深度学习部分网络记录+lenet5 网络源码 + 手写字体训练图片
个人感觉第一个深度学习网络算是 Lenet5 , 当时用于手写字体的识别, 可以下载mnist 公共数据库 用于测试。
论文链接:Gradient-Based Learning Applied to Document Recognition
在lenet 出现之前,神经网络主要是bp的方式来实现,但是该方法存在过拟合,计算量大等问题,在深度学习未出现之前,字符的分类主要是通过bp实现,经典的应用就是车牌识别了。在安防领域应用。
lenet在针对bp的弱点进了基础关键的改进:
1、感受野,感受野类似于传统方法中的注意力机制。将目标集中在一小块区域,而不是整张图片,这样训练出来的特征将会更加针对。同时在也大大减少了神经元链接的数量。早起的感受野一般都是很大的卷积如11 x 11 7 x 7 5 x 5,主要是由于一开始图像的分辨率比较大,但是大的卷积运算量会很大如单通道 32 x 32 通过 5x5卷积 转为 28 x 28 其中的计算量是 28 x 28 x 5 x5 = 19600其中不考虑加法运算。 后来人们发现两个3x3 可以表示的5x5的感受野,同时计算量大大的降低,如果单通道 32 x 32 通过两个6 x 3x3卷积 转为 6 x 28 x 28 则计算量为 30 x 30 x 3 x 3 + 28 x 28 x 3 x 3 = 15156 ,当卷积数量和featuremap数量多时,节省的数量更客观,而且 两个卷积表示的是非线性关系,比单个卷积的线性关系能更好的表达图像。先想到这些。
2、权值共享,相对于原来的bp算法如32x32 --》 6 x 28 x 28 ,此时的网络节点参数个数为 32 x 32 x 6 x 28 x 28,更换为权值共享够的网络参数个数为 5 x 5 x 6 + 偏置,大大减少了模型的内存,题外话,在任何硬件设备上做算法(arm,dsp等),内存容量和读写速度永远是一个绕不开的话题。
3、池化层,将特征图分辨率降低,减少计算量,同时有助于降低过拟合。在我看来,池化层裁剪了特征,降低了特征的冗余。目前的池化方法有求平均,最大值。
4、激活函数,在lenet中还是sigmod,该方法存在梯度弥散和梯度爆炸的风险,目前主要有relu,prelu 等。
5、全连接, 全连接类似bp网络,全连接可以随意定义输出变量的个数,但是和之前所说的,计算量极大,现在主流是全卷积网络。但这个可能需要根据实际情况进行设计。
6、损失函数,softmaxwithloss。
lenet5的网络结构如下图:
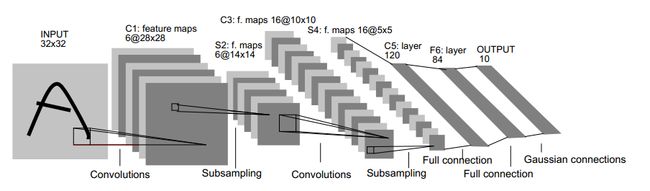
下面用caffe实现原始的结构和一个优化的结构。
lenet 手写数据库下载并打标签:
cd $CAFFE_ROOT
./data/mnist/get_mnist.sh
./examples/mnist/create_mnist.shlayer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
scale: 0.00390625
}
data_param {
source: "/home/test/mnist_train_lmdb"
batch_size: 64
backend: LMDB
}
}
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
scale: 0.00390625
}
data_param {
source: "/home/test/mnist_test_lmdb"
batch_size: 1000
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 6
kernel_size: 5
pad: 0
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "sigmoid1"
type: "Sigmoid"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 16
kernel_size: 5
pad: 0
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "sigmoid1"
type: "Sigmoid"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "fc1"
type: "InnerProduct"
bottom: "pool2"
top: "fc1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 120
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "sigmoid1"
type: "Sigmoid"
bottom: "fc1"
top: "fc1"
}
layer {
name: "fc2"
type: "InnerProduct"
bottom: "fc1"
top: "fc2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 84
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "sigmoid1"
type: "Sigmoid"
bottom: "fc2"
top: "fc2"
}
layer {
name: "fc3"
type: "InnerProduct"
bottom: "fc2"
top: "fc3"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc3"
bottom: "label"
top: "loss"
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc3"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
net: "/home/test/train_val.prototxt"
test_iter: 200
test_interval: 1000
#base_lr: 0.001
#momentum: 0.9
#weight_decay: 0.0005
#gamma: 0.01
#power: 1
#lr_policy: "fixed"
base_lr: 1e-3
lr_policy: "step"
gamma: 0.1
power: 1
momentum: 0.9
weight_decay: 1e-05
stepvalue: 10000
stepsize: 10000
display: 200
max_iter: 100000
snapshot: 5000
snapshot_prefix: "/home/test/result/"
solver_mode: GPU 改进后的网络如下:
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
scale: 0.00390625
}
data_param {
source: "/home/test/mnist_train_lmdb"
batch_size: 64
backend: LMDB
}
}
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
scale: 0.00390625
}
data_param {
source: "/home/test/mnist_test_lmdb"
batch_size: 1000
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 6
kernel_size: 3
pad: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "pool1"
top: "conv3"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 8
kernel_size: 3
pad: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv3"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv5"
type: "Convolution"
bottom: "pool2"
top: "conv5"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 64
kernel_size: 3
pad: 0
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "conv6"
type: "Convolution"
bottom: "conv5"
top: "conv6"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 32
kernel_size: 3
pad: 0
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "conv6"
top: "conv6"
}
layer {
name: "conv7"
type: "Convolution"
bottom: "conv6"
top: "conv7"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 10
kernel_size: 3
pad: 0
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "conv7"
bottom: "label"
top: "loss"
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "conv7"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
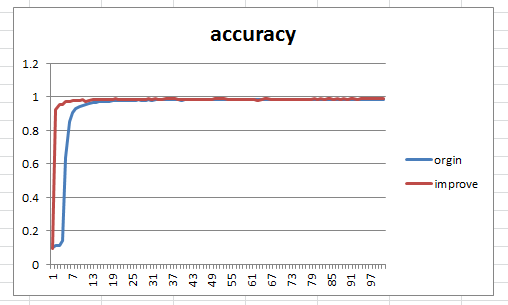
} 两者文件大小,原始的为175K 后者为105K,两者的accuracy对比如下,其中每1000次迭代记录一次:
工程下载地址如下:https://download.csdn.net/download/eatapples/10313749
其中包括 6000张的手写字体样本,两个训练出来的模型文件,包括所有的prototxt文件
转载请声明出处:https://blog.csdn.net/EatAppleS/article/details/79630673