内点法介绍(Interior Point Method)
在面对无约束的优化命题时,我们可以采用牛顿法等方法来求解。而面对有约束的命题时,我们往往需要更高级的算法。单纯形法(Simplex Method)可以用来求解带约束的线性规划命题(LP),与之类似的有效集法(Active Set Method)可以用来求解带约束的二次规划(QP),而内点法(Interior Point Method)则是另一种用于求解带约束的优化命题的方法。而且无论是面对LP还是QP,内点法都显示出了相当的极好的性能,例如多项式的算法复杂度。本文主要介绍两种内点法,障碍函数法(Barrier Method)和原始对偶法(Primal-Dual Method)。其中障碍函数法的内容主要来源于Stephen Boyd与Lieven Vandenberghe的Convex Optimization一书,原始对偶法的内容主要来源于Jorge Nocedal和Stephen J. Wright的Numerical Optimization一书(第二版)。
为了便于与原书对照理解,后面的命题与公式分别采用了对应书中的记法,并且两者方法针对的是不同的命题。两种方法中的同一变量可能在不同的方法中有不同的意义,如 μ 。在介绍玩两种方法后会有一些比较。
-
- 障碍函数法Barrier Method
- Central Path
- 举例
- 原始对偶内点法Primal Dual Interior Point Method
- Central Path
- 举例
- 几个问题
- 障碍函数法Barrier Method
障碍函数法(Barrier Method)
对于障碍函数法,我们考虑一个一般性的优化命题:
我们可以看出,KKT条件中的不等式使得对KKT系统的求解难以为继,因此Barrier Method的思想就是通过在原始的目标函数中添加一个障碍函数(也可以理解成惩罚函数)来代替约束条件中的不等式约束。也就是说,把命题(1)变成下面的样子:

但是很可惜,红色虚线的这个函数在某些点上是不可导的,因此并不适用,那么下面的想法就是用类似的函数,比如上图中的几条蓝色曲线表示的函数来近似这个函数。这样一个近似的函数的表达式如下:
这里我们定义如下的对数障碍(logarithmic barrier):
Central Path
针对(6)中不同的 t>0 值,我们定义 x∗(t) 为相应优化命题的解。那么,central path 就是指所有点 x∗(t),t>0 的集合,其中的点被称为 central points。central path 上的点满足如下的充分必要条件,首先 x∗(t) 都是严格可行的,即:
我们可以从对偶变量的角度进一步研究上式,给等号两边都乘上 1t ,我们有:
那么此时,对偶命题的目标函数值为:
如果我们记原命题(1)的目标函数的最小值为 p∗ ,那么由优化命题的对偶理论可知(可以参考另一篇博文——优化命题的对偶性(Duality))
因此这里可以给出一个 Barried Method 算法的框架(来自Convex Optimization, Algorithm 11.1):
Barrier Method
given strictly feasible x,t:=t(0)>0,μ>1,tolerance ϵ>0
repeat
- Centering step. Compute x∗(t) by minimizing tf0+ϕ , subject to Ax=b , starting at x .
- Update. x:=x∗(t) .
- Stopping criterion. quit if m/t<ϵ .
- Increase t . t=μt
举例
这里用一个例子进行一些补充说明。考察一个简单的线性规划:
下面两图是第一次迭代, t=4 时的 tf0(x)+ϕ(x) 函数图象和平面的等高图,同时第二张图上还标出了迭代点的轨迹。


下面是 t=8 时的 tf0(x)+ϕ(x) 函数图象和平面的等高图,同时第二张图上还标出了迭代点的轨迹。


对于本例,central path 就是 x1=x2 这条直线。从迭代点的轨迹可以看出,在第一次迭代后,迭代点一直在central path上移动。
其实对于Barrier Method,我自己之前有个疑问就是,既然我们知道在 x∗(t) 处的目标函数值与最优解的差肯定小于 mt ,那为什么不直接给一个较大的 t 值通过较少的几次迭代就能算出最有解了呢。真对这一问题,原因可能是这样的,Barrier Method的计算量是由内外两层迭代组成的,外层对 t 进行更新: t=μt ,内层用牛顿法求 tf0+ϕ 的解。有仿真结果表明,随着 μ 值的加大,总的计算量(牛顿迭代次数)在呈现一定阶段的下降后并没有明显下降。而对与 μ 值的选取则是一个内层迭代次数和外层迭代次数的权衡。 μ 值较大时,外层迭代次数少,内层迭代次数多; μ 值较小时情况则相反。一般来说 μ 的取值在 10到20 之间比较合适。
原始对偶内点法(Primal Dual Interior Point Method)
在 Primal Dual 的方法中,我们直接考虑一个标准的 LP 命题。
如同一般的优化算法,这里需要定义一个量来检验当前的迭代点与最优点的差距。在Barrier Method中,使用 duality gap 的上界 mt 来检验的,在 Primal Dual Method 中,我们定义一个新的 duality measure 来进行某种衡量:
要求解原始的优化命题,需要做的就是去求解 (12) 这样一个方程组,由于 F 阵第三行中 XS 一项的存在,因此这是一个非线性系统。要求解这样一个非线性系统,一种实用的方法就是牛顿法。(注意,这里说的牛顿法是一种求解非线性方程组的方法,与求解优化命题的牛顿法并不完全一样,但核心思路是一致的,都是在迭代点处进行二阶展开。)在当前点处求解一个前进方向,并通过迭代逼近非线性系统的解。
看起来这种方法似乎已经可以了,但通过这种被称为 affine scaling direction 的方向所得到的 α 往往很小。也就是说,很难在迭代中取得进展。一开始看到这个说法时,我也很难理解这句话的意思。所以在这里我们用一个图来说明,令 (9) 中的 c=(101) ,初始点为 (0.7,2) ,这里不考虑等式约束,直接采用affine scaling direction 的方向得到的迭代点的轨迹为
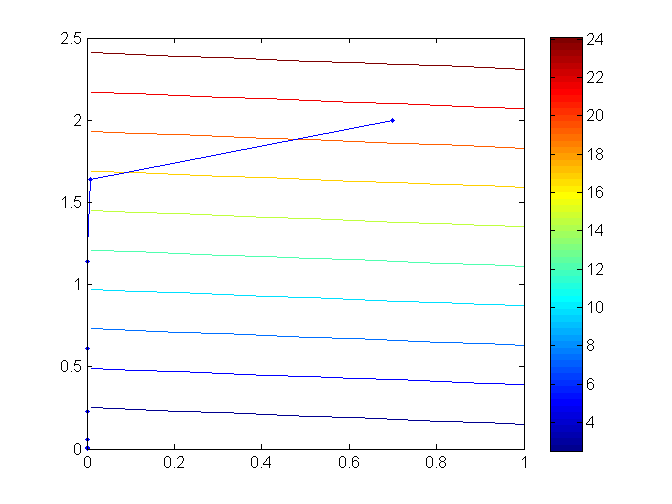
从图中可以看出,几乎在从第二次迭代开始,迭代点就一头撞上了约束。后面的迭代也只能贴着约束的边缘来走,因为要保迭代点不能违反约束,因此每次的步长 α 都只能取得很小。在这一过程中,一共进行了11次迭代才使得 duality measure μ<10−5 。
因此,实际上内点法采用的是一个不那么 aggressive 的牛顿方向,也就是控制迭代点使其徐徐想约束边界和最优点处靠近。具体的方法是,我们在用牛顿法求解非线性系统时,在每次迭代中并不要求直接实现 xisi=0 ,而是令其等于一个逐渐减少的值,具体来说就是 xisi=σμ ,其中 μ 是当前的 duality measure, σ∈[0,1] 是用于控制下降速度的下降因子。也就是说,在每次迭代中要求解的方程组应该是
Central Path
在内点法中,central path 是指满足下面一组方程式的迭代点所组成的所组成的一条弧线
也就是说,对偶内点法的基本思路就是依据 central path 计算出相应的方向,并控制步长 α 的选择使得迭代点位于 central path 的某一个邻域内。(有关central path 的邻域的内容,和具体的原始对偶内点法的算法在这里不作详细说明,有兴趣这可以参考相应书籍。)
关于步长 α 的选取,central parameter σ 的更新,以及更多的收敛性分析的内容,在这里不作展开。
举例
与上一张图对应,我们同样取 c=(101) ,初始点为 (0.7,2) ,不考虑等式约束。采用对偶内点法的迭代点的轨迹为
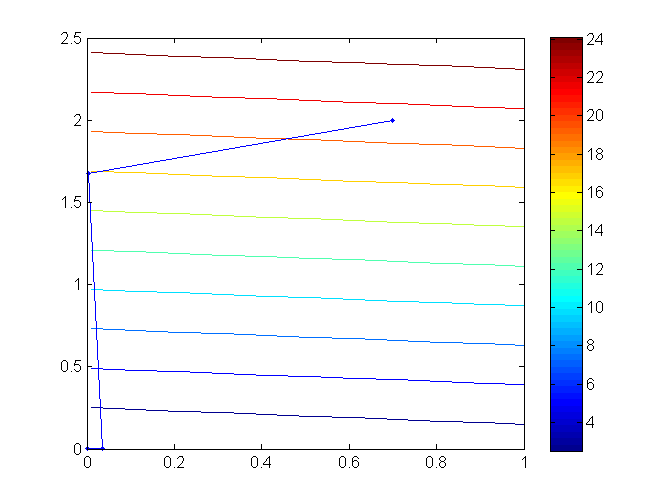
可以看出,引入 central path 后,迭代点能在贴近约束边界后再次远离约束边界(也就是靠近 central path) ,从而保证下一次迭代能取得更大的进步。在这一过程中,一共进行了6次迭代就使得 duality measure μ<10−5 。
几个问题
1 Barrier Method 中的 central path 与 Primal Dual Method 中的 central path 是不是一个东西?
是一个东西,我们可以从优化命题的 Lagrangian 函数这一角度出发分析这一点。
Barrier Method 中的优化命题的 Lagrangian 函数为:
Primal Dual Method 中优化命题的 Lagrangian 函数为:
从这里我们可以看出来,Barrier Method 中我们控制 t 使得 duality gap 为 mt ,在Primal Dual 内点法中我们控制 ∑ni=1xisi=σμ 其实是一致的。而且有
2 Central Path 有啥好处?
从上面的举例可以看出,如果没有 central path ,迭代点往往非常靠近约束边界。如果我们能够将迭代点拉回到 central path 附近,那么即使这次迭代对与目标函数下降的贡献不大,那么也可以使得在下次迭代时目标函数能够取得较大下降。此外,central path 还对算法的热启动(warm start)有影响。因为在很多场合(例如 MPC),我们需要求解一系列结构一致,参数相似的优化命题,传统的初始点给点的方法是把上一次的解作为初始点,但我们可以看出,上一次的解往往靠近约束边界而并不靠近 central path,因此这种初始点给定方法并不完善。考虑给出一个靠近 central path 点才是更好的。相关内容可以参考文献[3]。
3 两种方法有什么区别?
从第一问的分析可以看出,二者的共同点还是很明显的。文献[2]列出了一些区别,比如 Barrier Method 有内外两层迭代,而 Primal Dual Method 只有一层迭代。另外一个区别是 Barrier Method 的迭代点肯定是严格可行的,而 Primal Dual Method 的迭代点可以是不可行的。关于这一点我还没有进一步去了解。
Ref.
[1] Boyd, Stephen, and Lieven Vandenberghe. Convex optimization. Cambridge university press, 2004.
[2] Nocedal, Jorge, and Stephen J. Wright. “Numerical Optimization 2nd.” (2006).
[3] Yildirim, E. Alper, and Stephen J. Wright. “Warm-start strategies in interior-point methods for linear programming.” SIAM Journal on Optimization 12.3 (2002): 782-810.