CentOS7环境下ceph J版安装部署
一、环境准备
安装环境为VMWare Workstation虚拟机
1.准备5台虚拟机
ceph-deploy:作为管理节点,后续的ceph-deploy工具都在该节点上进行操作。
ceph-node1、ceph-node2 、ceph-node3 :即做mon节点又做osd节点,都有3块磁盘,前2块磁盘部署2个osd,第3块磁盘建立2个相等大小分区作为2个osd盘的日志分区。这样,集群共有6个osd进程,3个monitor进程。
ceph-client :作为客户端,用来挂载ceph集群提供的存储进行测试。
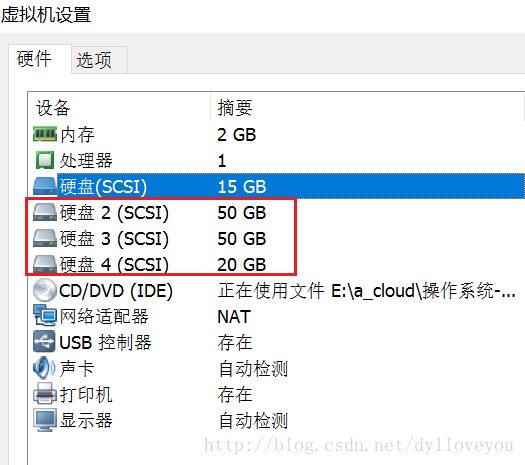
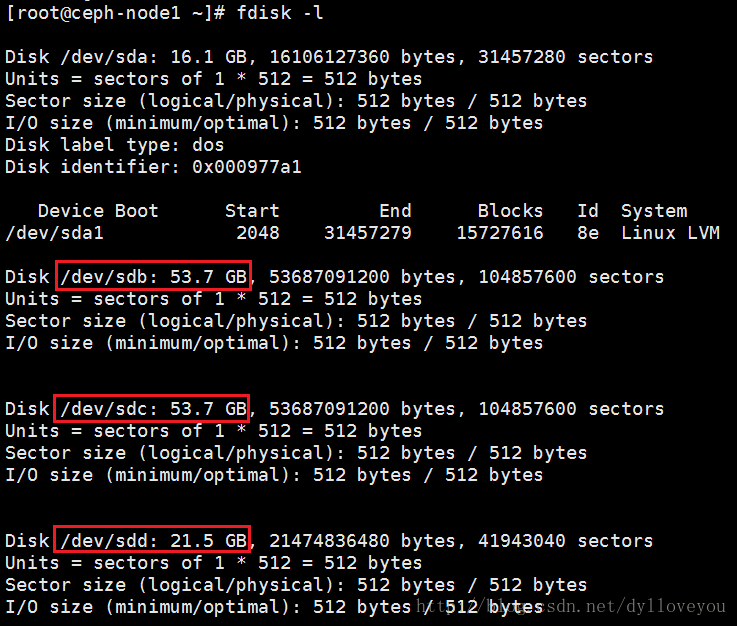
2.磁盘规划
ceph-node1、ceph-node2 、ceph-node3 上面各有3块盘,/dev/sdb,/dev/sdc为数据盘,/dev/sdd为日志盘
3.修改各个节点/etc/hosts文件
192.168.128.110 ceph-deploy
192.168.128.111 ceph-node1
192.168.128.112 ceph-node2
192.168.128.113 ceph-node3
192.168.128.114 ceph-client
4.关闭firewalld
systemctl stop firewalld
systemctl disable firewalld
5.关闭Selinux
vi /etc/sysconfig/selinux
SELINUX=disabled
6.安装ntp
yum install ntp ntpdate ntp-doc
systemctl enable ntpd
systemctl start ntpd
将系统时区改为上海时间
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
查看时间是否准确
date
/etc/ntp.conf # deploy节点
…
restrict 192.168.128.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0 iburst
fudge 127.127.1.0 stratum 10
…
/etc/ntp.conf # ceph其他节点
…
server ceph-deploy iburst
…
systemctl restart ntpd
其他节点查看
watch ntpq -p

二、配置ceph源,安装依赖包
在每个节点都添加ceph源,修改epel源,使用阿里云源
cd /etc/yum.repos.d
vi ceph.repo
[ceph]
name=Ceph packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/
enabled=1
gpgcheck=1
priority=2
type=rpm-md
gpgkey=http://mirrors.aliyun.com/ceph/keys/release.asc
[ceph-noarch]
baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/noarch/
enabled=1
gpgcheck=1
priority=2
type=rpm-md
gpgkey=http://mirrors.aliyun.com/ceph/keys/release.ascvi epel.repo
[epel]
name=Extra Packages for Enterprise Linux 7 - $basearch
baseurl=http://mirrors.aliyun.com/epel/7/$basearch
http://mirrors.aliyuncs.com/epel/7/$basearch
#mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-7&arch=$basearch
failovermethod=priority
enabled=1
gpgcheck=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7下面这些包需要在每个ceph节点都安装
yum install -y yum-utils snappy leveldb gdisk python-argparse gperftools-libs三、安装ceph-deploy工具
ceph-deploy是ceph官方提供的部署工具,它通过ssh远程登录其它各个节点上执行命令完成部署过程,需要安装在ceph-deploy节点
yum install ceph-deploy我们把ceph-deploy节点上的/data/ceph/deploy目录作为ceph-deploy部署目录,其部署过程中生成的配置文件,key密钥,日志等都位于此目录下,因此下面部署应当始终在此目录下进行
mkdir -p /data/ceph/deployceph-deploy工具默认使用root用户SSH到各Ceph节点执行命令。为了方便,可以配置ceph-deploy免密码登陆各个节点。如果ceph-deploy以某个普通用户登陆,那么这个用户必须有无密码使用sudo的权限
ssh-keygen
ssh-copy-id ceph-node1
ssh-copy-id ceph-node2
ssh-copy-id ceph-node3
ssh-copy-id ceph-client
四、安装ceph集群
1.ceph软件包安装
首先安装ceph软件包到三个节点上。上面我们已经配置好ceph源,因此这里使用--no-adjust-repos参数忽略设置ceph源
cd /data/ceph/deploy
ceph-deploy install --no-adjust-repos ceph-node1 ceph-node2 ceph-node32.创建ceph集群,部署新的mon节点
ceph-deploy new ceph-node1 ceph-node2 ceph-node3上步会创建一个ceph.conf配置文件和一个监视器密钥环到各个节点的/etc/ceph/目录,ceph.conf中会有fsid,mon_initial_members,mon_host三个参数
默认ceph使用集群名ceph,可以使用下面命令创建一个指定的ceph集群名称
ceph-deploy --cluster {cluster-name} new {host [host], ...}Ceph Monitors之间默认使用6789端口通信, OSD之间默认用6800:7300 范围内的端口通信,多个集群应当保证端口不冲突
3.修改配置文件
修改ceph-deploy目录/data/ceph/deploy下的ceph.conf
vi /data/ceph/deploy/ceph.conf 添加如下参数
osd_journal_size = 10000 #10G
osd_pool_default_size = 2
osd_pool_default_pg_num = 512
osd_pool_default_pgp_num = 512
rbd_default_features = 34.添加mons
我们这里创建三个Monitor
ceph-deploy mon create ceph-node1 ceph-node2 ceph-node3上面命令效果如下
a.write cluster configuration to /etc/ceph/{cluster}.conf
b.生成/var/lib/ceph/mon/ceph-node1/keyring
c.systemctl enable ceph-mon@ceph-node1
d.systemctl start ceph-mon@ceph-node1
在一主机上新增监视器时,如果它不是由ceph-deploy new命令所定义的,那就必须把public network加入 ceph.conf配置文件
5. key管理
为节点准备认证key
ceph-deploy gatherkeys ceph-node1 ceph-node2 ceph-node3若有需要,可以删除管理主机上、本地目录中的密钥。可用下列命令:
ceph-deploy forgetkeys6. osd创建
创建集群,安装ceph包,收集密钥之后,就可以创建osd了
准备osd
ceph-deploy osd prepare ceph-node1:sdb:/dev/sdd ceph-node1:sdc:/dev/sdd ceph-node2:sdb:/dev/sdd ceph-node2:sdc:/dev/sdd ceph-node3:sdb:/dev/sdd ceph-node3:sdc:/dev/sdd可以prepare多个osd
ceph-node1:sdb:/dev/sdd 意思是在node1上创建一个osd,使用磁盘sdb作为数据盘,osd journal分区从sdd磁盘上划分
每个节点上2个osd磁盘sd{b,c},使用同一个日志盘/dev/sdd,prepare过程中ceph会自动在/dev/sdd上创建2个日志分区供2个osd使用,日志分区的大小由上步骤osd_journal_size = 10000(10G)指定,你应当修改这个值
prepare 命令只准备 OSD。在大多数操作系统中,硬盘分区创建后,不用 activate 命令也会自动执行 activate 阶段(通过 Ceph 的 udev 规则)
激活osd
ceph-deploy osd activate ceph-node1:sdb1:/dev/sdd1 ceph-node1:sdc1:/dev/sdd2 ceph-node2:sdb1:/dev/sdd1 ceph-node2:sdc1:/dev/sdd2 ceph-node3:sdb1:/dev/sdd1 ceph-node3:sdc1:/dev/sdd2sdd1,sdd2 为ceph自动创建的2个日志分区
activate 命令会让 OSD 进入 up 且 in 状态,此命令所用路径和 prepare 相同。在一个节点运行多个OSD 守护进程、且多个 OSD 守护进程共享一个日志分区时,你应该考虑整个节点的最小 CRUSH 故障域,因为如果这个 SSD 坏了,所有用其做日志的 OSD 守护进程也会失效
7.验证安装成功
在mon节点执行 ceph -s
[root@ceph-node1 ~]# ceph -s
cluster 2ba8f88a-1513-445b-93d0-4ec7717c6777
health HEALTH_WARN
clock skew detected on mon.ceph-node2, mon.ceph-node3
too few PGs per OSD (21 < min 30)
Monitor clock skew detected
monmap e1: 3 mons at {ceph-node1=192.168.128.111:6789/0,ceph-node2=192.168.128.112:6789/0,ceph-node3=192.168.128.113:6789/0}
election epoch 6, quorum 0,1,2 ceph-node1,ceph-node2,ceph-node3
osdmap e30: 6 osds: 6 up, 6 in
flags sortbitwise,require_jewel_osds
pgmap v63: 64 pgs, 1 pools, 0 bytes data, 0 objects
201 MB used, 299 GB / 299 GB avail
64 active+clean显示 HEALTH_WARN too few PGs per OSD (21 < min 30)
通过下面的命令可以看到默认创建一个pool rbd,pg_num 为 64
[root@ceph-node1 ~]# ceph osd pool ls detail
pool 0 'rbd' replicated size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 1 flags hashpspool stripe_width 0再创建几个pool,为后面对接OpenStack做准备,pg数量就能上来了
ceph osd pool create cinder-volumes 128
ceph osd pool set cinder-volumes size 2
ceph osd pool create nova-vms 128
ceph osd pool set nova-vms size 2
ceph osd pool create glance-images 64
ceph osd pool set glance-images size 2
ceph osd pool create cinder-backups 64
ceph osd pool set cinder-backups size 2又显示 HEALTH_WARN Monitor clock skew detected
[root@ceph-node1 ~]# ceph -s
cluster 2ba8f88a-1513-445b-93d0-4ec7717c6777
health HEALTH_WARN
clock skew detected on mon.ceph-node2, mon.ceph-node3
Monitor clock skew detected
monmap e1: 3 mons at {ceph-node1=192.168.128.111:6789/0,ceph-node2=192.168.128.112:6789/0,ceph-node3=192.168.128.113:6789/0}
election epoch 6, quorum 0,1,2 ceph-node1,ceph-node2,ceph-node3
osdmap e42: 6 osds: 6 up, 6 in
flags sortbitwise,require_jewel_osds
pgmap v123: 448 pgs, 5 pools, 0 bytes data, 0 objects
209 MB used, 299 GB / 299 GB avail
448 active+clean时间同步有问题,经检查 ceph-node1节点的ntp服务没起来
[root@ceph-node1 ~]# systemctl status ntpd
● ntpd.service - Network Time Service
Loaded: loaded (/usr/lib/systemd/system/ntpd.service; disabled; vendor preset: disabled)
Active: inactive (dead)
[root@ceph-node1 ~]# systemctl start ntpd再次查看集群正常了
[root@ceph-node1 ~]# ceph -s
cluster 2ba8f88a-1513-445b-93d0-4ec7717c6777
health HEALTH_OK
monmap e1: 3 mons at {ceph-node1=192.168.128.111:6789/0,ceph-node2=192.168.128.112:6789/0,ceph-node3=192.168.128.113:6789/0}
election epoch 10, quorum 0,1,2 ceph-node1,ceph-node2,ceph-node3
osdmap e42: 6 osds: 6 up, 6 in
flags sortbitwise,require_jewel_osds
pgmap v123: 448 pgs, 5 pools, 0 bytes data, 0 objects
209 MB used, 299 GB / 299 GB avail
448 active+clean五、Ceph client测试
1.准备client节点
通过ceph-deploy节点执行命令:
ceph-deploy install --no-adjust-repos ceph-client
ceph-deploy admin ceph-client2.创建一个1G大小的块设备
rbd create --pool rbd --size 1024 test_image查看创建的块设备
rbd list
rbd info test_image3.将ceph提供的块设备映射到ceph-client
rbd map --pool rbd test_image4.查看系统中已经映射的块设备
rbd showmapped
[root@ceph-client ~]# rbd showmapped
id pool image snap device
0 rbd test_image - /dev/rbd0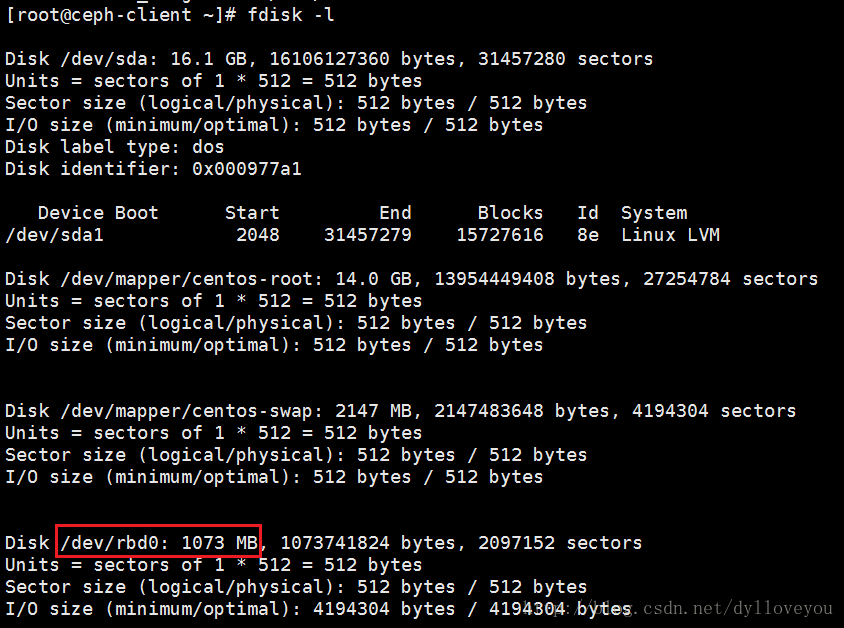
5.取消块设备映射
rbd unmap /dev/rbd0
此次安装配置参考了网上的多个文档,在此表示非常感谢!