自然语言处理NLP(8)——句法分析b:完全句法分析
在上一部分中,我们简单介绍了完全句法分析的概念,并详细介绍了句法分析的基础:Chomsky形式文法(自然语言处理NLP(7)——句法分析a:Chomsky(乔姆斯基)形式文法)。
在这一部分中,我们将对完全句法分析进行详细介绍。
回顾一下,句法分析共有三种类型:完全句法分析、局部句法分析、依存关系分析。
对于完全句法分析,还是NLP领域中常用的三种解决方法:规则法、概率统计法、神经网络方法。
下面我们从这三个方法入手,对完全句法分析算法进行介绍。
【一】规则句法分析算法
从上述句法分析树的生成过程来看,很明显,句法分析算法大致上由三种策略:
1.自底向上
2.自顶向下
3.自底向上于自顶向下相结合
自底向上的方法从句子中的词语出发,基本操作是将一个符号序列匹配归约为其产生式的左部(用每条产生式左边的符号来改写右边的符号),逐渐减少符号序列直到只剩下开始符S为止。
自顶向下的方法从符号S开始搜索,用每条产生式右边的符号来改写左边的符号,然后通过不同的方式搜索并改写非终结符,直到生成了输入的句子或者遍历了所有可能的句子为止。
常用的句法分析算法有线图(chart)分析算法、CYK分析算法等等。
线图法将每个词看作一个结点,通过在结点间连边的方式进行分析,算法的时间复杂度为 O ( K n 3 ) O(Kn^3) O(Kn3),其中 n n n为句子中词的个数;
CYK方法通过构造识别矩阵进行分析,时间复杂度相对线图法有所减小。
具体算法在这里不进行赘述,有兴趣的朋友们可以自行查阅相关资料~
无论对于上述任何一种方法而言,都由一个共同的缺点:难以区分歧义结构。
因此,引入概率统计法进行句法分析。
【二】概率统计句法分析算法
利用概率统计法进行句法分析,主要采用概率上下文无关文法(PCFG),它是CFG的概率拓广,可以直接统计语言学中词与词、词与词组以及词组与词组之间的规约信息,并且可以由语法规则生成给定句子的概率。
在这里多说一句,在NLP领域中,如果引入了概率,那么这种方法的作用很有可能是消歧,因为我们可以根据概率的大小对可能出现的情况进行选择。
而概率上下文无关文法(PCFG)的主要任务有两个:
1.句法分析树的消歧
2.求最佳分析树
二者之间有很大的相似之处。
概率上下文无关文法(PCFG)
一个PCFG由如下五个部分组成:
1.一个非终结符号集 N N N
2.一个终结符号集 ∑ \sum ∑
3.一个开始非终结符 S ∈ N S∈N S∈N
4.一个产生式集 R R R
5.对任意产生式 r ∈ R r∈R r∈R,其概率为 P ( r ) P(r) P(r),产生式具有形式: X → Y , P X\rightarrow Y, P X→Y,P
其中, X ∈ N , Y ∈ ( N ∪ ∑ ) ∗ X∈N,Y∈(N∪\sum)^* X∈N,Y∈(N∪∑)∗,且 ∑ λ ( X → λ ) = 1 \sum_λ(X\rightarrow λ)=1 ∑λ(X→λ)=1
前四个部分与Chomsky形式文法中的概念类似,在这里不再进行赘述。
举个例子(这里只列出重写规则——产生式集 R R R):
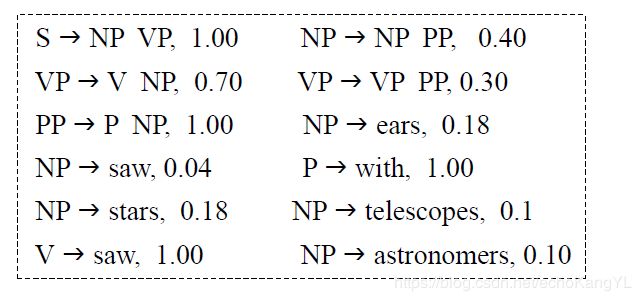
朋友们可能还是没有一个直观的了解,那么我们来对比一下PCFG和CFG。
对于一个句子‘Astronomers saw stars with ears’,分别用PCFG和CFG进行分析:
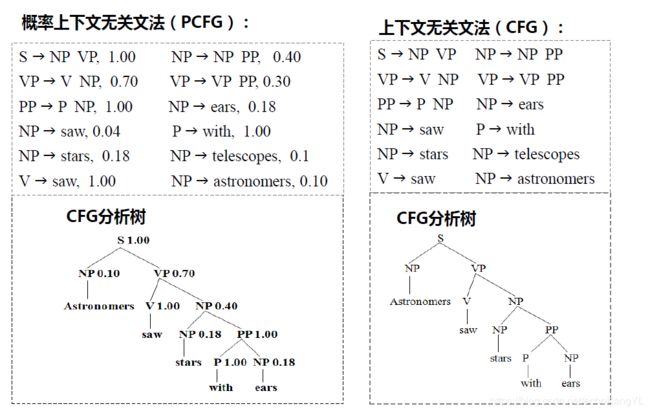
对于PCFG图中的概率值如何使用,朋友们可能已经有了一些想法,我们在后文中会提到,在这里把它放下,先考虑一下各个概率值是怎么来的。
与HMM模型参数学习的过程相类似(自然语言处理NLP(4)——序列标注a:隐马尔科夫模型(HMM)),对于有大规模标注的树库语料,利用最大似然估计(MLE)对概率值进行统计;对于没有大规模语料库的情况,借助EM迭代算法估计PCFG的概率参数。
从个人理解的角度来看,最大似然估计的过程就是一个数(三声)数(四声)的过程,具体过程与在之前章节提到的类似,不理解的朋友们可以参考:自然语言处理NLP(2)——统计语言模型、语料库
在了解了PCFG基本结构和其中的P是怎么来的之后,我们考虑一下这个P是干什么的。
其实很简单,每个规则的概率合在一起能做什么,用来计算整棵树出现的概率呗。
在此之前,我们探讨一下计算分析树概率的基本假设:
1.位置不变性:子树的概率与其管辖的词在整个句子中所处的位置无关。
2.上下文无关性:子树的概率与子树管辖范围以外的词无关。
3.祖先无关性:子树的概率与推导出该子树的祖先结点无关。
三个假设都很好理解,在这里就不做过多解释了。
还是以上例分析:

生成的整棵句法树的概率就是以这种方式计算出来的(其实就是概率值按照树结构的累乘,很容易理解)。
有了概率,消歧就很容易了:
假设上面的句子可以生成两个不同的句法树 t 1 , t 2 t_1,t_2 t1,t2:
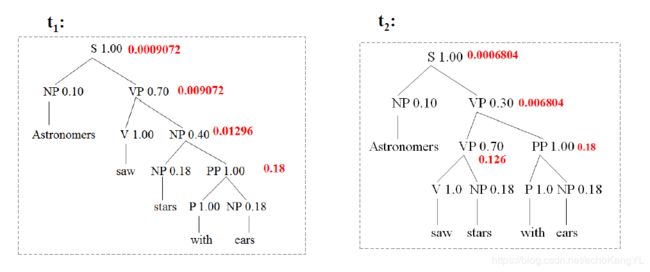
很明显,选择概率大的句法树 t 1 t_1 t1 作为句法分析的结果。
对于给定的句子 S S S ,如有两棵句法分析树的概率不等且 P ( t 1 ) > P ( t 2 ) P(t_1)>P(t_2) P(t1)>P(t2),则分析结果 t 1 t_1 t1 正确的可能性大于 t 2 t_2 t2,据此可以进行句法歧义消解。
特别地,语句在文法的概率等于所有分析树概率之和。
有了概率,有了选择分析树的方法,对于给定的一个句子,能不能求出最佳分析树呢?
很明显,我们有一种稍显笨拙的方法:穷举法——找到每一个可能的句法树,计算概率,然后取概率最大的句法树作为分析结果。但是这种方法有很大的弊端:效率非常低,尤其是当句子较长,生成句法树有多棵时,效率极低。
之前在HMM评估问题和解码问题中(自然语言处理NLP(4)——序列标注a:隐马尔科夫模型(HMM)),我们曾经介绍过以动态规划改进穷举算法的Viterbi算法,对于求解最佳分析树问题,也有类似的算法——PCFG Viterbi算法。
PCFG Viterbi算法
首先,与Viterbi算法类似,先定义PCFG Viterbi算法中的变量:
γ i j ( A ) γ_{ij}(A) γij(A):非终结符 A A A 推导出语句 W W W 中子字串 w i w i + 1 . . . w j w_iw_{i+1}...w_j wiwi+1...wj 的最大概率
ψ i , j \psi_{i,j} ψi,j:记忆字串 w i w i + 1 . . . w j w_iw_{i+1}...w_j wiwi+1...wj 的Viterbi语法分析结果
此外,我们的输入是文法 G ( S ) G(S) G(S) 以及语句 W = w 1 w 2 . . . w n W=w_1w_2...w_n W=w1w2...wn
PCFG Viterbi算法流程如下:
1.初始化:
γ i i ( A ) = p ( A → w i ) , A ∈ V N , 1 ≤ i ≤ n γ_{ii}(A)=p(A \rightarrow w_i), \quad A∈V_N, \quad 1\le i \le n γii(A)=p(A→wi),A∈VN,1≤i≤n
2.归纳计算:对于 j = 1 , 2 , . . . , n , i = 1 , 2 , . . . , n − j j=1,2,...,n, \quad i=1,2,...,n-j j=1,2,...,n,i=1,2,...,n−j,重复下列计算
γ i ( i + j ) ( A ) = max B , C ∈ V N ; i ≤ k ≤ i + j p ( A → B C ) γ i k ( B ) γ ( k + 1 ) ( i + j ) ( C ) γ_{i(i+j)}(A)=\displaystyle\max_{B,C∈V_N;i \le k \le i+j}p(A \rightarrow BC)γ_{ik}(B)γ_{(k+1)(i+j)}(C) γi(i+j)(A)=B,C∈VN;i≤k≤i+jmaxp(A→BC)γik(B)γ(k+1)(i+j)(C)
ψ i ( i + j ) ( A ) = max B , C ∈ V N ; i ≤ k ≤ i + j p ( A → B C ) γ i k ( B ) γ ( k + 1 ) ( i + j ) ( C ) \psi_{i(i+j)}(A)=\displaystyle\max_{B,C∈V_N;i \le k \le i+j}p(A \rightarrow BC)γ_{ik}(B)γ_{(k+1)(i+j)}(C) ψi(i+j)(A)=B,C∈VN;i≤k≤i+jmaxp(A→BC)γik(B)γ(k+1)(i+j)(C)
输出:分析树根结点为 S S S (文法开始符号),从 ψ 1 , n ( S ) \psi_{1,n}(S) ψ1,n(S)开始回溯,得到最优树。
上述过程可能有些抽象,我们来举个例子。
假设有如下PCFG:
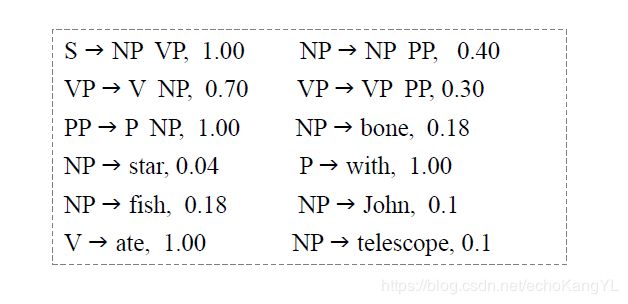
输入的句子为:‘John ate fish with bone’,求它的最佳分析树。
过程如下图所示:
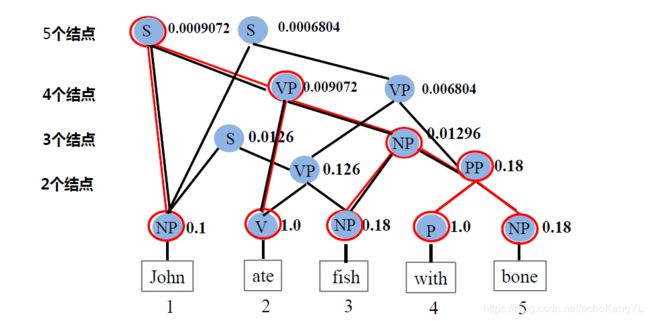
上图中,PCFG Viterbi算法是从最底层开始执行的:最底层的竖线链接相当于初始化过程;
此后,按照上面描述的算法过程分别计算两个词、三个词(图中的结点)构成文法的概率,直到最后一层。
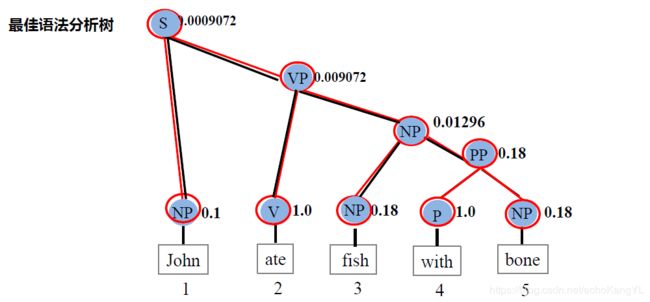
最后,对整个句子进行回溯即可得到最佳分析树:
【三】神经网络句法分析
在介绍神经网络句法分析方法之前,首先要了解递归神经网络RvNN。
很明显,在句法分析中,我们希望将句子按照结构进行分解,得到分析树。
以此为目标,RvNN的基本思想很简单:希望将问题在结构上分解为一系列相同的“单元”,单元的神经网络可以在结构上展开,且能沿展开方向传递信息。
具体有关RvNN的内容在这里就不再赘述,不了解的朋友们可以参考博客:神经网络基础:DNN、CNN、RNN、RvNN、梯度下降、反向传播,里面有很详细的介绍。
现在,我们有了RvNN,想要对一句话进行句法分析,要怎么做呢?
其实过程与上述PCFG Viterbi算法有相似之处,我们来举个例子。
假设有一句话:“我弟弟准备一切用品”,我们已经对它做好了词法分析,于是这句话成了这个样子:
“我/PN 弟弟/NN 准备/VV 一切/QP 用品/NN”(空格表示分词)。
在这里再次强调一下,所有句法分析的输入一定是词法分析之后具有词性等信息的,已经分好词的句子。
然后,我们将分好词的句子输入神经网络:
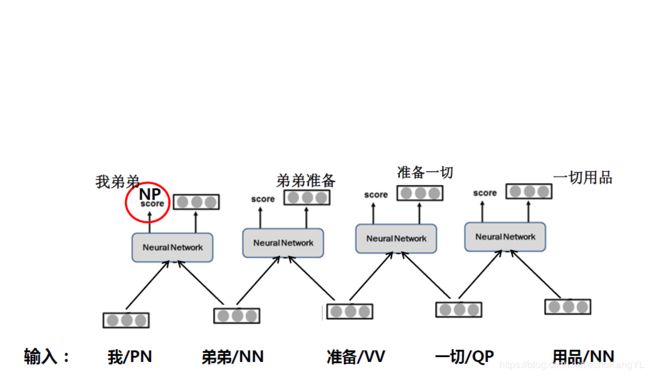
此时,神经网络可以得到“我弟弟”、“弟弟准备”、“准备一切”、“一切用品”这四种组合的打分,假设“我弟弟”的打分最高,那么神经网络将选出这两个词进行组合。
组合之后,“我弟弟”就成了一个词,各组成部分不可单独与句子中的其他词进行组合,网络结构变成了这个样子:
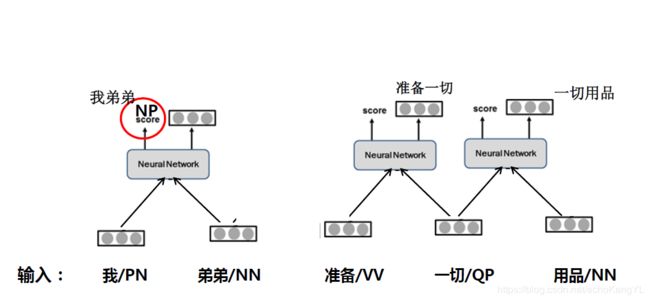
接下来,继续对相邻两个词进行组合:
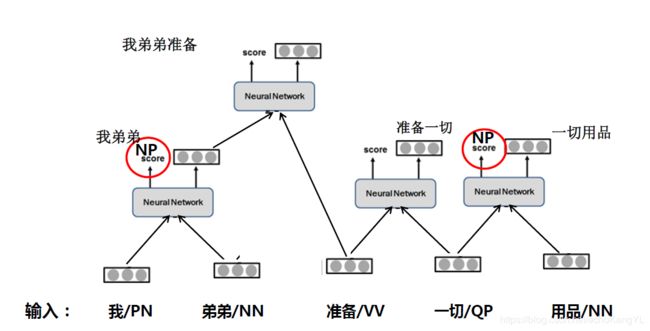
假设这一步中“一切用品”的打分最高,神经网络选出这两个词进行组合,各组成部分不可再单独与句子中的其他词进行组合,网络结构调整如下:
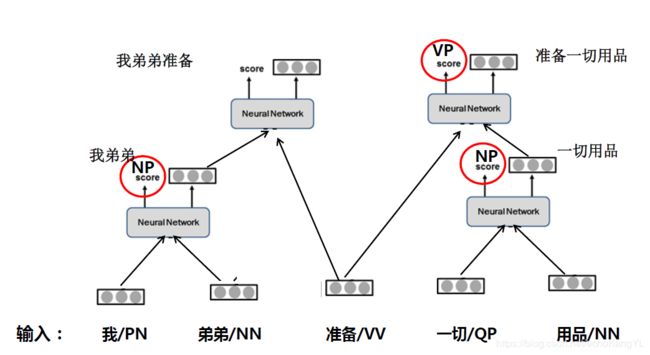
我们可以看到,“准备一切”的组合已经消失,因为“一切”已经和“用品”组成一个词“一切用品”。
而“准备”还未与任何词(或词组)进行组合,因此计算“我弟弟准备”和“准备一切用品”的打分,假设后者得分更高。
那么下一步:
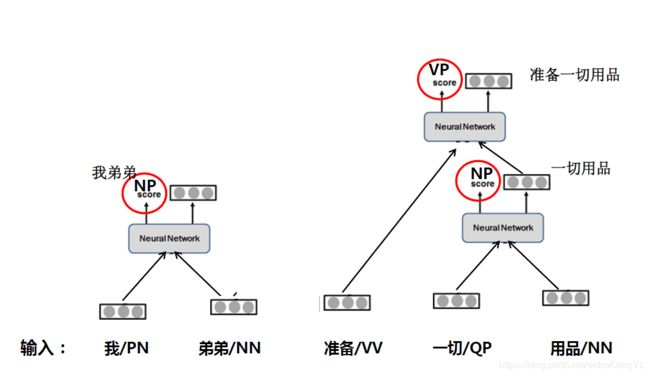
最后,我们得到:
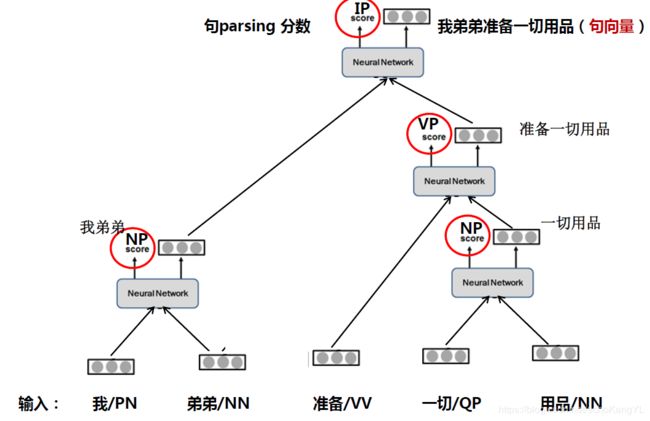
至此,句法分析完成,我们得到了句向量和该种结构的打分。
【四】句法分析评价标准
在了解了各种句法分析方法之后,我们来看看如何评价一个句法分析结果的好坏。
分析树中 非终结符节点 (短语)标记格式如下:
XP-(起始位置:终止位置)
其中,XP为短语名称,(起始位置:终止位置)为该节点的跨越范围,起始位置指该节点所包含的子节点的起始位置,终止位置为该节点所包含的子节点的终止位置。
举个例子:
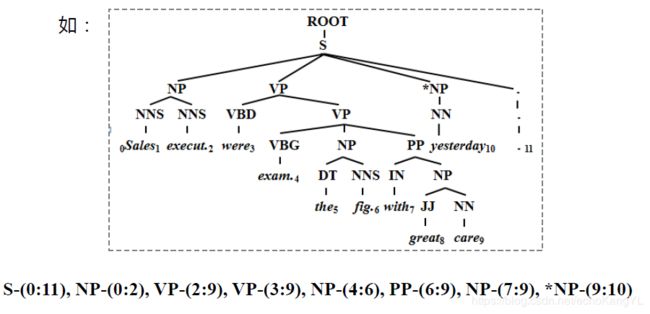
性能指标依然是老三样:精度(precision, P)、召回率(recall, R)以及F值。
对这三个概念不了解的朋友们可以参考:自然语言处理NLP(6)——词法分析中的第五部分:词法分析评价指标。
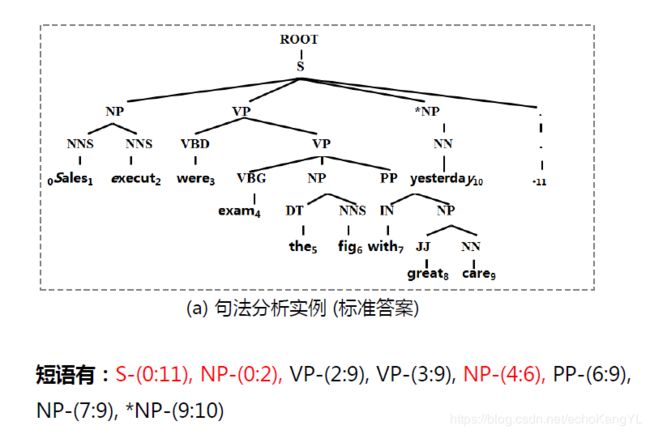
假设我们有这样一句话:
‘Sales executives were examining the figures with great care yesterday.’
我们给出的标准句法分析答案如下:
模型给出的答案如下:
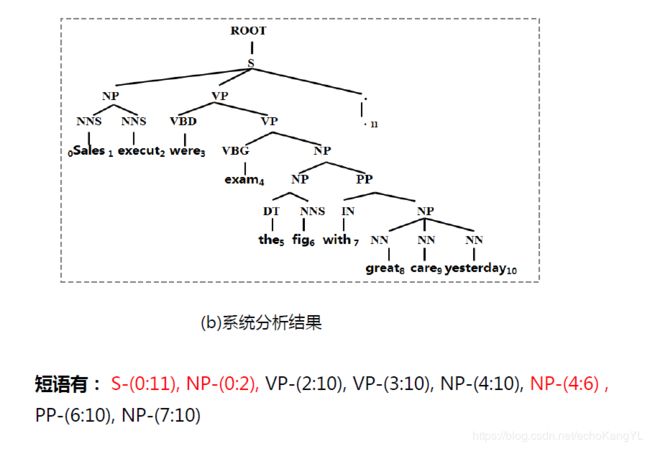
二者结果中红色部分是相同的部分,表示系统分析结果只有3个短语与标准答案完全一样,且标准输出和系统分析结果都有8个短语,那么:
P = 3 / 8 R = 3 / 8 F = 3 / 8 P = 3/8 \quad \quad R = 3/8 \quad \quad F = 3/8 P=3/8R=3/8F=3/8
在这一部分中,我们主要介绍了完全句法分析,并详细介绍了解决完全句法分析问题的三种方法:规则法、概率法、神经网络法。
在下一部分的内容中,我们将会介绍句法分析领域的另外两个主题:局部句法分析、依存关系分析。
如果本文中某些表述或理解有误,欢迎各位大神批评指正。
谢谢!