【python数据挖掘课程】二十六.基于SnowNLP的豆瓣评论情感分析
这是《Python数据挖掘课程》系列文章,前面很多文章都讲解了分类、聚类算法,而这篇文章主要讲解如何调用SnowNLP库实现情感分析,处理的对象是豆瓣《肖申克救赎》的评论文本。文章比较基础,希望对你有所帮助,提供些思路,也是自己教学的内容。如果文章中存在错误或不足之处,还请海涵。同时,推荐大家阅读我以前的文章了解其他知识。
目录:
一.豆瓣评论数据抓取
1.审查网页元素,获取目标网站DOM树结构
2.Selenium抓取《肖申克救赎》评论信息
3.抓取前10页评论并存储至CSV文件
二.情感分析预处理及词云显示
三.SnowNLP情感分析
1.SnowNLP
2.中文分词
3.常见功能
4.情感分析
四.SnowNLP情感分析实例
PSS:最近参加CSDN2018年博客评选,希望您能投出宝贵的一票。我是59号,Eastmount,杨秀璋。投票地址:https://bss.csdn.net/m/topic/blog_star2018/index

前文参考:
【Python数据挖掘课程】一.安装Python及爬虫入门介绍
【Python数据挖掘课程】二.Kmeans聚类数据分析及Anaconda介绍
【Python数据挖掘课程】三.Kmeans聚类代码实现、作业及优化
【Python数据挖掘课程】四.决策树DTC数据分析及鸢尾数据集分析
【Python数据挖掘课程】五.线性回归知识及预测糖尿病实例
【Python数据挖掘课程】六.Numpy、Pandas和Matplotlib包基础知识
【Python数据挖掘课程】七.PCA降维操作及subplot子图绘制
【Python数据挖掘课程】八.关联规则挖掘及Apriori实现购物推荐
【Python数据挖掘课程】九.回归模型LinearRegression简单分析氧化物数据
【python数据挖掘课程】十.Pandas、Matplotlib、PCA绘图实用代码补充
【python数据挖掘课程】十一.Pandas、Matplotlib结合SQL语句可视化分析
【python数据挖掘课程】十二.Pandas、Matplotlib结合SQL语句对比图分析
【python数据挖掘课程】十三.WordCloud词云配置过程及词频分析
【python数据挖掘课程】十四.Scipy调用curve_fit实现曲线拟合
【python数据挖掘课程】十五.Matplotlib调用imshow()函数绘制热图
【python数据挖掘课程】十六.逻辑回归LogisticRegression分析鸢尾花数据
【python数据挖掘课程】十七.社交网络Networkx库分析人物关系(初识篇)
【python数据挖掘课程】十八.线性回归及多项式回归分析四个案例分享
【python数据挖掘课程】十九.鸢尾花数据集可视化、线性回归、决策树花样分析
【python数据挖掘课程】二十.KNN最近邻分类算法分析详解及平衡秤TXT数据集读取
【python数据挖掘课程】二十一.朴素贝叶斯分类器详解及中文文本舆情分析
【python数据挖掘课程】二十二.Basemap地图包安装入门及基础知识讲解
【python数据挖掘课程】二十三.时间序列金融数据预测及Pandas库详解
【python数据挖掘课程】二十四.KMeans文本聚类分析互动百科语料
【python数据挖掘课程】二十五.Matplotlib绘制带主题及聚类类标的散点图
一.豆瓣评论数据抓取
本文首先需要抓取豆瓣《肖申克救赎》电影的评论信息,采用Selenium爬虫实现。这里不再详细讲解爬虫的知识,仅简单介绍。
1.审查网页元素,获取目标网站DOM树结构
目标网址为:https://movie.douban.com/subject/1292052/comments?start=0&limit=0&sort=new_score&status=P
如下图所示:
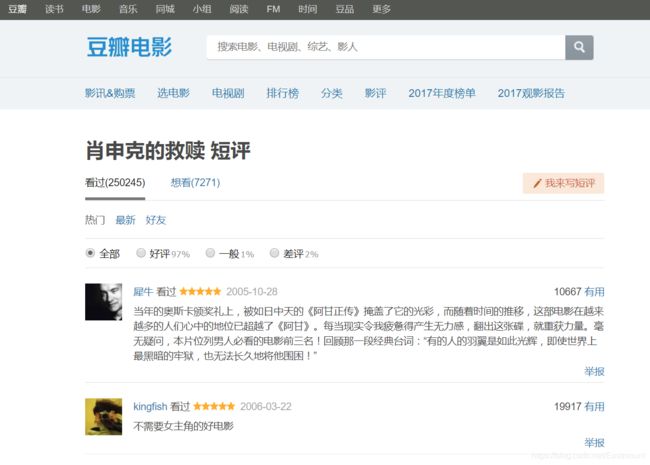
接着通过浏览器定位节点找到需要抓取内容的位置。

每一个评论都位于 < div class=“comment-item” > 中,定位内容包括:
(1) 用户名及其超链接定位class为“avatar”节点下的超链接;
(2) 评论人数位于span标签class为“comment-vote”中的第一个span;
(3) 用户评分位于span标签class为“comment-info”中第二个span;
(4) 短评论位于span标签class为“short”。
<div class="comment-item" data-cid="477351">
<div class="avatar">
<a title="犀牛" href="https://www.douban.com/people/whiterhinoceros/">
...
a>
div>
<div class="comment">
<span class="comment-vote">
<span class="votes">10667span>
...
span>
<span class="comment-info">
...
<span class="allstar50 rating" title="力荐">span>
<span class="comment-time " title="2005-10-28 00:28:07">
2005-10-28
span>
span>
h3>
<p class="">
<span class="short">当年的奥斯卡颁奖礼上...span>
p>
div>
div>
2.Selenium抓取《肖申克救赎》评论信息
Python代码如下所示,抓取了第一页的评论信息,这段代码重点是Selenium的定位方法,而下一部分代码重点是将前10页评论抓取并存储至CSV文件中。
# coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
import time
import re
import os
import csv
#打开Firefox浏览器
driver = webdriver.Firefox()
i = 0
while i<1:
num = i*20
url = "https://movie.douban.com/subject/1292052/comments?start=" + str(num) +"&limit=20&sort=new_score&status=P"
print url
driver.get(url)
#用户姓名 超链接
elem1 = driver.find_elements_by_xpath("//div[@class='avatar']/a")
for n in elem1:
print n.get_attribute("title"),
print n.get_attribute("href")
#用户评分
elem2 = driver.find_elements_by_xpath("//span[@class='comment-info']/span[2]")
for n in elem2:
print n.get_attribute("class"),
print n.get_attribute("title")
#有用数
elem3 = driver.find_elements_by_xpath("//span[@class='comment-vote']/span[1]")
for n in elem3:
print n.text
#日期
elem4 = driver.find_elements_by_xpath("//span[@class='comment-time ']")
for n in elem4:
print n.text
#评论
elem5 = driver.find_elements_by_xpath("//span[@class='short']")
for n in elem5:
print n.text
i = i + 1
输出结果如下所示:
>>>
犀牛 https://www.douban.com/people/whiterhinoceros/
kingfish https://www.douban.com/people/kingfish/
Eve|Classified https://www.douban.com/people/eve42/
...
allstar50 rating 力荐
allstar40 rating 推荐
allstar30 rating 还行
...
10667
19919
4842
...
2005-10-28
2006-03-22
2008-05-09
...
当年的奥斯卡颁奖礼上,被如日中天的《阿甘正传》...
不需要女主角的好电影
有种鸟是关不住的.
...
>>>
3.抓取前10页评论并存储至CSV文件
完整代码如下所示:
# coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
import time
import re
import os
import csv
import codecs
#写入文件
c = open("test-douban.csv", "wb") #写文件
c.write(codecs.BOM_UTF8) #防止乱码
writer = csv.writer(c) #写入对象
writer.writerow(['序号','用户名','链接','评分','评分标题','有用数','日期','评论'])
#打开Firefox浏览器 设定等待加载时间 访问URL
driver = webdriver.Firefox()
i = 0
while i<1:
num = i*20
url = "https://movie.douban.com/subject/1292052/comments?start=" + str(num) +"&limit=20&sort=new_score&status=P"
print url
driver.get(url)
#用户姓名 超链接
elem1 = driver.find_elements_by_xpath("//div[@class='avatar']/a")
#用户评分
elem2 = driver.find_elements_by_xpath("//span[@class='comment-info']/span[2]")
#有用数
elem3 = driver.find_elements_by_xpath("//span[@class='comment-vote']/span[1]")
#日期
elem4 = driver.find_elements_by_xpath("//span[@class='comment-time ']")
#评论
elem5 = driver.find_elements_by_xpath("//span[@class='short']")
#循环写入20行评价
tlist = []
k = 0
while k<20:
#序号
num = i*20+k+1
print num
#用户姓名
name = elem1[k].get_attribute("title").encode('utf-8')
print name
#超链接
href = elem1[k].get_attribute("href").encode('utf-8')
print href
#用户评分及内容
score = elem2[k].get_attribute("class").encode('utf-8')
print score
content = elem2[k].get_attribute("title").encode('utf-8')
print content
#有用数
useful = elem3[k].text.encode('utf-8')
print useful
#日期
date = elem4[k].text.encode('utf-8')
#评论
shortcon = elem5[k].text.encode('utf-8')
print shortcon
#写入文件
templist = []
templist.append(num)
templist.append(name)
templist.append(href)
templist.append(score)
templist.append(content)
templist.append(useful)
templist.append(date)
templist.append(shortcon)
writer.writerow(templist)
k = k + 1
i = i + 1
c.close()
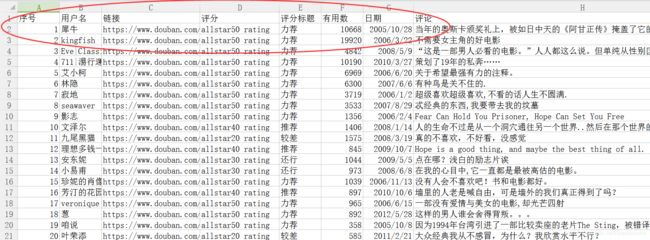
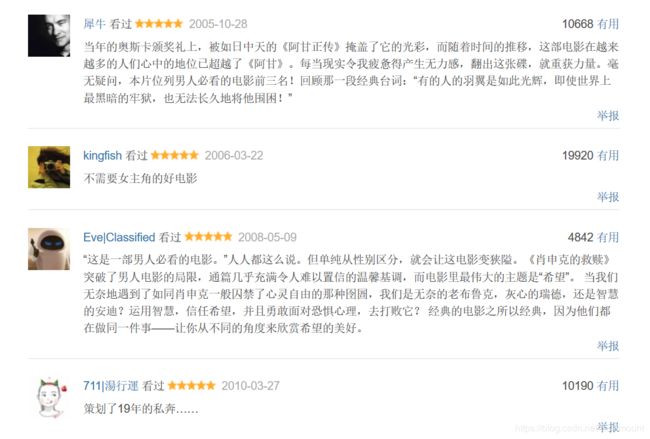
运行结果如下图所示:
二.情感分析预处理及词云显示
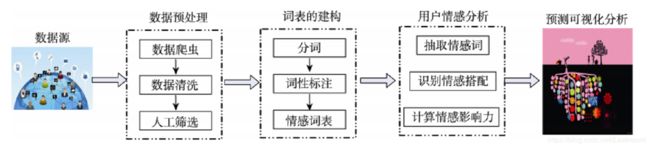
情感分析的基本流程如下图所示,通常包括:
1.自定义爬虫抓取文本信息;
2.使用Jieba工具进行中文分词、词性标注;
3.定义情感词典提取每行文本的情感词;
4.通过情感词构建情感矩阵,并计算情感分数;
5.结果评估,包括将情感分数置于0.5到-0.5之间,并可视化显示。

本文将抓取的200条《肖申克救赎》评论信息复制至TXT文件中 ,每一行为一条评论,再对其进行中文分词处理。注意,这里仅仅获取序号1-200的情感分数,而其他情感分析可以进行时间对比、主题对比等,这里作者也爬取了完整信息,而不仅仅是评论,就为了方便读者实验。其方法和此篇文章类似,希望读者学会举一反三。
data.txt

下面这段代码主要讲解Python调用Jieba工具进行分词,然后通过WordCloud库实现词云显示,关键词出现越多显示越大,比如“希望”、“自由”、“电影”等。
# -*- coding: utf-8 -*-
import jieba
import sys
import matplotlib.pyplot as plt
from wordcloud import WordCloud
#打开本体TXT文件
text = open('data.txt').read()
print type(text)
#结巴分词 cut_all=True 设置为精准模式
wordlist = jieba.cut(text, cut_all = False)
#使用空格连接 进行中文分词
wl_space_split = " ".join(wordlist)
print wl_space_split
#对分词后的文本生成词云
my_wordcloud = WordCloud().generate(wl_space_split)
#显示词云图
plt.imshow(my_wordcloud)
#是否显示x轴、y轴下标
plt.axis("off")
plt.show()

分词过程如下图所示,通过空格连接。

三.SnowNLP情感分析
1.SnowNLP
SnowNLP是一个常用的Python文本分析库,是受到TextBlob启发而发明的。由于当前自然语言处理库基本都是针对英文的,而中文没有空格分割特征词,Python做中文文本挖掘较难,后续开发了一些针对中文处理的库,例如SnowNLP、Jieba、BosonNLP等。注意SnowNLP处理的是unicode编码,所以使用时请自行decode成unicode。
Snownlp主要功能包括:
- 中文分词(算法是Character-Based Generative Model)
- 词性标注(原理是TnT、3-gram 隐马)
- 情感分析
- 文本分类(原理是朴素贝叶斯)
- 转换拼音、繁体转简体
- 提取文本关键词(原理是TextRank)
- 提取摘要(原理是TextRank)、分割句子
- 文本相似(原理是BM25)
推荐官网给大家学习。
安装和其他库一样,使用pip安装即可。
pip install snownlp
2.中文分词
下面是最简单的实例,使用SnowNLP进行中文分词,同时比较了SnowNLP和Jieba库的分词效果。
# -*- coding: utf-8 -*-
from snownlp import SnowNLP
s1 = SnowNLP(u"这本书质量真不太好!")
print("SnowNLP:")
print(" ".join(s1.words))
import jieba
s2 = jieba.cut(u"这本书质量真不太好!", cut_all=False)
print("jieba:")
print(" ".join(s2))
输出结果如下所示:

总体感觉是SnowNLP分词速度比较慢,准确度较低,比如“不太好”这个词组,但也不影响我们后续的情感分析。
3.常见功能
代码如下:
# -*- coding: utf-8 -*-
from snownlp import SnowNLP
s = SnowNLP(u"这本书质量真不太好!")
print(u"\n中文分词:")
print( " ".join(s.words))
print(u"\n词性标注:")
print(s.tags)
for k in s.tags:
print(k)
print(u"\n情感分数:")
print(s.sentiments)
print(u"\n转换拼音:")
print(s.pinyin)
print(u"\n输出前4个关键词:")
print(s.keywords(4))
for k in s.keywords(4):
print(k)
print(u"\n输出关键句子:")
print(s.summary(1))
for k in s.summary(1):
print(k)
print(u"\n输出tf和idf:")
print(s.tf)
print(s.idf)
n = SnowNLP(u'「繁體字」「繁體中文」的叫法在臺灣亦很常見。')
print(u"\n繁简体转换:")
print(n.han)
s.words 输出分词后的结果,词性标注主要通过 s.tags,s.sentiments 计算情感分数,s.pinyin 转换为拼音,s.keywords(4) 提取4个关键词,s.summary(1) 输出一个关键句子,s.tf 计算TF值(频率),s.idf 计算IDF值(倒文档)。
输出结果如下所示:
>>>
中文分词:
这 本书 质量 真 不 太 好 !
词性标注:
[(u'\u8fd9', u'r'), (u'\u672c\u4e66', u'r'), (u'\u8d28\u91cf', u'n'),
(u'\u771f', u'd'), (u'\u4e0d', u'd'), (u'\u592a', u'd'),
(u'\u597d', u'a'), (u'\uff01', u'w')]
(u'\u8fd9', u'r')
(u'\u672c\u4e66', u'r')
(u'\u8d28\u91cf', u'n')
(u'\u771f', u'd')
(u'\u4e0d', u'd')
(u'\u592a', u'd')
(u'\u597d', u'a')
(u'\uff01', u'w')
情感分数:
0.420002029202
转换拼音:
[u'zhe', u'ben', u'shu', u'zhi', u'liang', u'zhen', u'bu', u'tai', u'hao', u'\uff01']
输出前4个关键词:
[u'\u592a', u'\u4e0d', u'\u8d28\u91cf', u'\u771f']
太
不
质量
真
输出关键句子:
[u'\u8fd9\u672c\u4e66\u8d28\u91cf\u771f\u4e0d\u592a\u597d']
这本书质量真不太好
输出tf和idf:
[{u'\u8fd9': 1}, {u'\u672c': 1}, {u'\u4e66': 1},
{u'\u8d28': 1}, {u'\u91cf': 1}, {u'\u771f': 1},
{u'\u4e0d': 1}, {u'\u592a': 1}, {u'\u597d': 1}, {u'\uff01': 1}]
{u'\uff01': 1.845826690498331, u'\u4e66': 1.845826690498331, u'\u8d28': 1.845826690498331,
u'\u592a': 1.845826690498331, u'\u4e0d': 1.845826690498331, u'\u672c': 1.845826690498331,
u'\u91cf': 1.845826690498331, u'\u8fd9': 1.845826690498331, u'\u597d': 1.845826690498331, u'\u771f': 1.845826690498331}
繁简体转换:
「繁体字」「繁体中文」的叫法在台湾亦很常见。
>>>
同样可以进行文本相似度计算,代码参考下图所示:

4.情感分析
SnowNLP情感分析也是基于情感词典实现的,其简单的将文本分为两类,积极和消极,返回值为情绪的概率,越接近1为积极,接近0为消极。其原理参考zhiyong_will大神和邓旭东老师的文章,也强烈推荐大家学习。地址:
情感分析——深入snownlp原理和实践
自然语言处理库之snowNLP

下面简单给出一个情感分析的例子:
# -*- coding: utf-8 -*-
from snownlp import SnowNLP
s1 = SnowNLP(u"我今天很开心")
print(u"s1情感分数:")
print(s1.sentiments)
s2 = SnowNLP(u"我今天很沮丧")
print(u"s2情感分数:")
print(s2.sentiments)
s3 = SnowNLP(u"大傻瓜,你脾气真差,动不动就打人")
print(u"s3情感分数:")
print(s3.sentiments)
输出结果如下所示,当负面情感特征词越多,比如“傻瓜”、“差”、“打人”等,分数就会很低,同样当正免情感词多分数就高。
s1情感分数:
0.84204018979
s2情感分数:
0.648537121839
s3情感分数:
0.0533215596706
而在真实项目中,通常需要根据实际的数据重新训练情感分析的模型,导入正面样本和负面样本,再训练新模型。
sentiment.train(’./neg.txt’, ‘./pos.txt’)
sentiment.save(‘sentiment.marshal’)
四.SnowNLP情感分析实例
下面的代码就是对爬取的豆瓣电影《肖申克的救赎》评论进行情感分析。
1.情感各分数段出现频率
首先统计各情感分数段出现的评率并绘制对应的柱状图,代码如下:
# -*- coding: utf-8 -*-
from snownlp import SnowNLP
import codecs
import os
source = open("data.txt","r")
line = source.readlines()
sentimentslist = []
for i in line:
s = SnowNLP(i.decode("utf-8"))
print(s.sentiments)
sentimentslist.append(s.sentiments)
import matplotlib.pyplot as plt
import numpy as np
plt.hist(sentimentslist, bins = np.arange(0, 1, 0.01), facecolor = 'g')
plt.xlabel('Sentiments Probability')
plt.ylabel('Quantity')
plt.title('Analysis of Sentiments')
plt.show()
输出结果如下图所示:

对应的分数如下:
>>>
1.0
0.945862922561
1.0
0.979234476526
0.750839957904
0.491062087241
0.936143577844
0.641496807331
...
2.情感波动分析
接下来分析200条评论,每条评论的波动情况,代码如下所示:
# -*- coding: utf-8 -*-
from snownlp import SnowNLP
import codecs
import os
source = open("data.txt","r")
line = source.readlines()
sentimentslist = []
for i in line:
s = SnowNLP(i.decode("utf-8"))
print(s.sentiments)
sentimentslist.append(s.sentiments)
import matplotlib.pyplot as plt
import numpy as np
plt.plot(np.arange(0, 200, 1), sentimentslist, 'k-')
plt.xlabel('Number')
plt.ylabel('Sentiment')
plt.title('Analysis of Sentiments')
plt.show()
输出结果如下所示,呈现一条曲线,因为抓取的评论基本都是好评,所以分数基本接近于1.0,而真实分析过程中存在好评、中评和差评,曲线更加规律。

同时,在做情感分析的时候,我看到很多论文都是将情感区间从[0, 1.0]转换为[-0.5, 0.5],这样的曲线更加好看,位于0以上的是积极评论,反之消极评论。修改代码如下:
# -*- coding: utf-8 -*-
from snownlp import SnowNLP
import codecs
import os
#获取情感分数
source = open("data.txt","r")
line = source.readlines()
sentimentslist = []
for i in line:
s = SnowNLP(i.decode("utf-8"))
print(s.sentiments)
sentimentslist.append(s.sentiments)
#区间转换为[-0.5, 0.5]
result = []
i = 0
while i<len(sentimentslist):
result.append(sentimentslist[i]-0.5)
i = i + 1
#可视化画图
import matplotlib.pyplot as plt
import numpy as np
plt.plot(np.arange(0, 200, 1), result, 'k-')
plt.xlabel('Number')
plt.ylabel('Sentiment')
plt.title('Analysis of Sentiments')
plt.show()
绘制图形如下所示:

3.建议
这里简单补充五个建议,具体如下:
(1)情感分析通常需要和评论时间结合起来,并进行舆情预测等,建议读者尝试将时间结合。比如王树义老师的文章《基于情感分类的竞争企业新闻文本主题挖掘》。

(2)情感分析也是可以进行评价的,我们前面抓取的分为5星评分,假设0-0.2位一星,0.2-0.4位二星,0.4-0.6为三星,0.6-0.8为四星,0.8-1.0为五星,这样我们可以计算它的准确率,召回率,F值,从而评论我的算法好坏。
(3)作者还有很多情感分析结合幂率分布的知识,因为需要写文章,这里暂时不进行分享,但是这篇基础文章对初学者仍然有一定的帮助。
(4)BosonNLP也是一个比较不错的情感分析包,建议感兴趣的读者学习,它提供了相关的词典,如下:https://bosonnlp.com/dev/resource。
(5)读者如果不太擅长写代码,可以尝试使用情感分析系统。http://ictclas.nlpir.org/nlpir/
比如分析评论:
当年的奥斯卡颁奖礼上,被如日中天的《阿甘正传》掩盖了它的光彩,而随着时间的推移,这部电影在越来越多的人们心中的地位已超越了《阿甘》。每当现实令我疲惫得产生无力感,翻出这张碟,就重获力量。毫无疑问,本片位列男人必看的电影前三名!回顾那一段经典台词:“有的人的羽翼是如此光辉,即使世界上最黑暗的牢狱,也无法长久地将他围困!”



基础性文章,希望对大家有所帮助,不喜勿喷,2018年马上结束,祝大家新年快乐,学到更多知识,认识这个大千世界。也推荐下我的年终总结文章。
2018年总结:向死而生,为爱而活——忆编程青椒的戎马岁月

(By:Eastmount 2018-12-21 中午12点 http://blog.csdn.net/eastmount/ )