LSM树原理介绍
LSM树原理介绍
- Log Structured Merge Trees(LSM) 原理
- 背景
- 基本算法
- 基本数据结构
- SST结构
- memtable结构
- log 文件结构
Log Structured Merge Trees(LSM) 原理
简单的说,LSM被设计来提供比传统的B+树或者ISAM更好的写操作吞吐量,通过消去随机的本地更新操作来达到这个目标。这是基于磁盘随机操作慢,顺序读写快。
LSM是当前被用在许多产品的文件结构策略:HBase, Cassandra, LevelDB, SQLite, rocksdb,mangodb.
背景
因为简单和高效,基于日志的策略在大数据之间越来越流行,同时他们也有一些缺点,从日志文件中读一些数据将会比写操作需要更多的时间,需要倒序扫描,直接找到所需的内容。
这说明日志仅仅适用于一些简单的场景:1. 数据是被整体访问,像大部分数据库的WAL(write-ahead log) 2. 知道明确的offset,比如在Kafka中。
所以,我们需要更多的日志来为更复杂的读场景(比如按key或者range)提供高效的性能,这儿有4个方法可以完成这个,它们分别是:
二分查找: 将文件数据有序保存,使用二分查找来完成特定key的查找。
哈希:用哈希将数据分割为不同的bucket
B+树:使用B+树 或者 ISAM 等方法,可以减少外部文件的读取
外部文件: 将数据保存为日志,并创建一个hash或者查找树映射相应的文件。
所有的方法都可以有效的提高了读操作的性能(最少提供了O(log(n)) ),但是,却丢失了日志文件超好的写性能。上面这些方法,都强加了总体的结构信息在数据上,数据被按照特定的方式放置,所以可以很快的找到特定的数据,但是却对写操作不友善,让写操作性能下降。
基本算法
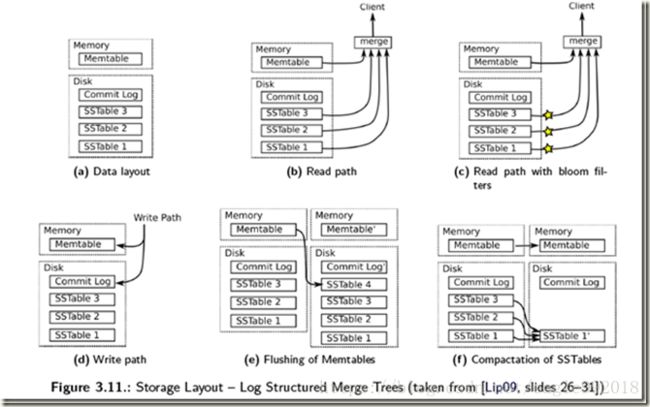
从概念上说,最基本的LSM是很简单的 。将之前使用一个大的查找结构(造成随机读写,影响写性能),变换为将写操作顺序的保存到一些相似的有序文件(也就是sstable)中。所以每个文件包含短时间内的一些改动。因为文件是有序的,所以之后查找也会很快。文件是不可修改的,他们永远不会被更新,新的更新操作只会写到新的文件中。读操作检查很有限的文件。通过周期性的合并这些文件来减少文件个数。
让我们更具体的看看,当一些更新操作到达时,他们会被写到内存缓存(也就是memtable)中,memtable使用树结构来保持key的有序,在大部分的实现中,memtable会通过写WAL的方式备份到磁盘,用来恢复数据,防止数据丢失。当memtable数据达到一定规模时会被刷新到磁盘上的一个新文件,重要的是系统只做了顺序磁盘读写,因为没有文件被编辑,新的内容或者修改只用简单的生成新的文件。
所以越多的数据存储到系统中,就会有越多的不可修改的,顺序的sstable文件被创建,它们代表了小的,按时间顺序的修改。
因为比较旧的文件不会被更新,重复的纪录只会通过创建新的纪录来覆盖,这也就产生了一些冗余的数据。
所以系统会周期的执行合并操作(compaction)。 合并操作选择一些文件,并把他们合并到一起,移除重复的更新或者删除纪录,同时也会删除上述的冗余。更重要的是,通过减少文件个数的增长,保证读操作的性能。因为sstable文件都是有序结构的,所以合并操作也是非常高效的。
当一个读操作请求时,系统首先检查内存数据(memtable),如果没有找到这个key,就会逆序的一个一个检查sstable文件,直到key被找到。因为每个sstable都是有序的,所以查找比较高效(O(logN)),但是读操作会变的越来越慢随着sstable的个数增加,因为每一个sstable都要被检查。(O(K log N), K为sstable个数, N 为sstable平均大小)。
所以,读操作比其它本地更新的结构慢,幸运的是,有一些技巧可以提高性能。最基本的的方法就是页缓存(也就是leveldb的TableCache,将sstable按照LRU缓存在内存中)在内存中,减少二分查找的消耗。LevelDB 和 BigTable 是将 block-index 保存在文件尾部,这样查找就只要一次IO操作,如果block-index在内存中。一些其它的系统则实现了更复杂的索引方法。
即使有每个文件的索引,随着文件个数增多,读操作仍然很慢。通过周期的合并文件,来保持文件的个数,因些读操作的性能在可接收的范围内。即便有了合并操作,读操作仍然会访问大量的文件,大部分的实现通过布隆过滤器来避免大量的读文件操作,布隆过滤器是一种高效的方法来判断一个sstable中是否包含一个特定的key。(如果bloom说一个key不存在,就一定不存在,而当bloom说一个文件存在是,可能是不存在的,只是通过概率来保证)
所有的写操作都被分批处理,只写到顺序块上。另外,合并操作的周期操作会对IO有影响,读操作有可能会访问大量的文件(散乱的读)。这简化了算法工作的方法,我们交换了读和写的随机IO。这种折衷很有意义,我们可以通过软件实现的技巧像布隆过滤器或者硬件(大文件cache)来优化读性能。
基本数据结构
SSTable(Sorted String Table),本身是个简单的数据结构, 就是一组key-value的表。具体实现中通常会加上索引。
memtable, 可以看作SST在内存中的体现。通常使用skiplist树。
SST结构
以ROCKSDB的SST结构为例:
[data block 1]
[data block 2]
…
[data block N]
[meta block 1: filter block] (see section: “filter” Meta Block)
[meta block 2: stats block] (see section: “properties” Meta Block)
[meta block 3: compression dictionary block] (see section: “compression dictionary” Meta Block)
[meta block 4: range deletion block] (see section: “range deletion” Meta Block)
…
[meta block K: future extended block] (we may add more meta blocks in the future)
[metaindex block]
[index block]
[Footer] (fixed size; starts at file_size - sizeof(Footer))
**注:**在index字段中,用到了 BlockHandles类型的指针,这种指针实际上包含偏移量及字段长度
字段说明:
data block 1…n: 数据段,顺序保存key-value 数据对。
meta block : 描述过滤策略,文件格式,压缩字典,待删除key等内容。
metaindex block: 保存meta块索引(key-BlockHandles指针)(key:meta-block名字,指针:各meta block的偏移及长度)
index block: 保存data block每一个数据段的入口(key-BlockHandles指针)。其中key值>=数据段最大的key, 且<下一数据段最小的key值;指针:data bock的偏移及长度。
Footer: 定长字段,包含以下内容:
metaindex_handle: char[p]; metaindex段的偏移及长度
index_handle: char[q]; index段的偏移及长度
padding: char[40-p-q]; // zeroed bytes to make fixed length
// (40==2*BlockHandle::kMaxEncodedLength)
magic: fixed64; // 0x88e241b785f4cff7 (little-endian)
memtable结构
基于skiplist树的memtable可以获取很高的读写性能。
log 文件结构
log文件按时间顺序追加数据操作。以rocksdb为例:
文件格式:
±----±------------±-±—±---------±-----±- … ----+
File | r0 | r1 |P | r2 | r3 | r4 | |
±----±------------±-±—±---------±-----±- … ----+
<— kBlockSize ------>|<-- kBlockSize ------>|
rn = 变长记录
P = 填充位(剩于的字节不足以记录下一 条记录)
记录格式:
±--------±----------±----------±-- … —+
|CRC (4B) | Size (2B) | Type (1B) | Payload |
±--------±----------±----------±-- … —+
CRC = 对payload进行32bit hash 运算得到
Size = payload 长度
Type = 记录类型
Payload = 字节流,长度按size定义。