式 |
快速查询全部的行数据出来 |
快速查询指定的列数据 |
| 压缩方式 |
低 |
相同列的数据类型相同,可以合并,压缩简单 |
| 存储空间 |
多 |
少 |
| 网络效率 |
低 |
高,由于数据压缩,带来网络流量高 |
| 适 用 |
OLTP(联机事务处理) |
OLAP(联机分析处理) |
数据库(Database):是按照数据结构来组织、存储和管理数据库的仓库。
数据结构(Data Structure):是计算机存储、组织数据的方式,是指相互之间存在一种或多种特定关系的数据元素的集合。
数据结构往往同高效的检索算法和索引技术有关。
数据结构又分为数据的逻辑结构和数据的物理结构。逻辑结构是从逻辑的角度来观察数据,分析数据,与数据的存储位置无关;物理结构是指在计算机中存放的结构,即数据的逻辑结构在计算机中的实现形式,也称存储结构。
关系数据库(Relational Database):是建立在关系数据库模型基础上的数据库,借助于集合代数等概念和方法来处理数据库中的数据,同时也是一个被组织成一组拥有正式描述性的表格,该形式的表格作用的是指是壮哉这数据项的特殊收集体,这些表格中的数据能以许多不同的方式被存取或重新召集而不需要重新组织数据库表格。
SQL:(Structured Query Language)结构化查询语言。
NoSQL:(Not Only SQL)泛指非关系型的数据库。
NoSQL数据库的四大分类:
| 分类 |
典型应用场景 |
数据模型 |
优点 |
缺点 |
| 键值(key-value)存储数据库 |
内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 |
Key 指向 Value 的键值对,通常用hash table来实现 |
查找速度快 |
数据无结构化,通常只被当作字符串或者二进制数据 |
| 列 存储数据库 |
分布式的文件系统 |
以列簇式存储,将同一列数据存在一起 |
查找速度快,可扩展性强,更容易进行分布式扩展 |
功能相对局限 |
| 文档型 存储数据库 |
Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) |
Key-Value对应的键值对,Value为结构化数据 |
数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 |
查询性能不高,而且缺乏统一的查询语法。 |
| 图形 (Graph) 存储数据库 |
社交网络,推荐系统等。专注于构建关系图谱 |
图结构 |
利用图结构相关算法。比如最短路径寻址,N度关系查找等 |
很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案。 |
key-value分布式存储系统:查询速度快、存放数据量大、支持高并发,非常适合通过主键进行查询,但不能进行复杂的条件查询。
(一)爬虫原始数据存储特点
1)文件小,大量KB级别的文件
2)文件数据量大
3)增量方式一次性写入,极少需要修改
4)顺序读取
5)并发的文件读写 (分布式爬取和读取,需支持比较高的I/O)
6)可扩展
SSD:固态硬盘(Solid State Drives),简称固盘,固态硬盘(SolidState Drive)用固态电子存储芯片阵列而制成的硬盘,由控制单元和存储单元(FLASH芯片、DRAM芯片)组成。
OSS:(The Office of Strategic Services)运营支撑系统。是一个综合的业务运营和管理平台,同时也是真正融合了传统IP数据业务与移动增值业务的综合管理平台。OSS是电信运营商的一体化、信息资源共享的支持系统,它主要由网络管理、系统管理、计费、营业、账务和客户服务等部分组成,系统间通过统一的信息总线有机整合在一起。
QPS:(Query Per Second)每秒查询率。
(二)HDFS
HDFS:是Hadoop Distributed File System(Hadoop分布式文件系统)的缩写。它被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它是一个高度容错性的系统,适合部署在廉价的机器上。作为Apache Nutch的基础结构。
容错性(FaultTolerance):指软件检测应用程序所运行的软件或硬件中发生的错误并从错误中恢复的能力,通常可以从系统的可靠性、可用性、可测性等几个方面来衡量。
HDFS可以看做是GoogleFS的开源版本 针对爬虫的解决方案
Google FS:是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,可以提供容错功能。可以给大量的用户提供总体性能较高的服务。
HDFS是把海量小的数据组成数据块存到磁盘上,进行持久化。需要读取数据的时候,一个数据块一个数据块的拿出来。
python hdfsmodule : pip install hdfs
存储到HDFS:
(二)Hbase
1)基于HDFS;
2)基于列的数据库;(大数据里,数据是相对独立的。鲜少进行定向查取。因此,适合用基于列的数据库)
3)can storagehuge size raw data ;
python Hbasemodule : pip install happybase
Hbase的环境搭建:需要先安装Hadoop(教程网址www.tutorialspoint.com)
三、分布式爬虫系统—数据库
(一)MongoDB
MongoDB:是一个基于分布式文件存储的数据库。有c++语言编写。是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似JSON的BSON(BinarySerialized Document Format,二进制形式的存储格式)格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法优点类似于面向对象的查询语言。
1)没有明确的限制(schemaless); (存任务队列)
2)容易扩展(easy ofscale out)
微博就是以MongoDB形式存储的。
innoDB:行级锁
myisam:表级锁
python与mongo之间通过IPC通信。
IPC:(Inter-Process Communication,进程间通信)
Mongo的优化
(二)Redis
快;成本比较高(内存的价格远远大于外部存储);不持久化(需要考虑崩溃后如何进行数据恢复的问题)。
1)基于key value模式的内存数据库(In memory)
2)支持复杂的对象模型(MemoryCached仅支持少量类型)
3)支持Replication(复制),实现集群(MemoryCached不支持分布式部署)
4)所有操作都是原子性(MemoryCached多数操作都不是原子的)
5)可以序列化到磁盘(MemoryCached不能序列化)
Redis:是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
python redis module :pip install redis
| Heap(堆) |
Stack(栈) |
| 空间手动申请和释放,常用new关键字来分配 |
空间由OS自动分配和释放 |
| 空间有很大的自由区 |
空间有限 |
| 随机分配内存,不定长度,存在内存分配和回收的问题 |
内存管理是顺序分配的,而且定长,不存在内存回收问题 |