建筑模式
Christopher Alexander, The Timeless Way of Building, p247, 1979
每个模式是一个由三部分组成的规则,表达了特定环境、问题和解(solution)之间的关系。
作为现实世界的一个成分,每个模式表达了下列三者之间的一种关系:特定环境,在该环境中反复出现的力(forces)的系统,以及协调这些力的某种空间排列。
作为语言的一个成分,每个模式是一条指令,展示了这种空间排列如何被一再重复使用,目的是协调同特定环境相关的力的系统。
简单地说,模式既是存在于现实世界中的事物,又是告诉我们如何以及何时创造该事物的规则。模式既是过程,又是事物;既是活生生的事物的描述,又是创造该事物的过程的描述。
软件体系结构的构建模式
软件体系结构的特点之一就是抽象出了很多常见的系统构建模式,这些模式(或者说结构风格)是系统设计人员多年工作经验的总结。
软件体系结构风格和模式的概念
软件体系结构风格(Architectural Style)
一种体系结构风格以结构组织模式定义了一个系统家族
关于构件和连接件类型的术语;一组约束对它们组合方式的规定;一个或多个语义模型,规定了如何从各成分的特性决定系统整体特性
概括地说,一种软件体系结构风格刻划一个具有共享结构和语义的系统家族
软件体系结构模式(Architectural Pattern)
一种软件体系结构模式是对某个具体环境下问题的结构性解决方法
体系结构风格 (模式系统中的词汇)
目前尚不完善
每个风格可以视为一组构件的集合,以及构件间的交互(连接器)
构件(Components)+ 连接器(Connectors)
E.g. C/S结构中
构件: Client, Server
连接器: C/S间的通讯协议
软件体系结构的构建风格
风格分类:
1. 管道-过滤器风格
2. 面向对象风格
3. 事件驱动风格
4. 分层风格
5. 数据共享风格
6. 解释器风格
7. 反馈控制环风格
8. 异构风格的集成
特别注意:体系结构风格不是对软件进行分类的标准。它仅仅是表示描述软件的不同角度而已
例如一个系统采用了分层风格,但这并不妨碍它用面向对象的方法来实现。同一个系统采用多种风格造成了所谓体系结构风格的异构组合。
管道-过滤器风格
概述
在管道-过滤器风格下,每个功能模块都有一组输入和输出。功能模块称作过滤器(filters);功能模块间的连接可以看作输入、输出数据流之间的通路,所以称作管道(pipes)。
管道-过滤器风格的特性之一在于过滤器的相对独立性,即过滤器独立完成自身功能,相互之间无需进行状态交互。
管道-过滤器风格特性
过滤器是独立运行的构件
非临近的过滤器之间不共享状态
过滤器自身无状态
过滤器对其处理上下连接的过滤器“无知”
对相邻的过滤器不施加任何限制
结果的正确性不依赖于各个过滤器运行的先后次序
各过滤器在输入具备后完成自己的计算。完整的计算过程包含在过滤器之间的拓扑结构中。
管道-过滤器风格
一个管道-过滤器风格的示意图如下图所示:

管道-过滤器风格
一个采用了嵌套的管道过滤器的系统示例:
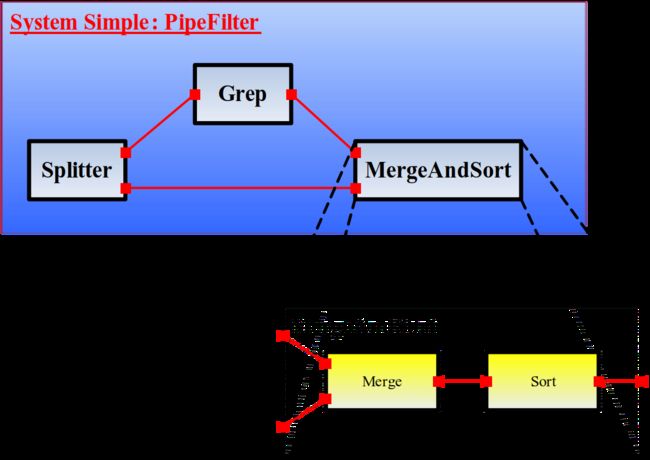
管道-过滤器风格实例
Unix系统中的管道过滤器结构
ls –al | grep my
DOS 中的管道命令
DOS允许在命令中出现用竖线字符“|”分开的多个命令,将符号“|”之前的命令的输出,作为“|”之后命令的输入,这就是“管道功能”,竖线字符“|”是管道操作符。
例如,命令dir | more使得当前目录列表在屏幕上逐屏显示。dir的输出是整个目录列表,它不出现在屏幕上而是由于符号“|”的规定,成为下一个命令more的输入,more命令则将其输入,more命令则将其输入一屏一屏地显示,成为命令行的输出。
管道-过滤器风格 实例
dir | more
管道-过滤器风格实例
通讯协议的信息封装(e.g. SDH)
管道-过滤器风格优点
设计者可以将整个系统的输入、输出特性简单的理解为各个过滤器功能的合成。
设计人员将整个系统的输入输出行为理解为单个过滤器行为的叠加与组合。这样可以将问题分解,化繁为简。将系统抽象成一个“黑箱”,其输入是系统中第一个过滤器的输入管道,输出是系统中最后一个过滤器的输出管道,而其内部各功能模块的具体实现对用户完全透明。
管道-过滤器风格优点
管道-过滤器风格支持功能模块的复用
任何两个过滤器,只要它们之间传送的数据遵守共同的规约,就可以相连接。每个过滤器都有自己独立的输入输出接口,如果过滤器间传输的数据遵守其规约,只要用管道将它们连接就可以正常工作。
管道-过滤器风格优点
基于管道-过滤器风格的系统具有较强的可维护性和可扩展性。
旧的过滤器可以被替代,新的过滤器可以添加到已有的系统上。软件的易于维护和升级是衡量软件系统质量的重要指标之一,在管道-过滤器模型中,只要遵守输入输出数据规约,任何一个过滤器都可以被另一个新的过滤器代替,同时为增强程序功能,可以添加新的过滤器。这样,系统的可维护性和可升级性得到了保证。
管道-过滤器风格优点
支持一些特定的分析,如吞吐量计算和死锁检测等。
利用管道-过滤器风格的视图,可以很容易的得到系统的资源使用和请求的状态图。然后,根据操作系统原理等相关理论中的死锁检测方法就可以分析出系统目前所处的状态,是否存在死锁可能及如何消除死锁等问题。
管道-过滤器风格优点
管道-过滤器风格具有并发性
每个过滤器作为一个单独的执行任务,可以与其它过滤器并发执行。过滤器的执行是独立的,不依赖于其它过滤器的。在实际运行时,可以将存在并发可能的多个过滤器看作多个并发的任务并行执行,从而大大提高系统的整体效率,加快处理速度。
管道-过滤器风格不足
交互式处理能力弱
管道-过滤器模型适于数据流的处理和变换,不适合为与用户交互频繁的系统建模。在这种模型中,每个过滤器都有自己的数据,这些数据或者是从磁盘存储器中读取来,或者是由另一个过滤器的输出导入进来,整个系统没有一个共享的数据区。这样,当用户要操作某一项数据时,要涉及到多个过滤器对相应数据的操作,其实现较为复杂。由以上的缺点,可以对每个过滤器增加相应的用户控制接口,使得外部可以对过滤器的执行进行控制。
管道-过滤器风格不足
管道-过滤器风格不足
管道-过滤器风格往往导致系统处理过程的成批操作。
设计者也许不得不花费精力协调两个相对独立但又存在某种关系的数据流之间的关系,例如多过滤器并发执行时数据流之间的同步问题等。
根据实际设计的需要,设计者也需要对数据传输进行特定的处理(如为了防止数据泄漏而采取加密等手段),导致过滤器必须对输入、输出管道中的数据流进行解析或反解析,增加了过滤器具体实现的复杂性。
管道-过滤器风格实例——数字通信系统
通信的目的是传递消息。消息具有不同的形式,例如:符号、文字、语音、音乐、数据、图片、图像等等。因而,根据所传递消息的不同,目前通信业务可以分为电报、电话、传真、数据传输及可视电话等。对于基本的点对点通信,是把发送端的消息传递到接收端。
管道-过滤器风格实例——数字通信系统
将上图发送端进一步细分为信息源和发送设备,将接收端细分为接收设备和受信者;同时,在通信过程中会有噪声干扰,在模型中添加噪声源可得到图所示的数字通信系统粗略模型。
管道-过滤器风格实例——数字通信系统
图中各单元作用:
信息源把各种可能信息转换成原始电信号;
发送设备对原始电信号完成某种变化,便于原始信号在信道中传输,然后再送入信道;
信道是指信号传输的通道,它既可以看成是管道(因为它的目的并不是为了实现某种功能,仅仅是为了信号的传输),也可以从某种意义上看做是过滤 器(因为信号经过信道后会产生一些变化,比如加入噪声的影响,从而改变 了发送设备发出的信号)。
接收设备从接收信号中恢复出相应的原始信号;
受信者(也称为信息宿或接收终端)是将复原的原始信号转换成相应的消息。
噪声源是信道中的噪声以及分散在通信系统其它各处的噪声的集中体现,它使原信号受到了干扰,产生畸变。
管道-过滤器风格实例——数字通信系统
在数字通信中存在以下几个突出的问题:
数字信号传输时,信道噪声或干扰所造成的差错,原则上都可以通过差错控制编码等手段来控制。为此,在发送端需要增加一个编码器,而在接收 端相应的需要一个解码器。
当需要保密时,可以有效的对基带信号进行加密,防止信息被窃取或通信 被破坏。此时,在接收端就需要进行解密。
由于数字通信传输的是一个接一个按节拍传送的数字信号单元,即码元,因而接收端必须与发送端按相同的节拍进行接收。不然,会因接收节拍不一致而造成混乱,使接收倒的数据全部无效。因此,数字通信系统中必须有同步控制构件。
针对上述问题,可得到数字通信系统详细模型(下图)
管道-过滤器风格实例——数字通信系统
数据源、数据接收端、管道介绍
Data Source (数据源)
input data stream to the system , for example
A file consisting of lines of text
A sensor delivering a sequence of numbers
data can be pushed or pulled into first processing stage
Pipes(管道)
connections between filters , between data source and the first filter , between the last filter and the data sink
synchronizes joined active filters , for example , by a FIFO ( first-in-first-out ) buffer
for passive filters , the pipes can be implemented by a direct call
Make the filter recombination harder
Data Sink (数据接收端)
consumes output data
管道-过滤器风格实例
管道-过滤器模式的体系结构是面向数据流的软件体系结构。它最典型的应用是在编译系统。一个普通的编译系统包括词法分析器,语法分析器,语义分析与中间代码生成器,优化器,目标代码生成器等一系列对源程序进行处理的过程。人们可以将编译系统看作一系列过滤器的连接体,按照管道&过滤器的体系结构进行设计。
需求描述:假设有一批实时的二维坐标点数据需要变换(即对点的横、纵坐标进行缩放),并在屏幕上进行显示,要求外部要能设置变换规则(如缩放倍数)和显示规则(如显示模式和显示颜色)。
管道-过滤器风格实例
体系结构建模
这是一个对坐标点的数据流进行顺序处理的过程,可以应用管道-过滤器体系结构建模。将这个系统分为两个过滤器,一个为坐标点数据流变换过滤器,另一个为坐标点数据流实时显示过滤器。其中,坐标点数据流变换过滤器有一个外部控制接口对变换规则如缩放倍数进行设置,坐标点数据流实时显示过滤器有一个外部控制接口对显示规则如显示模式和显示颜色进行设置。整个系统的体系结构如图所示。
管道-过滤器风格实例
管道-过滤器风格实例
过滤器的设计
可以将过滤器用状态转换图表示。过滤器有如下状态:停止状态,工作状态,等待状态,休眠状态。
停止状态:表示过滤器处于待启动状态,当外部启动过滤器后,过滤器处于处理状态;
处理状态:表示过滤器正在处理输入数据队列中的数据;
等待状态:表示过滤器的输入数据队列为空,此时过滤器等待,当有新的数据输入时,过滤器处于处理状态;
休眠状态:表示过滤器已经启动,但被挂起。挂起的原因可能是由于外界用户要设置过滤器的控制参数,这样暂时将过滤器挂起但不中止它,当控制参数设置完毕后再将过滤器还原,继续运行。这样,实现了较高的效率。
管道-过滤器风格实例
过滤器介绍
过滤器的作用:对输入数据的处理
enriches : computing and adding info
refines : concentrating or extracting info
transforms : delivering data into some other representation
被动式过滤器(Passive filter)
adjacent pipes pulls/pushes output/input data from/into the filter
active either as a function ( pull ) or as a procedure ( push )
主动式过滤器(Active filter)
filter is active in a loop , check the pipes for data
processing on its own as a separate program or thread
管道-过滤器风格的类型
类型
pipelines — linear sequences of filters
bounded pipes — limited amount of data on a pipe
typed pipes — data strongly typed
batch sequential — data streams are not incremental
管道和连接器风格的参考文献
Maurice J. Bach. The Design of the UNIX Operating System, chap. 5, pp. 11-119. Software Series. Prentice Hall, 1986
Norman Delisle and David Garlan. Applying formal specification to industrial problems: A specification of an oscilloscope. IEEE Software, 7(5):29-37, Sept. 1990
J. C. Browne, M. Azam, and S. Sobek. Code: A unified approach to parallel programming. IEEE Software, July 1989.
G. Kahn. The semantics of a simple language for parallel programming. Information Processing, 1974
David Barstow and Alex Wolf. Design methods and software architectures track. In Proceedings of the 7th International Workshop in Software Specification and Design. IEEE Press, 1993
面向对象风格特征
概述
面相对象模式集数据抽象、抽象数据类型、类继承为一体,使软件工程公认的模块化、信息隐藏、抽象、重用性等原则在面向对象风格下得以充分实现。
应用场合
面向对象的体系结构模式适用于数据和功能分离的系统中,同样也适合于问题域模型比较明显,或需要人机交互界面的系统。大多数应用事件驱动风格的系统也常常应用了面向对象风格
面向对象风格设计原则
面向对象风格系统设计时有下述几条基本原则
将逻辑上的实体映射为对象,实体之间的关系映射为对象之间的应用关系。
对象利用应用关系来访问对方公开的接口,完成某个特定任务;一组对象之间相互协作,完成总体目标。
面向对象风格
面向对象风格优点
高度模块性
数据与其相关操作被组织为对象, 成为模块组织的基本单位
封装功能
一组功能和其实现细节被封装在一个对象中,具有功能的接口被暴露出来
代码共享
对象的相对独立性可被反复重用,通过拼装形成不同的软件系统
灵活性
对象在组织过程中,相互关系可以任意变化,只要接口兼容
易维护性
对象接近于人对问题和解决方案模型的思维方式,易于理解和修改
面向对象风格实例——人事档案管理系统
面向对象风格实例——人事档案管理系统
系统功能介绍:
档案管理根据高校人事档案管理的特点,本模块可通过录入各类人事档案信息,来构造档案数据库,编制各种目录索检。针对档案材料录入工作量较大,在该功能模块中设置了多种方式快速录入法,如对指定的部分内容可采用代码录入和菜单选项等输入方法.
信息检索该模块主要是检索有关的人事档案信息,其检索方式为姓氏笔画检索目录。在具体检索中又可分为精确查询和模糊查询,并可将检索内容动态输出,满足档案查询的需要。
档案借阅该模块主要是对档案的借阅情况、归还情况、利用登记等方面进行管理。它能为研究如何更有效地利用人事档案资料提供必要的信息。
面向对象风格实例——人事档案管理系统
档案转递该模块包括人事档案的转进和转出管理,编制清单,并能在档案转递后,对已变更档案数据库进行相应地调整,以完成相应档案的删加。
统计报表该模块主要用于统计库存的各类人事档案的实际数量,及每年归档的各类档案数量,并可完成相应的图形绘制和报表打印。其中,在报表生成中,该模块可根据管理人员对报表的自定义设置来生成相应的非范式报表。
系统维护由于高校人事档案的数据管理是一项非常重要的工作,尤其是它的安全可靠性。因此,在进入本模块操作之前,系统会提醒用户输入姓名、操作口令和权限级别。同时该功能模块还包括操作员管理、口令修改、重新登录、权限级别设置、系统日志及系统初始化六个子模块。
系统帮助本模块提供了在线联机帮助,可实现帮助主题的查询,还提供了计算器、日记/日历等系统工具和关于本系统的简介。
面向对象风格实例——人事档案管理系统
面向对象风格实例——人事档案管理系统
面向对象风格
ODS系统中构件、连接器和配置的模型,如下图所示:
面向对象风格实例
构件的描述方法:利用GUI体系结构框架自动生成工具,可以完成下述几点功能:
生成构件模型,包括构件的属性、接口和实现;
建立连接器模型,包括协议、属性和实现;
体系结构的抽象和封装;
类型和类型检查;
主动规范,提供设计向导;
多视图模式,对不同层次的用户显示不同的内容;
生成实现,如将构件对应为面向对象技术中的类;
将系统的修改动态映射到实现。
面向对象风格实例
面向对象风格实例
具有自适应稳定性的连接器模型
连接器中的通信协议栈
面向对象风格不足
面向对象风格最大的不足在于如果一个对象需要调用另一个对象,它就必须知道那个对象的标识(对象名或对象引用),这样就无形之中增强了对象之间的依赖关系。如果一个对象改变了自己的标识,就必须通知系统中所有和它有调用关系的对象,否则系统就无法正常运行。
事件驱动风格
特征
事件驱动系统的基本观点是一个系统对外部的表现可以从它对事件的处理表征出来。 如图示:
事件驱动风格特征
事件驱动系统具有以下一些特点:
系统是由若干子系统或元素所组成的一个整体;
系统有一定的目标,各子系统在某一种消息机制的控制下,为了这个目标而协调行动;
在某一种消息机制的控制下,系统作为一个整体与环境相适应和协调;
事件驱动风格特征
事件驱动系统具有以下一些特点(续):
在一个系统的若干子系统中,必定有一个子系统起着主导作用,而其他子系统则处于从属地位;
任一系统和系统内的任一元素,都有1个事件收集机制和1个事件处理机制,通过这种机制与周围环境发生作用和联系;
事件驱动风格特征
下图是一个基于事件驱动的软件系统的示意图:
事件驱动风格特征
事件驱动风格系统设计时有下述几条基本原则
从系统论的角度来看待描述的对象,合理分解子系统,保证各个子系统的独立性和社会性;
无论系统多么复杂,子系统性质的差异多么大,任何子系统都可以按照有无子系统这一性质分为2类:管理系统和执行系统。
为了达到系统的目标,系统内的各个子系统通过传递消息和执行消息来协同操作。
为了达到系统的目标,系统内的各个子系统通过传递消息和执行消息来协同操作。
事件驱动风格特征
事件驱动风格系统设计时有下述几条基本原则(续)
在一个完整系统中,必须有这样一个子系统,它没有上级,必须收集系统外的事件及下级发出的事件。
管理类型的子系统一般不执行具体操作,它的主要功能是按照自己的职能指挥下级完成任务,功能性操作一般由执行类型的子系统完成。
在一般情况下,除最高级管理子系统外,子系统一般是“有问才答”,即使在必要的情况下需要积极寻找事件时,也必须征得上级系统得许可,保证了系统的控制流不会分散。
事件驱动风格基本结构
事件驱动系统具有某种意义上的递归性,形成了“部分-整体”的层次结构,可以用属性结构加以表示。一个简单的表示方法是为执行系统定义一些类,另外定义一些类作为这些执行系统的容器类,也就是管理系统。
事件驱动风格
事件驱动风格的基本结构,如下图:
事件驱动风格实例
Java中的button实现
事件驱动风格实例
private void initialize() { //窗口初始化代码
…
//btnPress就是这次点击操作中的事件源
Buttton btnPress = new JButton();
//向事件源btnPress植入侦听器对象ButtonEventHandler
btnPress.addActionListener (new ButtonEventHandler(this));
…
}
class ButtonEventHandler implements ActionListener {
//窗体对象
private EventDemo form = null;
//通过构造体传入窗体对象,
//作用在于让侦听器对象明白事件源处于
//哪个窗体容器中
public ButtonEventHandler(EventDemo form) {
事件驱动风格 实例
this.form = form;
}
//委托方法
public void actionPerformed(ActionEvent e) {
//该方法将会把事件的处理权交给窗体容器类的btnPress_Click方法处理。
this.form.btnPress_Click(e);
}
}
//真正的事件处理代码片断:
private void btnPress_Click(ActionEvent e) {
String message = "你点击的按钮名叫:"
+ ((JButton) e.getSource()).getName();
this.txtMessage.setText(message);
}
事件驱动风格优点
事件驱动风格非常适合于描述系统族,在属于同一族的任何系统中,系统的高级管理子系统的描述是完全类似的,便于重用;
由于最高管理子系统牢牢的掌握着控制权,又因为各同级子系统一般不直接发生关系,因此容易实现并发处理和多任务操作;
基于事件驱动风格的系统具有良好的可扩展性,设计者只需为某个对象注册一个事件处理接口就可以将该对象引入整个系统,同时并不影响其它的系统对象。
事件驱动风格优点
定义了包含执行子系统和管理子系统的类层次结构;
简化客户代码;
使整个系统的设计更具有一般化。
事件驱动风格不足
事件驱动风格最大的不足在于构件削弱了自身对系统计算的控制能力
事件驱动风格中存在的另一个问题在于数据共享
系统中各个对象的逻辑关系变得更加复杂
事件驱动风格和面向对象风格的关系
基于面向对象风格的系统由多个封装起来的对象构成,对象之间通过消息传递实现通信,而事件驱动正是对消息传递机制的一种实现。所以基于事件驱动风格的系统往往都是面向对象的。
事件驱动风格实例
事件驱动风格实例:JavaBean系统概述
事件从事件源到监听者的传递是通过对目标监听者对象的Java方法调用进行的。 对每个明确的事件的发生,都相应地定义一个明确的Java方法。这些方法都集中定义在事件监听者(EventListener)接口中,这个接口要继承java.util.EventListener。
事件驱动风格实例
JavaBean系统(续)
事件状态对象
与事件发生有关的状态信息一般都封装在一个事件状态对象中,这种对象是java.util.EventObject的子类。按设计习惯,这种事件状态对象类的名应以Event结尾。
事件驱动风格实例
JavaBean系统(续)
事件监听者接口(EventListener Interface)与事件监听者
由于Java事件模型是基于方法调用,因而需要一个定义并组织事件操纵方法的方式。JavaBean中,事件操纵方法都被定义在继承了java.util.EventListener类的EventListener接口中,按规定,EventListener接口的命名要以Listener结尾。任何一个类如果想操纵在EventListener接口中定义的方法都必须以实现这个接口方式进行。这个类也就是事件监听者。
事件驱动风格实例
JavaBean系统(续)
事件监听者的注册与注销
为了各种可能的事件监听者把自己注册入合适的事件源中,建立源与事件监听者间的事件流,事件源必须为事件监听者提供注册和注销的方法。在前面的bound属性介绍中已看到了这种使用过程,在实际中,事件监听者的注册和注销要使用标准的设计格式:
public void add< ListenerType>(< ListenerType> listener)
public void remove< ListenerType>(< ListenerType> listener)
事件驱动风格实例
适配类
适配类是JavaBean事件模型中极其重要的一部分。在一些应用场合,事件从源到监听者之间的传递要通过适配类来“转发”。
适配类成为了事件监听者,事件源实际是把适配类作为监听者注册入监听者队列中,而真正的事件响应者并未在监听者队列中,事件响应者应做的动作由适配类决定。
事件驱动风格实例
Turbo Vision
Borland公司开发的Turbo Pascal6.0中提供了一种面向对象的事件驱动程序设计的工具包Turbo Vision。Turbo Vision把各种屏幕上的可见对象归纳为2大类:一类为执行对象,另一类为管理对象,分别称为TView和TGroup类对象。又因为TGroup和TView类有相同之处,故TGroup是从TView派生而得,在Turbo Vision中,TGroup类的对象一般不进行实际操作,不直接在屏幕上显示自己,而是通过自己的下属显示自己,所有的实际操作都是通过TView类对象进行的。
事件驱动风格实例
Turbo Vision 很好地体现了面向对象方法和事件驱动程序设计方法的精髓,TApplication是一个可以运行的交互式程序对象,除了启动和退出之外,它不提供任何功能,使用Turbo Vision,就能高效和快速地开发出高质量地应用程序。
事件驱动风格实例
Turbo Vision
事件驱动风格实例
Turbo Vision
事件驱动风格实例
Turbo Vision
事件驱动风格实例
Turbo Vision
分层风格
特征
一个分层系统采用层次化的组织方式构建,系统中的每一层都要承担两个角色。
首先,它要为结构中的上层提供服务;
其次,它要作为结构中下面层次的客户,调用下层提供的功能函数。
分层风格特征
一个概念上的分层模型如下图所示:
分层风格优点
分层风格具有一些系统设计者无法抗拒的优势:
分层风格支持系统设计过程中的逐级抽象
基于分层风格的系统具有较好的可扩展性
分层风格支持软件复用
分层风格不足
并不是所有的系统都适合用分层风格来描述的
对于抽象出来的功能具体应该放在哪个层次上也是设计者头疼的一个问题
分层风格实例
分层风格实例:计算机网络的设计
概述
网络协议设计者将计算机网络中的各个部分按其功能划分为若干个层次(Layer),其中的每一个层次都可以看成是一个相对独立的黑箱、一个封闭的系统。用户只关心每一层的外部特性,只需要定义每一层的输入、数据处理和输出等外部特性。
分层风格实例
ISO/OSI网络体系结构
分层风格实例
ISO/OSI网络体系结构
分层风格实例
ISO/OSI网络体系结构
为了理解ISO/OSI各层的功能,以运输公司进行货物运输为例来进行说明,也就是利用人们熟知的东西来理解陌生抽象的概念。其中,第1~3层3个层次相当于由运输公司负责的货物运输过程中的具体细节、具体操作方式;第4层相当于运输公司与用户之间的接口;第5~7层3个层次相当于由用户公司负责的将货物交去运输所需要做的准备工作。
第1层是物理层(Physical Layer),它负责在物理信道上传输原始的数据bit流。它应该提供为建立、维护和拆除物理链路连接所需的机械的、电气的、功能和规程的特性,这类似于运输车辆只需要负责将装在车辆内的货物(类似于bits)运送到某地就行了。
分层风格实例
第2层是数据链路层(Data Link Layer),它的主要功能是纠错和流量控制,负责在可能出现差错的物理线路中实现无差错的数据传送。它应该在物理层的基础上,建立相邻结点之间的数据链路,通过差错控制提供数据帧(Frame)的无差错传输,并进行数据流量控制。这类似于运输公司的运输管理和质量监督部门,需要负责在可能出现问题的运输线路之中保质保量地完成运输任务。
分层风格实例
第3层是网络层(Network Layer),它的主要功能是路由控制(找路)、拥塞控制和数据打包。它应该为其上一层传输层的数据传输提供建立、维护和终止网络连接的手段,把上层传来的数据分割成一个一个的数据包(Packet,也叫报文分组)在结点之间进行交换传送,并且负责路由控制和拥塞控制。这类似于运输公司需要将用户发送的货物进行分割打包,并在现有的交通网络之中负责找出一条从源地址到目的地址的线路(即找路),在找路时需要考虑到能否到达、拥塞状况、安全可靠性、甚至交通费用等诸多方面的因素。
分层风格实例
第4层是传输层(Transport Layer),它的主要功能是在上层和下层之间起到一种接口的功能。它应该为上层提供端到端(最终用户到最终用户)、的透明的、可靠的数据传输服务。所谓透明的传输是指在通信过程中上层可以将下面各层看作是一个封闭的黑箱系统,传输层对上层屏蔽了传输系统的具体细节。这类似于运输公司在各个地方设置的业务接洽处,它负责在用户和公司之间建立起一个货物交接的桥梁,使得用户不用去管运输公司将以什么样的方式将货物运送到目的地,也就是说业务接洽处对用户屏蔽了货物运输中的具体细节。
分层风格实例
第5层是会话层(Session Layer),它的主要功能是负责收发数据的交接工作、并组织和管理数据。它应该为表示层提供建立、维护和结束会话连接的功能,并提供会话管理服务。这类似于用户公司的货物收发室,它负责与运输公司打交道,完成用户公司货物的收发的交接工作、并组织管理公司内部要收发的货物。
分层风格实例
第6层是表示层(Presentation Layer),它的主要功能是为数据提供收发、存放的具体格式和规范。它应该为应用层提供信息表示方式的服务,如数据格式的变换、文本压缩、加密技术等。这类似于用户公司的货物收发员,它负责与用户公司内部要收发货物的部门或个人打交道,在收集要发送的货物时告诉用户应该怎样填写发货资料,在向用户发放货物时告诉用户应该完清哪些具体手续,等等。
分层风格实例
第7层是应用层(Application Layer),它的主要功能是为数据提供各种可行的收发方式。它应该为网络用户或应用程序提供各种应用服务,如文件传输、电子邮件(E-mail)、分布式数据库、网络管理等。这类似于用户公司内部的部门或个人在收发货物时,都必须遵循用户公司内部的有关规定,只能使用用户公司所允许的方式来收发货物。从另一方面来说,用户公司也要为公司内部的部门或个人收发货物提供各种可行的收发方式,让用户公司内部的部门或个人知道他们能够使用哪些方式来收发货物。
分层风格
ISO/OSI层次分组关系 :有两种分组方法
I第一种可以从数据处理分工的角度,将ISO/OSI七个层次分为三组:第1、2层解决有关网络信道问题;第3、4层解决传输服务问题;第5、6、7层则处理对应用进程的访问。
从数据传输控制的角度,将ISO/OSI七个层次分为三组:下三层(1、2、3层)可以看作是传输控制组,负责通信子网的工作,解决网络中的通信问题;上三层(5、6、7层)为应用控制组,负责有关资源子网的工作,解决应用进程之间的信息转换问题;中间层(4层)则为通信子网和资源子网的接口,起到连接传输和应用的作用。
分层风格实例
.Net平台也是一个明显的分层系统:
分层风格实例
.Net 框架分层模图
数据共享风格
特征
采用数据共享风格构建的系统中通常有两个截然不同的功能构件;
中央数据单元构件;
一些相对独立的构件的集合。
数据共享风格特征
数据共享风格的示意图如下图所示:
数据共享风格
信息交互方式的差异导致了控制策略的不同。主要的控制策略有两种,正是依据这两种不同的控制策略,基于数据共享风格的系统被分成两个子类:
基于传统数据库型数据共享风格的应用系统
基于黑板型数据共享风格的应用系统
下面主要介绍基于黑板型数据共享风格的应用系统
数据共享风格
一个典型的黑板型数据共享系统包括以下三个部分:
知识源:知识源中包含独立的、与应用程序相关的知识,知识源之间不直接进行通讯,它们之间的交互只通过黑板来完成。
黑板数据结构:黑板数据是按照与应用程序相关的层次来组织的解决问题的数据,知识源通过不断地改变黑板数据来解决问题。
控制:控制完全由黑板的状态驱动,黑板状态的改变决定使用的特定知识。
黑板模式对于无确定性求解策略的问题比较有用,在专家系统中,这种模式应用的比较广泛。
数据共享风格优点
解决问题的多方法性:
对于一个专家系统,针对于要解决的问题,如果在其领域中没有独立的方法存在,而且对解空间的完全搜索也是不可行的,在黑板模式中可以用多种不同的算法来进行试验,并且也允许用不同的控制方法。
具有可更改性和可维护性:
因为在黑板模式中每个知识源是独立的,彼此之间的通信通过黑板来完成,所以这使整个系统更具有可更改性和可维护性。
数据共享风格优点
有可重用的知识源:
由于每个知识源在黑板系统中都是独立的,如果知识源和所基于的黑板系统有理解相同的协议和数据,我们就可以重用知识源。
支持容错性和健壮性:
在黑板模式中所有的结果都是假设的,并且只有那些被数据和其它假设强烈支持的才能够生存。这对于噪声数据和不确定的结论有很强的容错性。
数据共享风格缺点
测试困难:
由于黑板模式的系统有中央数据构件来描述系统的体现系统的状态,所以系统的执行没有确定的顺序,其结果的可再现性比较差,难于测试。
不能保证有好的求解方案:
一个黑板模式的系统所提供给我们的往往是所解决问题的一个百分比,而不是最佳的解决方案。
效率低:
黑板模式的系统在拒绝错误假设的时候要承受多余的计算开销,所以导致效率比较低。
数据共享风格缺点
开发成本高:
绝大部分黑板模式的系统需要用几年的时间来进化,所以开发成本较高。
缺少对并行机的支持:
黑板模式要求黑板上的中心数据同步并发访问,所以缺少对不并行机的支持。
数据共享风格实例
数据共享风格实例:专家系统(ES,Expert System) 概述:
专家系统实质就是一组程序;
从功能上:可定义为“一个在某领域具有专家水平解题能力的程序系统”,能像领域专家一样工作,运用专家积累的工作经验与专门知识,在很短时间内对问题得出高水平的解答。
从结构上讲:可定义为“由一个专门领域的知识库,以及一个能获取和运用知识的机构构成的解题程序系统”。
数据共享风格实例
ES一般结构如下图所示:
数据共享风格实例系统
IECRMAS知识生态系统
IECRMAS知识生态系统知识流
IECRMAS知识生态系统
信用评估知识库的形成
IECRMAS知识生态系统
IECRMAPS知识生态系统中知识流动
个体知识进化图
解释器风格
特征
基于解释器风格的系统核心在于虚拟机。
一个基于解释器风格的系统通常包括:正在被解释执行的伪码和解释引擎;
伪码:由需要被解释执行的源代码和解释引擎分析所得的中间代码组成;
解释引擎包括:语法解释器和解释器当前的运行状态
解释器风格特征
解释器风格示意图如下图所示:
解释器风格优点
在文法规则比较简单的情况下,解释器风格工作的很好;
易于改变和扩展文法。因为解释器风格使用类来表示文法规则,用户可以使用继承来改变和扩展文法。已有的表达式可以采用增量的方式逐渐扩充,而新的表达式可以定义为旧表达式的变体;
易于实现文法。
可以用多种操作来“解释”一个句子。
解释器风格缺点
无法解释复杂的文法规则:对于比较简单的文法规则,解释器风格工作的很好,而对于复杂的文法规则,则由于文法层次的庞大而难于管理;
应用范围比较狭窄;
在文法规则比较复杂,则文法的层次变得无法管理,系统中需要包含许多表示文法规则的类。
解释器风格实例
解释器风格实例:一个布尔表达式解释器
目标:布尔表达式求值系统
现定义由如下文法定义的布尔正则表达式
编译器(1)
系统的体系结构可以随技术的发展而发生变化
传统的编译器模型
具有共享符号表的传统编译器模型
编译器(2)
随着时间的推移,编译技术变得更加复杂,更多的注意力转移到程序在编译过程的中间表示,例如属性文法树
典型的现代编译器模型
解释器风格实例
布尔表达式求值系统类图 ,如下图所示:
解释器风格示例
布尔表达式抽象语法树实例,如下图所示:
解释器风格实例
布尔表达式求值系统的优缺点:
在文法规则比较简单的情况下,解释器风格工作的很好,但如果文法规则复杂,则文法的层次变得庞大而无法管理,系统中需要包含许多表示文法规则的类。
最高效的解释器通常不是通过直接解释语法分析数实现的,而是首先将它们转换成另一种形式。
易于改变和扩展文法。
易于实现文法。
解释器风格实例
布尔表达式求值系统中的角色:
BooleanExpression(抽象布尔表达式)
TerminalExpression(终结符表达式,如VariableExpresssion和Constant)
NonterminalExpression(非终结符表达式,如AndExpression、OrExpression和NotExpression)
Context(上下文,也就是“解释引擎内部状态”)
Client(客户)
解释器风格实例
布尔表达式求值系统的实现
在具体实现布尔表达式求值系统时还有许多细节的问题要处理,这些细节问题处理的好坏甚至会直接影响整个系统的性能。这些问题主要表现在以下几个方面:
创建抽象语法树
定义求值操作
共享终结符
解释器风格示例
解释器风格定义了特定语言的文法表示和解释该文法的解释器。这种模式如同乐谱。其中,音阶和它的持续时间可以用五线谱上的符号表示。这些符号就是音乐语言。音乐家按照乐谱演奏,就可以反复重现同样的音乐。
解释器实例
解释器实例
解释器实例
Javascript 语言解释器JlBrowers
1. 词法分析
以嵌入在html文本中的JS脚本程序为输入形成单词链表,以便语法分析。单词链表为双向链表。
2. 语法分析
以单链表为输入,依JS语言的语法规则形成中间数据结构。中间数据结构能够反映出程序语句描述的数据处理流程。
3. 解释执行器
以中间数据结构为输入负责对语句解释执行的控制。
解释器实例
4. 语句解释器
完成各类型控制语句的解释执行,该模块可能会调用解释执行器而形成递归调用。
5. 表达式规约器
由语句解释器来调用,它负责在语句解释执行过程中完成各类型表达式的运算和赋值语句的执行。
6. 与浏览器交互
完成在表达式运算过程中对当前文档对象和html 文本中各种控件对象的属性值的修改并通过改变浏览器的输出显示表现出来。
解释器实例
Javascript 语言解释器JlBrowers模块图
解释器实例
AbstractExpression (Expression)
声明执行特定操作的接口。
TerminalExpression ( ThousandExpression, HundredExpression, TenExpression, OneExpression )
实现一个与语法中终结符相关的解释操作。
句子中的每一个终结符都需要一个实例。
NonterminalExpression
语法中的每个规则R ::= R1R2...Rn 都需要这样的一个类。
管理从R1到Rn每一个符号的AbstractExpression类型变量的实例。
实现语法中非终结符的解释操作,在解释中可能需要递归调用自身。
Context (Context)
包含对于解释器来说是全局的信息。
Client (InterpreterApp)
建立(或者给定)一个抽象语法树。抽象语法树是由NonterminalExpression 和TerminalExpression类的实例组合而成。
调用解释操作。
反馈控制环风格
概述
所谓对一个对象(或过程)进行控制,意味着设法使这个被控对象(或被控过程)的功能或特性有效的达到所期望的目标。
为了成功设计一个控制系统,必须事先知道被控对象所具有的性质和特征,同时还须了解和掌握这些性质和特征随环境等因素变化的情况。
反馈控制环风格
控制工程是一个十分强调方法论的专业领域,因此控制工程方法完全是独立于各种应用领域的。
为了将过程控制方法从单纯的控制领域中抽象出来,我们引入了动态系统的概念。
反馈控制环风格
动态系统表示信号处理和传输的一个功能单元(例如:信号可以是能量、材料、信息、资金及其他形式),其中系统的起因和由此引起的时间上的效果分别作为系统的输入量和输出量来考虑。
如此定义的系统具有共同的特征,即在其中一定存在有目标的作用、信息处理、闭环和开环控制过程,正如N.Wiener所提出的,以上概念可以用控制论这个更高级的概念来总结。
控制论也可以应用于软件体系结构的创建。
反馈控制环风格描述手段
根据上述的动态系统的定义,在系统中必然存在信号的处理和传输。这时系统也可描述为传输环节或传输系统。传输环节具有唯一的作用方向,这由输入、输出信号的箭头方向给出。
单变量系统如下图所示:
反馈控制环风格描述手段
多变量系统如下图所示:
反馈控制环风格描述手段
除了用方框图来表达动态系统以外,还可以用信号流图,如下图所示:
反馈控制环风格开环与闭环控制
一般的动态系统描述框图可以分为开环控制和闭环控制系统,但在实际应用中这两种不同的动态系统往往很容易混淆在一起,对它们之间的区别强调的不够。
现在通过一个市内暖气系统来指出这两者之间的不同和相同之处。
反馈控制环风格开环与闭环控制
开环控制图如下图所示:
反馈控制环风格开环与闭环控制
闭环控制图如下图所示:
反馈控制环风格开环与闭环控制
开环控制和闭环控制的差别:
闭环控制:
表示一个闭合的作用过程,(控制回环);
根据闭环作用原理可增加抗干扰性(负反馈);
可能不稳定,也即被控量不再衰减,而是增长到无穷大(理论上)。
反馈控制环风格开环与闭环控制
开环控制和闭环控制的差别(续):
开环控制
表示一个开放的作用过程(控制序列);
只能对抗指定由其处理的干扰,对于其他一些干扰因素无法消除;
只要被控制对象自己保持稳定,整个开环控制系统也就保持稳定。
反馈控制环风格基本结构
以闭环控制系统为例分析过程控制环的基本结构;
一个自动控制系统包括如下4个主要组成部分:被控对象、测量环节、调节器和执行环节,如下图所示:
反馈控制环风格-自适应
自适应反馈控制环需要包括以下3方面的工作:
辨识被控对象的特征;
在辨识的基础上作出控制决策;
在决策的基础上实施修正动作.
按照构成自适应控制环的目的的不同可将其分为两种类型:
参数自适应控制环;
性能自适应控制环;
反馈控制环风格-自适应反馈控制环
参数自适应控制环
参数自适应控制环如下图所示:
反馈控制环风格-自适应反馈控制环
性能自适应控制环
性能自适应控制环如下图所示:
反馈控制环风格-自适应反馈控制环
在性能自适应控制环中,最典型的代表就是所谓模型参考自适应控制系统。
模型参考自适应控制系统按照其控制方式又可分为两种
A.直接法
B.间接法
反馈控制环风格-自适应反馈控制环
直接法模型如下图所示:
间接法模型如下图所示:
反馈控制环风格实例
钢铁烧结工艺控制体系结构
反馈控制环风格实例
钢铁烧结工艺控制体系结构
反馈控制环风格实例
钢铁烧结工艺控制体系结构
反馈控制环风格实例
钢铁烧结工艺控制体系结构
反馈控制环风格实例
钢铁烧结工艺控制体系结构
反馈控制环风格实例
钢铁烧结工艺控制体系结构
反馈控制环风格实例
钢铁烧结工艺控制体系结构
七种构建模式的比较
软件体系结构的七种构建模式各有自己的特点、局限、应用范围和优缺点,比较各种构建模式的不同将有助于在实际的项目开发过程中选择适合项目的构建模式。七种构建模式的比较见下表所示:
七种构建模式的比较
七种构建模式的比较
异构风格的集成
概述
各种系统构建模式之间不仅有联系,而且在很多情况下它们往往是配合使用的。即面对一个实际系统,很难判断它究竟是A型,还是B型,亦或者是C型,单纯的把它归到任何一型都是很勉强的。这样的系统可以称为复合型系统,这样的系统构建模式就称为异构风格的集成。
异构风格的集成
作为一个整体项目,可以将足球队类比为一个软件系统,球队的比赛过程类比为软件系统的运行过程,而球队完成教练(无论胜负)的战术意图类比为系统实现了自身功能。
整个球队的运作可以用分层风格(Layered Pattern),面向对象风格(Object Oriented)和事件驱动(Event Driven)混合表示。
异构风格的集成
在通用足球战术体系模型中:
分层风格是对整个球队基本阵型的模拟;
面向对象风格是对球队中的具体队员的模拟;
事件驱动风格对应于比赛过程中队员之间的相互通信方式。下面会详细解释这几种模式在通用足球战术体系中的作用。
异构风格的集成
通用足球战术体系中的通信关系
在通用足球战术体系中各层之间存在耦合,甚至在某些情况下某个层次中的对象还会根据系统的状态进行移动,这也是强调使用移动智能代理的根本原因。因为球员具有智能,会根据整个战局的变化自动应变,为了尽可能的模拟这种自适应性,必须使用移动智能代理.
通用足球战术体系中各个移动智能代理之间的相互通信方式和可能存在的层次跃迁,这也是整个体系结构中组成元素的基本运动方式。
异构风格的集成
通用足球战术体系的运作方式
整个系统预先定义好很多事件,它们都是和足球比赛中特定的情况或教练战术意图相联系的;
不同层次中移动智能代理在“战术事件”的驱动之下而移动。
战术事件的触发驱动事件处理函数的调用,函数的调用导致操作的执行和新事件的触发。如此环环相扣,构成了一个相互交织的事件网络,从而驱动整个系统的不断运行。
异构风格的集成
应用方法
在本模型的基础之上,实际系统设计者应该确定移动智能代理的实现和分布(指定基本阵型),定义必须的战术事件,给每个移动智能代理定义相应的事件处理函数(指定战术打法,是本模型的核心问题)。
在完成上述基本步骤后,模拟系统运行,修正最初的设计(甚至可以为每个移动智能代理设计多个事件处理函数,在不同情况下调用不同的函数,实现战术打法的变化),最终构成一个实际可运行的足球战术模拟系统。
小 结
在管道-过滤器风格下,每个功能模块都有一组输入和输出。功能模块从输入集合读入数据流,并在输出集合产生输出数据流,即功能模块对输入数据流进行增量计算得到输出数据流。在管道-过滤器风格下,功能模块称作过滤器(filters);功能模块间的连接可以看作输入、输出数据流之间的通路,所以称作管道(pipes)。
小 结
面向对象风格集数据抽象、抽象数据类型、类继承为一体,使软件工程公认的模块化、信息隐藏、抽象、重用性等原则在面向对象风格下得以充分实现。面向对象风格设计的根本出发点是追求自然的刻划和求解现实世界重的问题,即追求问题空间和软件系统空间结构的一致性。
小 结
在基于事件驱动风格的系统设计中,系统的每个子系统在设计过程中要考虑其完整性和相对独立性,不绝对依赖于某一子系统,系统之间的协调和管理都是通过消息传递和收集来进行的。基于事件驱动风格的系统必须把系统内的各个子系统看作是个性和共性的对立统一体,即考虑到每个子系统的“社会性”,也考虑到它的“独立性”。
小 结
一个分层系统采用层次化的组织方式构建,系统中的每一层都要承担两个角色。
首先,它要为结构中的上层提供服务;
其次,它要作为结构中下面层次的客户,调用下层提供的功能函数。
分层系统中的各个组件在不同层次上形成了不同功能级别的虚拟机(Virtual Machine),各虚拟机之间通过系统设计时约定的协议进行通讯,而不相邻层之间的通讯受到一些限制条件的束缚。
小 结
采用数据共享风格构建的系统中通常有两个截然不同的功能构件:
一个是中央数据单元构件,代表系统当前的各种状态;
另一个是一些相对独立的组件的集合,这些组件对中央数据单元进行操作。
中央数据单元(也就是知识库)和外部组件集合之间的信息交互就成为基于数据共享风格的系统中至关重要的问题,随着系统承担的功能不同,这种信息交互的方式也存在很大差异。
小 结
基于解释器风格的系统核心在于虚拟机。
一个基于解释器风格的系统通常包括正在被解释执行的伪码和解释引擎,其中伪码由需要被解释执行的源代码和解释引擎分析所得的中间代码组成;而解释引擎包括语法解释器和解释器当前的运行状态。
一个解释器风格中就有4个基本的构成部分:一个完成解释工作的解释引擎、一个包含伪码的数据存储区、一个记录解释引擎当前工作状态的数据结构和一个记录源代码被解释执行的进度的数据结构。
小 结
为了成功设计一个控制系统,必须事先知道被控对象所具有的性质和特征,同时还须了解和掌握这些性质和特征随环境等因素变化的情况。
控制系统可以在其运行的过程中,通过自身不断的测量被控对象的特性,从而“认识”或“掌握”被控对象,并根据所掌握的被控对象当前的特征信息,控制系统做出控制决策,使系统的性能按所规定的标准达到最优或者接近最优。
小 结
面对一个实际系统,很难判断它究竟是A型,还是B型,亦或者是C型,单纯的把它归到任何一型都是很勉强的。这样的系统可以称为复合型系统,这样的系统构建模式就称为异构风格的集成。
