基于Infiniband高性能集群硬件配置方案

摩尔定律的一再验证残酷的揭示了一个现实:速度是技术发展的终极目标。高性能计算领域也是一样,如何使高性能计算平台运行的更快、更高效一直是服务器厂商研究的方向,曙光作为中国高性能计算的领头羊,作为高端服务器厂商,也在为此做着不懈的努力。Infiniband高速网络是近几年产生的一种新兴技术,因其具有高带宽、低延迟的特色,得到了计算领域的青睐。本文介绍了Infiniband的硬件组成及其在不同应用中的选择依据,最后通过四个案例进行分析,构建一套符合用户需求的高性能计算网络。
1. 前言
近年来,世界上的超级计算已经由价格昂贵、无扩展性的单片机架构转变为采用商业处理器而拥有无限扩展能力的集群系统,称为高性能计算机集群(HPC:High Performance Computing)。美国Top500.org组织每年分别两次排列出当今世界上最强大的超级计算机,该排名按照超级计算机的实际计算能力(FLOPS:每秒浮点运算)按递减顺序排列。这个列表显示出集群架构正在逐渐取代单片机架构的趋势。由于HPC系统能够快速准确计算出结果,有助于解决商业和科学研究中面临的问题,所以,HPC系统越来越多的被政府部门、商业组织和科学院所采用。
然而,有一些部门和组织所面临的是更具挑战性的计算问题,他们需要更强大、高性能价格比的HPC系统。这就意味着人们必须要关注大集群的建设,这里的大集群是指规模超过100个节点,达到几百个、上千个甚至上万个节点的集群系统;将集群系统扩展到这样的规模而带来的困难和复杂程度是难以想象的;使这样规模的集群能够正常、稳定的工作也是一个痛苦的过程。在超级计算机发展的道路上不乏失败了的大型HPC系统的“尸体”,也说明了这是一个值得研究的问题。
选择一个正确的互连网络是能否达到甚至超过您对集群性能预期的关键。如上所述,一个集群中需要支持多种类型的数据流,所以,我们可以选择在同一集群中同时采用不同类型的互联网络,这些不同的网络将各自支持不同的网络协议,同时,这些不同的网络也拥有不同的网络性能和特性。例如,基于千兆以太网的网络,可以通过TCP/IP通道来传输信息,但缺点是需要占用大量CPU资源来处理网络通信,导致整体处理效率的下降;Myrinet 网络采用卸载引擎(offload engine)技术降低了CPU资源在处理通信方面的消耗,并且拥有千兆以太网两倍的带宽。在目前的Top500排名上千兆以太网技术和Myrinet都很普遍;然而Infiniband,由于是一个标准化的、开放的高性能互联技术平台,从小规模到大规模的可扩展性集群中也拥有很强的生命力。
2. Infiniband背景介绍
2.1. Infiniband发展历史
Infiniband是一种新型的总线结构,它可以消除目前阻碍服务器和存储系统的瓶颈问题,是一种将服务器、网络设备和存储设备连接在一起的交换结构的I/O技术。 它是一种致力于服务器端而不是PC端的高性能I/O技术。
Infiniband最初于2000年上市,但由于当时经济的不景气和IT预算紧缩,人们对它的兴趣很快就消散了。发展至今,I/O技术在企业服务器中无论是速率上还是吞吐量上都取得了稳步提高。但是,毫无疑问,现有的基于PCI架构的I/O技术仍然是系统处理器、系统主存以及I/O外设之间的主要瓶颈。这种I/O架构已经不能满足互联网、电子商务、存储网络等大量的I/O需求。随着对称多处理器(SMP)、集群计算、网格以及远程备份的广泛应用,这种基于PCI架构的I/O技术的缺陷和局限性日益突出。目前人们对互连技术的兴趣开始恢复,而且非常希望互连技术能够帮助数据中心降低成本或实现高性能的计算。随着各种高速I/O标准相继登场,Infiniband逐渐崭露头角。
Infiniband技术通过一种交换式通信组织(Switched Communications Fabric)提供了较局部总线技术更高的性能,它通过硬件提供了可靠的传输层级的点到点连接,并在线路上支持消息传递和内存映像技术。不同于PCI,Infiniband允许多个I/O外设无延迟、无拥塞地同时向处理器发出数据请求 。 目前,集群计算(Cluster)、存储区域网(SAN)、网格、内部处理器通信(IPC)等高端领域对高带宽、高扩展性、高QoS以及高RAS(Reliability、Availability and Serviceability)等有迫切需求,Infiniband技术为实现这些高端需求提供了可靠的保障。
2.2. Infiniband发展趋势
基于共享总线(Shared-Bus)的架构的诸多局限性决定了这项I/O技术已经不能适合日益庞大的计算机系统的I/O需求。这些局限性主要包括速率极限、可扩展性、单点故障等几个主要方面。而基于交换架构的Infiniband技术在避开PCI架构上述问题的同时,提供了其他方面的更高性能。基于Fabric与基于共享总线I/O技术之间的简要对比如下表所示。
1.Shared-Bus架构的局限性
PCI-X 133的带宽只有2GB/s,虽然目前公布的PCI-E的带宽峰值到4GBps,但这没有从根本上缓解服务器端的I/O带宽瓶颈。同样,PCI架构(主要是PCI-X)的可扩展性也非常有限,它主要通过两种方式来实现:要么增加同层PCI总线(PCI本身就是一种层次结构I/O技术),要么增加PCI-to-PCI桥。前者主要通过在主板上集成额外的Host-to-PCI总线芯片以及增加PCI连接器来实现,而后者主要通过在主板上增加PCI-to-PCI桥接芯片来实现。无论采用什么方式扩展PCI架构的I/O总线,其代价都是比较昂贵的。
在基于共享总线的I/O结构中,所有通信共享单一总线带宽,由此就造成外设越多,可用带宽就越少,从而带来更严重的系统I/O瓶颈。不仅如此,在基于共享并行I/O总线上,大量的引脚数目也带来了一定的电气特性和机械特性等问题,使得PCB空间、信号频率以及信号可传输距离都受到很大程度的制约。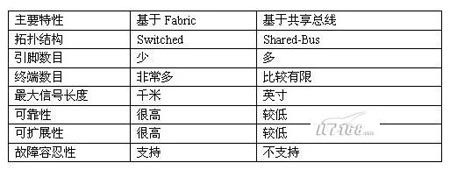
2.Switched Fabric体系结构的高可扩性
Infiniband所采用的交换结构(Switched Fabric)是一种面向系统故障容忍性和可扩展性的基于交换的点到点互联结构。这种结构如下图所示。
在上图中,通过向Infiniband系统添加交换机可以很容易地实现I/O系统的扩展,进而允许更多的终端设备接入到I/O系统。与基于共享总线的I/O系统相反,这种Switched Fabric系统的总体带宽会随着所接入交换设备数目的增加而不断提高。另外,正如上图所指出的那样,通过在Infiniband子结构之间添加路由设备,可以更大范围地扩充整个Infiniband系统。
Infiniband技术是一种开放标准的、目前全球带宽最高的高速网络互联技术,Infiniband产品是目前主流的高性能计算机互连设备之一。目前基于Infiniband技术的网络卡的单端口带宽最大可达到20Gbps,基于Infiniband的交换机的单端口带宽最大可达60Gbps,单交换机芯片可以支持达480Gbit每秒的带宽。到2006年,Infiniband技术可以达到单端口120Gbps,其单端口的带宽甚至远高于目前的主流交换机的总带宽,可以为目前和未来对于网络带宽要求非常苛刻的应用提供了可靠的解决方案。
Infiniband技术是采用RDMA传输机制实现了低延迟,高带宽的新型网络标准,并得到了行业中所有领军企业的支持;部分服务器厂家已经或计划将Infiniband芯片移植到主板上。
Infiniband 架构的这种快速增长主要得益于越来越多的企业级数据中心的建立部署和持续发展的高性能计算的应用。
2004年1月,IBM开始将Infiniband技术应用于其解决方案;
2004年1月,SUN 开始推出Infiniband解决方案;
2004年2月,HP的Infiniband 产品在市场上出现;
2004年2月,Dell 开始推出Infiniband解决方案;
2004年5月,SKY Computer 的嵌入式Infiniband方案被用于军事和工业应用;
2004年6月,NEC开始应用Infiniband到NEC刀片式服务器;
2004年6月,SBS 公司率先宣布推出基于VXWorks的 InfninBand 驱动;
2004年, HP和 Oracle多次刷新TPCH性能测试纪录;
2004年11月,在美国国家航空和宇宙航行局(NCSA),SGI完成了基于Infiniband互联技术的超级计算机,其运算速度位居世界第二。
2005年4月,Cisco 公司宣布收购 Infiniband 方案提供商-Topspin, 成为 Infiniband 产品的最大用户。
除此之外,Apple、Hitachi、Fujitsu等厂商也都已推出了基于Infiniband的解决方案;Engenio、NetApp、DataDirect、Engenio、Isilon、Terrascale和CFS等存储厂商也已推出或即将推出基于Infiniband技术的存储解决方案;Arima,、Iwill,、SuperMicro和Tyan等服务器主机板厂商也陆续推出了基于Infiniband芯片的LOM(Landed on Mainboard)方案。
而基于Infiniband技术的芯片、网卡和交换机主要供应商Mellanox公司已取得里程碑式的销售成绩----50万个 Infiniband 端口,这些端口体现在多种产品形式上,包括:集群服务器、高带宽交换机、嵌入式平台和集群存储系统。
“因为 Infiniband 有着极佳的扩展性与性能,由许多公司包括Mellanox在内所生产的10Gb/s适配卡,会帮助用户压低集群中每个节点的成本,”英特尔 数字企业集团行销主管 Jim Pappas 说道:“ Infiniband 产品种类的增多对应用于商业和科学计算领域的 10Gb/s 带宽计算机集群的发展有着积极的影响。”另外,InfiniHost III Lx HCA 卡把这种高性能通讯技术同时打入了高速存储和嵌入式应用这两个市场。
由此可见,Infiniband的整体解决方案已经成形,这个整体解决方案的出现,必将带来高性能计算平台和数据中心的一次变革,让长期以来一直高高在上的高性能解决方案变得大众化。
2.3. Infiniband技术特色
图示: 传输小数据包的性能测试
许多应用对信息传输的延迟是很敏感的,传输的延迟随着所传输信息的大小而有所不同,所以,同时了解互连网络在传输小信息和大信息时的延迟非常重要。通过对集群中两节点间进行的延迟基准测量,可以看到Infiniband设备在各种处理器平台上延迟都是最低。
需要指出的是,延迟的基准测试中一般都是采用了最小的数据包及0字节的数据包进行传输,得到结果,并没有反映出实际工作时的情况;而实际应用中,数据包一般比较大,这时就对带宽提出了要求。
图示4K数据包时各种网络的延迟
在传输4K大小的数据包时,Infiniband 10Gbps的带宽优势很明显,传输速度远远优于Myrinet和千兆以太网。
需要注意的是,所有公开的网络延迟都是在最佳情况下测得的。最佳情况是指参与测试的两台服务器只通过了一个交换芯片连接;但是,随着集群规模的扩大,底层的交换结构也将扩大,传输数据包所需经过的交换设备也在不断的增加,每一个交换设备都会在数据包传输到目的地的过程中增加额外的延迟;单独看待一台交换机硬件上的延迟是很小的,相比其他部分产生的延迟,可以忽略;但是站在整套集群架构来看,考虑这个延迟的重要性就显现出来。考虑了设备的延迟,还需要考虑物理层(设备)以上的各种网络协议在传输数据时产生的延迟。Infiniband的设计采用了传输协议卸载和绕过OS技术,也称为RDMA(远程直接存储访问),从而减少了通信对CPU的开销,将CPU的计算资源留给了应用。对于应用,越多的CPU资源意味着计算工作能够更快的完成或更多复杂的模拟可以在同一时间内完成。所有的这些降低延迟的特性集合起来证明
了Infiniband的能力。
由于协议、通信和CPU的负载将会随着节点的增加而占用越来越多的CPU计算资源,所以,保证可用的CPU资源总数能够随着集群规模而线性增加是非常重要的。这一性能可以通过HPL(High-Performance Linpack)测试结果来体现。HPL的测试结果用百分数表示:实际应用所占的计算资源与整体计算资源相除得出百分比。需要指明的是,即使是一台双CPU的服务器,没有任何互联设备,在做HPL测试时,也不可能达到100%的效率。这就要求互连设备能够随着集群增大而尽量保持较高的HPL效率,下图表显示了使用同种处理器而处理器数量从4到288个时的HPL效率,Infiniband再次取得了最好的性能。
Top500 上相同CPU各种网络的HPL效率
与同类其它产品(如10Gbit以太网卡)相比较,Infiniband产品也具有明显的优势,其价格是目前10Gbit以太网卡的十分之一,但是Infiniband HCA卡的功耗却是10Gbit以太网卡的七分之一,同时具有带宽更大,延时更低,面积更小,对于CPU的占用率更低,基于Infiniband平台的软件更加成熟等优势。
随着双核处理器的出现、PCI-Express总线的发展、超级计算机的规模越来越大,对于高带宽、低延时的需求变得越来越苛刻;数据库机群的发展,华尔街/金融分析的精确度的增加,制造业、石油、气象、生物等仿真技术的发展; 等等。高性能、低价格的网络互连方案变得日益重要,所有的一切都在推动Infiniband在快速的成为市场的主流,在科学计算、高速存储和嵌入式应用等市场变得越来越普及。
2.3.1. Infiniband常用术语
HCA – Host Channel Adapter (主信道适配器)
TCA – Target Channel Adapter (目标信道适配器)
QP – Queue Pair 每一个HCA可以同时支持几千个QP(s)。QP(s)由需要通信的节点产生。
SM – Subnet Manager 子网管理器(配置IB结构的软件)
ULP – Upper Layer Protocol (软件包,采用Infiniband提供所定义的功能和服务)
CM – Communication Manager (ULP所使用的软件,用来调节节点机间所产生的QP)
LID – 16bit Local Identifier 由子网管理器分配的标识
2.3.2. Infiniband技术优势
Infiniband是一种交换结构I/O技术,其设计思路是通过一套中心机构(中心Infiniband交换机)在远程存贮器、网络以及服务器等设备之间建立一个单一的连接链路,并由中心Infiniband交换机来指挥流量,它的结构设计得非常紧密,大大提高了系统的性能、可靠性和有效性,能缓解各硬件设备之间的数据流量拥塞。而这是许多共享总线式技术没有解决好的问题,例如这是基于PCI的机器最头疼的问题,甚至最新的PCI-E也存在这个问题,因为在共享总线环境中,设备之间的连接都必须通过指定的端口建立单独的链路。
Infiniband的四大优点:基于标准的协议,每秒10 GB性能,远程直接内存存取(Remote Direct Memory Access,简称RDMA)和传输卸载(transport offload)。
标准:成立于1999年的Infiniband贸易协会 由225家公司组成,它们共同设计了该开放标准。主要掌控该协会的成员包括:Agilent, Dell, HP, IBM, InfiniSwitch, Intel, Mellanox, Network Appliance和Sun Microsystems公司。其他的100多家成员则协助开发和推广宣传该标准。
速度:Infiniband每秒10gigabytes的性能明显超过现有的Fibre Channel的每秒4 gigabits,也超过以太网的每秒1 gigabit的性能。
内存:支持Infiniband的服务器使用主机通道适配器(Host Channel Adapter,简称HCA),把协议转换到服务器内部的PCI-X或者PCI-Xpress总线。HCA具有RDMA功能,有时也称之为内核旁路(Kernel Bypass)。RDMA对于集群来说很适合,因为它可以通过一个虚拟的寻址方案,让服务器知道和使用其他服务器的部分内存,无需涉及操作系统的内核。
传输卸载(Transport Offload): RDMA 能够帮助传输卸载,后者把数据包路由从OS转到芯片级,节省了处理器的处理负担。要是在OS中处理10 Gbps的传输速度的数据,就需要 80 GHz处理器。
中央处理器CPU与其存储子系统的设计是集群系统性能的指示器;但是,随着集群规模的扩展,保证CPU的资源不被占用的关键是互连网络。互连网络的任务就是将集群中海量的应用数据以尽可能快的速度从节点“A”传到节点“B”,那么从不同部分产生的延迟就是需要考虑的关键。所以,为了达到最佳的应用效率,就要
对可能产生延迟的部分做到延迟最小化。幸运的是,虽然产生延迟的部分有很多,但是,大多数延迟的瓶颈可以在互连网络这一级得到解决。 
图示:Infiniband在数据传输中的位置
采用Infiniband的系统具有很强的可扩展性:按需购买,按需升级,按需扩展
a) 性能升级 :硬件和软件可以进行上下兼容,新的驱动可以在原有设备上进行安装,提高性能。
b)带宽升级:3.3Gbps和5Gbps和10Gbps的三种解决方案之间可以进行灵活的升级;客户所需要的只是增加交换机的背板模块。
c)规模升级:交换机之间可以进行堆叠来实现集群扩展。IO9120(144端口),IO9240(288端口)的交换机,都是以12端口为单元进行扩展的,均采用通用模块;由于Silverstorm(原Infinicon)子网管理器可以实现动态部署,无需对集群进行重新配置,添加的节点实现即插即用。
使用和维护简单:
产品中有集群辅助工具: Fast Fabric Tool (FFT);该工具可以对快速的集群进行安装、硬件可靠性测试、集群性能、测试和软件驱动的升级;当采用FFT进行了Silverstorm(原Infinicon)公司网络的安装之后,在新的驱动版本推出后,通过FFT在最初安装时留下的端口,只需一条命令就可以对整套集群进行软件的升级。
a)高带宽(每秒传输10Gb);
b)低延迟(最低4.5us);
c)QOS功能;
d)高扩展性;
e)直接与存储设备和以太网连接,形成三网合一;
f)基于TCP/IP的应用不需要任何改动即可利用Infiniband的特性;
g)RDMA协议的应用,减轻CPU的协议消耗;
h)与PCI-EXPRESS总线捆绑,能体现Infiniband更大的优势。
除了以上技术上的优势外,由于该技术标准定义了后续产品的技术指标,如带宽达到30G,60G等,所以用户选择该技术可以保证其利益的延续性和技术领先优势。
这些智能化、模块化的设计可以允许客户按照应用的实际需求来配置集群。有一些应用的需要尽可能大的带宽,那么可以利用Infiniband单向10Gb/s、双向20Gb/s的带宽;而一些应用不需要这样高的带宽,目前需要2.5Gb/s的带宽就足够的应用在将来可能需要更大的带宽。所以设计集群的时候,结构上的灵活度也很重要:最理想的状况,用户可以拥有满足现有应用所需的带宽的同时还能够动态的灵活快速的满足将来应用对带宽的需要。在Infiniband以前,现有主流的高速集群网络传输速度局限在2.5Gb/s或更低。现在,利用Infiniband的带宽优势,集群的结构可以有多种多样的带宽上的选择和配置。不同的配置是确保每两节点间通信最小带宽为3.3Gb/s。需要注意的是,这种配置下的每一个节点的Infiniband带宽能力仍然是10Gb/s,只是将多对服务器共享一条交换机的内部互连带宽:当这多对服务器只有一对通信时,通信带宽为10Gb/s;两对同时工作时,通信带宽为5Gb/s;只有在多对服务器同时工作时带宽为3.3Gb/s。所以只需对集群中的核心交换机和边缘交换机的内部互连进行不同的配置就可以灵活的配置出自己满意的集群。这样做的另一个好处是节省客户在整体设备和空间上的投入成本,例如:甲客户在2002年配置了3.3Gb/s CBB的Infiniband网络;2003年需要达到5Gb/s CBB的Infiniband网络,原来的网络设备可以保留,添加相应的交换设备就可以;2005年需要达到10Gb/s的带宽,这时前几年投入的设备依然可以使用。如果客户在一套集群中部分节点需要10Gb/s的带宽,也需要低带宽以降低成本,Infiniband就可以灵活配置满足客户的要求。
2.4. 硬件组成
为了使Infiniband有效地工作,Infiniband标准定义了一套用于系统通信的多种设备,包括信道适配器、交换机、相关线缆和子网管理器。
如图所示:双端口HCA卡
HCA卡--Infiniband信道适配器,信道适配器用于Infiniband结构同其他设备的连接。Infiniband标准中的信道适配器称作主信道适配器(HCA)
HCA提供了一个对Web server等主CPU和存储器子系统的接口,并支持Infiniband结构所定义的所有软件动词(Verb)。这里所说的软件动词是对客户方软件和HCA功能之间接口的一种抽象定义。软件动词并不为操作系统指定API,但它定义了操作系统厂商可能用来开发适用应用程序接口(API)的操作。 
如图所示:24端口Infiniband交换机
Infiniband交换机。交换机是Infiniband结构中的基本组件。一个交换机中的Infiniband端口不止一个,它能根据本地路由器包头中所含的第二层地址(本地ID/LID)将数据包从其一个端口送到另外一个端口。交换机只是对数据包进行管理,并不生成或使用数据包。同信道适配器一样,交换机也需要实现子网管理代理(SMA)以响应子网管理数据包。交换机可通过配置来实现数据包的点播或组播。

Infiniband线缆。Infiniband标准定义了三种链路速率,分别为:1X、4X和12X。此标准也定义了包括铜导线和光纤在内的物理介质。此外,它还定义了用于光纤和铜导线的标准连接器和电缆。铜缆上的1X链路采用四线差分信令(每个方向两线),可提供2.5Gbps的全双工连接。其他链路速率都建立于1X链路的基本结构上,一条Infiniband 1X链路的理论带宽是2.5Gbps。但实际数据速率为2Gbps(因为链路数据采用8b/10b编码)。由于链路具有双向性,所以全双工数据速率为4Gbps。相应的,4X和12X链路的规定带宽为10Gbps和30Gbps。
子网管理器。子网管理器对本地子网进行配置并确保能连续运行。所有的信道适配器和交换机都必须实现一个SMA,该SMA与子网管理器一起实现对通信的处理。每个子网必须至少有一个子网管理器来进行初始化管理以及在链路连接或断开时对子网进行重新配置。通过仲裁机制来选择一个子网管理器作为主子网管理器,而其他子网管理器工作于待机模式(每个待机模式下的子网管理器都会备份此子网的拓扑信息,并检验此子网是否能够运行)。若主子网管理器发生故障,一个待机子网管理器接管子网的管理以确保不间断运行。
HCA卡驱动包:Silverstorm提供统一的,完善的Infiniband驱动软件;同时支持HPC应用和SharedI/O应用;特别是针对大规模机群的应用;其软件在设计上做到性能优化、易于安装和升级;在众多大规模集群得到了性能和操作上得到进一步优化和验证:
HCA 驱动主要包括:
IB Network Stack --àIB access layer和HCA驱动
Fabric Fast Installation --à集群辅助工作
IP over IB Driver --à基于IB的IP协议
MPI --àSilverStorm提供的MPI
MPI Development --àMPI开发包
MPI Source --àMPI原代码
InfiniNic --à基于网关设备以太网和IB网络的转换协议
InfiniFibre --à基于网关设备的FC网和IB网络的转换协议
SDP --à卸载TCP协议的IB本地协议,支持Socket应用
RDS --à卸载UDP协议的IB本地协议,支持原UDP应用
Udapl --àuser Direct Access Provide Library
3. 应用分析
3.1. Fluent应用分析
目前CFD模拟应用是制造业内增长最快的一种应用,fluent是CFD领域里最广泛使用的一种商用软件,用来
模拟从不可压缩到高度可压缩范围内的复杂流动。由于采用了多种求解方法和多重网格加速收敛技术,因而FLUENT能达到最佳的收敛速度和求解精度。灵活的非结构化网格和基于解算的自适应网格技术及成熟的物理模型,使FLUENT在层流、转捩和湍流、传热、化学反应、多相流、多孔介质等方面有广泛应用。
下图描述的是在fluent6.2上进行的千兆以太网络和Infiniband网络的性能对比。
测试环境:
硬件环境:采用的主频2.0G Hz的opteron双核处理器,计算节点为2G内存配置。
操作系统:redhat EL3.0
应用软件:fluent6.2,测试时划分的网格数在3.2万-900万之内。
并行环境:在Infiniband平台上为silverstorm mpi 3.0
在以太网平台上为mpich1.2
测试结果如下图所示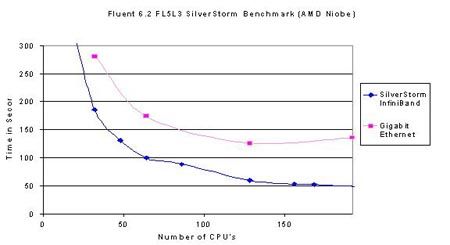
图中横坐标为计算环境中的CPU数量,纵坐标为应用运行所用的时间。由图中可以看出,对千兆以太网(粉色曲线)来说,cluster内处理器未到达128时系统的运行时间会随着处理器的增加而缩短,当处理器逐渐增加,超过128颗CPU后,系统的运行时间并不会继续缩短,而是逐渐趋于稳定,由此可以判断,在千兆以太网环境下,fluent应用的拐点即为128CPU。对Infiniband网络(蓝色曲线)分析:当系统内到达196处理器时还未出现拐点,可以判定,其相对于千兆以太网性能有所增加。纵向比较,当处理器规模为64颗处理器之后,Infiniband网络的性能比千兆网的性能提高的更多:在32处理器时:以太网运行280分钟,Infiniband运行185分钟,性能提升34%;当处理器规模为64时,以太网运行170分钟,Infiniband运行100分钟,性能提升41%;处
理器规模为128时,以太网运行130分钟,Infiniband运行55分钟,性能提升57%。综上可以得知节点规模越
大,采用Infiniband网络的优势越明显,得到的投资回报率才越高。
所以,在应用Fluent时,我们建议:当系统内处理器规模小于64时,采用千兆以太网络更能有效的保护用户投资,当系统内处理器规模较大,建议采用高速Infiniband网络更能发挥整体优势。
3.2. STAR-CD应用分析
STAR-CD的创始人之一Gosman与Phoenics的创始人Spalding都是英国伦敦大学同一教研室的教授。
STAR-CD 是Simulation of Turbulent flow in Arbitrary Region的缩写,CD是computational Dynamics Ltd。是基于有限容积法的通用流体计算软件,在网格生成方面,采用非结构化网格,单元体可为六面体,四面体,三角形界面的棱柱,金字塔形的锥体以及六种形状的多面体,还可与CAD、CAE软件接口,如ANSYS, IDEAS, NASTRAN, PATRAN, ICEMCFD, GRIDGEN等,这使STAR-CD在适应复杂区域方面的特别优势。
STAR-CD能处理移动网格,用于多级透平的计算,在差分格式方面,纳入了一阶UpWIND,二阶UpWIND,CDS,QUICK,以及一阶UPWIND与CDS或QUICK的混合格式,在压力耦合方面采用SIMPLE,PISO以及称为SIMPLO的算法。在湍流模型方面,有k-e,RNK-ke,ke两层等模型,可计算稳态,非稳态,牛顿,非牛顿流体,多孔介质,亚音速,超音速,多项流等问题. STAR-CD的强项在于汽车工业,汽车发动机内的流动和传热
下图描述的是在STAR-CD上进行的千兆以太网络和Infiniband网络的性能对比。
测试环境:
硬件环境:采用的主频2.0G Hz的opteron双核处理器,计算节点为2G内存配置
操作系统:Rocks 3.3.0 (RedHat Enterprise 3)
应用软件:STAR-CD 3.24 & 3.25
并行环境:在Infiniband平台上为ScaliMPI
在以太网平台上为mpich
测试结果如下图所示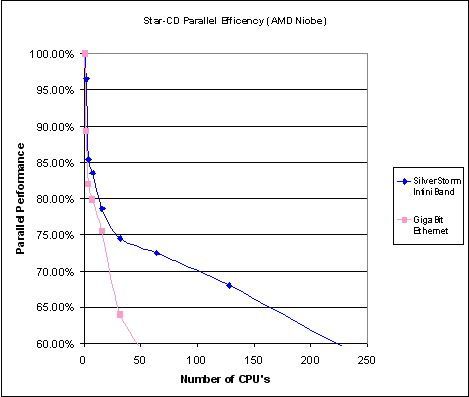
图中横坐标为计算环境中的CPU数量,纵坐标为应用的并行效率。由图中可以看出,对千兆以太网(粉色曲线)来说,它的并行效率很低的,从1颗处理器到48颗处理器,并行效率下降的很快(斜率很大),所以不适合大规模计算。对于高速Infiniband网络(蓝色曲线)来说,在32处理器以下的规模时,并行效率较低,在32至200颗处理器之间的并行效率都较高,所以Infiniband在大规模机群中更能体现其优势。横向分析二者区别:当处理器规模小于16的时候,千兆以太网的并行效率为75%,Infiniband的并行效率为78%,并没有很多的差别,由于高速网的投入会较高于千兆以太网,所以在小于16处理器的时候Infiniband的性价比并不好。
所以,在应用STAR-CD时我们建议:小于16颗处理器的计算平台中采用千兆网络构建,处理器规模在16至32时根据项目资金,可以选择千兆网络或高速Infiniband网络,超过48颗处理器的计算平台采用高速Infiniband网络。
3.3. LS-Dyna应用分析
LS-Dyna是美国livermore公司开发的三维有限元动力分析软件LS-Dyna经历了2D到3D的发展过程。目前的LS-Dyna是3D版。LS-Dyna的求解器最初采用的是显式积分(explicit)在时域内来求解微分方程,其优点是大为减少了存储量,可以适应比用隐式积分更为复杂更为大的问题。其缺点是是条件稳定的,因此必须选择很小的时间步长。目前的LS-Dyna版本中已经增加了隐式求解(NewMark)和振型叠加法,增加了求解自振频率的部分,还增加了一定的静力计算功能。
下图描述的是在LS-Dyna上进行的千兆以太网络和Infiniband网络的性能对比。
测试环境:
硬件环境:采用的主频3.4G Hz的nocona处理器,计算节点为2G内存配置。
操作系统:redhat3.0
应用软件:LS-DynaMPP 970 (Neon_refined and 3 car collision)
并行环境:在Infiniband平台上为sst mpi 3.1
在以太网平台上为intel mpi
测试结果如下图所示
图中横坐标为计算环境中的CPU数量,纵坐标为应用运行所用的时间。由图中可以看出,对千兆以太网(粉色曲线)来说,当处理器规模在32节点之内,运行时间会随着处理器增多而降低,但是超过32处理器后系统反而会性能下降,所以可以得出32处理器是千兆以太网的性能拐点。而且当系统为32处理器时,千兆以太网运行时间为2200秒,Infiniband网络运行时间为800秒,可知高速网络的性能高于千兆以太网络的3倍。12万多特价,单机一万三。硬盘3500,内存一万伍千三,三条。X工程师刘小倩。再分析高速网络:测试规模达到90颗处理器依然没有出现性能拐点,可以断定在该应用中LSDyna的大规模计算时只能选用高速计算网络。继续进行横向分析:在处理器规模小于16时,运行1250秒;当处理器规模为32时,运行800秒,性能提升36%;当处理器规模为64时,运行600秒,性能提升25%;处理器规模为96时性能提升的也很慢。从而得出:在处理器规模增加阿到64个时,性能提升的不再明显。
所以,在应用LS-Dyna时,我们建议:采用高速网络,尤其是在16处理器~96处理器之间时一定要采用高速网络才可达到一定的处理能力。
4. 案例分析
4.1. 气象行业高性能计算机群设计(<24节点)
4.1.1. 项目背景
数值天气预报是现代天气预报的基础,数值天气预报水平的高低成为衡量世界各国气象事业现代化程度的重要标志。我国是世界上受气象灾害影响最严重的国家之一。二十世纪后半叶以来,全球变暖,极端天气气候事件增加,给世界和我国社会经济带来了巨大的负面影响。与此同时我国幅员辽阔,丰富多样的气候资源又给我们提供了很大的开发利用潜力。因此加强防灾减灾、趋利避害,针对极端天气气候事件和气候变化问题,迫切需要做好天气预报、气候预测和气候系统预估工作。
在气象预报的工作中,反应速度已经越来越不能适应社会发展的需要,因此,提高气象预报的准确性和及时性已经迫在眉睫。某某气象局正是顺应当前预报工作中的新问题,准备建立一套先进的高性能计算集群系统,即满足自身的科学研究需要,又为社会各行各业的发展提供了有力的气象保证。
4.1.2. 需求分析
在这套方案设计中,充分满足用户对该系统高效性、兼容性、可管理性和稳定性的要求。其中,高效性表现在系统本身能在用户要求的时间内完成相应的数值预报计算的任务,节点机采用先进的系统架构,网络设备具有高带宽、低延迟的性能。兼容性表现在该系统硬件采用商业化的设备,软件层面对操作系统和数值预报软件的全面兼容。可管理性表现在用户对设备和应用使用简便,方便管理。稳定性表现在系统硬件运行正常,数值预报软件能在硬件平台上高效快速的运行。
4.1.3. 方案设计
方案一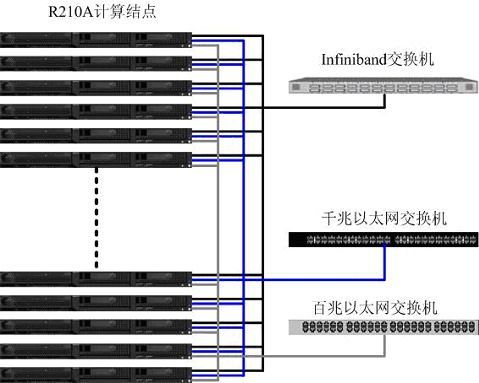
计算节点选择曙光天阔R210A服务器,该服务器采用2路AMD Opteron248处理器,2G内存,73G热插拔SCSI硬盘。I/O节点同样采用R210A服务器,AMD Opteron248处理器,考虑到I/O节点数据存取比较频繁的特点,内存扩展为4G,硬盘扩展为2块146G热插拔SCSI硬盘。I/O节点同时用户登陆节点和管理节点使用。网络方面,采用三网分离的模式。计算网用于并行计算时的数据交换和计算通讯,数值天气预报作为通信密集型计算无论是通信次数还是通信量都很大,对网络的延迟和带宽都有较高的要求。针对这一特点我们采用Infiniband网络作为计算网络,Infiniband技术是采用RDMA传输机制实现了低延迟,高带宽的新型网络标准,满足应用的需要。数据传输网的特点是带宽要求相对较高,但对网络延迟要求并不高,因此选择性能适中的千兆以太网,并通过NFS的方式作为数据共享。而管理网主要是进行一些必要的系统管理、监控、登入等管理,同时又作为数据传输网络的备份,对网络性能的要求不高,因此使用一套百兆网络。采用三网分离的模式可以为各个网络之间提供互为备份的功能,提高了系统的高可用性。
方案二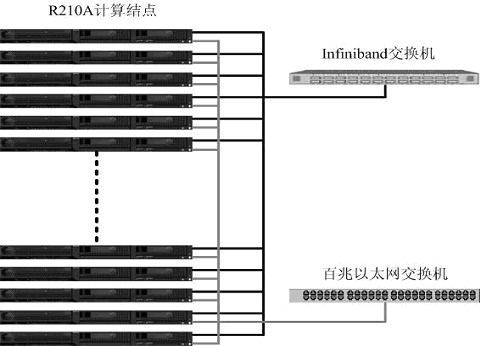
计算节点和I/O节点的选择与方案一相同,主要区别在于对网络的选择,这里计算网络和数据传输网络将实现双网合一,都是建立在Infiniband的高速网络上。对于计算网络是基于Infiniband的本地协议,它在操作系统看来HCA设备就像一个以太网卡一样,这使得TCP/IP应用不用修改就可移植到Infiniband平台环境,完全满足在以太网上的所有应用。而对于数据传输网的NFS共享存储的应用,是基于Inifiniband SDP(Sockets Direct Protoco)协议的NFS over SDP功能模块。SDP协议负责本地Infiniband包的高效通信,采用RDMA文件处理机制,实现了0拷贝,而TCP/IP需要使用buffer进行3次拷贝。在实际应用中,SDP的性能是以太网的6倍左右。
方案中采用Silverstorm公司的24端口交换机IO9024。IO9024交换机内部采用Mellanox InfiniScale-III (Anafa-II)24端口交换芯片;支持24个10Gbps Infiniband端口,背板带宽为480Gbps;交换机只有1U;主要用于搭建24节点以下的集群。
主要特点包括:
* 每个交换机只有1-U,提供24 个 4X Infinband交换端口
* 交换机内部集成了完善的管理软件SMA、PMA、BMA
* 交换机内嵌的子网管理软件FM;通过连接交换机背板上的以太网接口可使用Infiniview和SNMP对交换机端口以及网络结构进行管理、监控
* 模块化、可热插拔的冗余电源和风扇;
* 支持IBTA 1.0 和 1.1标准
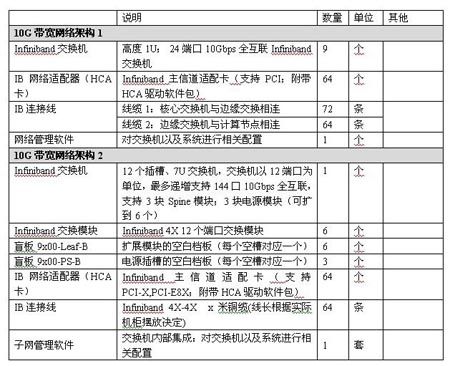
4.1.4. 建议配置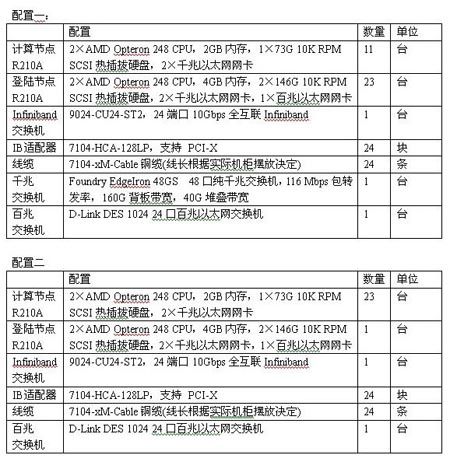
4.2. 气象行业高性能计算及存储方案设计(<24节点)
4.2.1. 项目背景
某某学校的气象学院作为国内气象教学研究的代表,承担着对国内未来气象人才的教学培养工作和天气气侯研究工作,长期以来从事天气预报工作,在国内率先接触和掌握了数值预报模式,并根据我国天气情况、地形地貌特点,开发出适合我国国情的数值预报产品。为了对自行开发的程序进行调试和调优,更好的发挥数值预报软件的功能,使之更好的服务于社会大众,该学院从上级申请了一笔用于购买高性能计算集群的经费,用于数值天气预报的研究和开发工作。
4.2.2. 需求分析
气象学院经费有限,要求所构建的高性能集群具有极高的性价比。在有限的资金使用范围之内,充分满足数值预报工作,达到用户预期的要求。根据分析,我们发现该气象学院在教学和研究任务中,为了保证天气资料实时有效,要求集群计算过程必须在一定的时间内完成,这样对于预报和研究才有意义。另外,用户对气象数据存储的要求也比较高,因为气象资料的数据主要通过卫星接收取得,一次传输的时间较长,必须保证数据的完整性和可靠性。 为了方便教学,需要保存长期的卫星资料,这样才能分析天气的近期变化,以及气候的长期变化这样的一个规律。
4.2.3. 方案设计 
本方案中采用12台曙光R210A服务器,该服务器采用AMD Opteron处理器,提供给用户超强的处理能力,满足了用户对于降低计算时间的要求。在网络方面,采用Silverstorm提供的IO5000交换机,同时连接存储,以太网络和Infiniband网络,实现三网合一的网络连接方式。该交换机提供12个Infiniband接口,同时提供两个扩展槽,一个插槽可以插入VEx卡,实现3个以太网百/千兆的端口接入,另一个插入VFx卡,实现2个2G FC端口的接入。这种三网合一的网络连接方式,简化了网络结构的复杂性、易于管理、降低硬件成本。在存储方面提供了光纤磁盘阵列可直接连接到交换机的FC端口上,实现了光纤存储网络和IB网络的连接。增强了存储数据的安全性,提高了数据传输的速度,为日后存储空间的扩展提供了有力的保证。
4.2.4. 建议配置 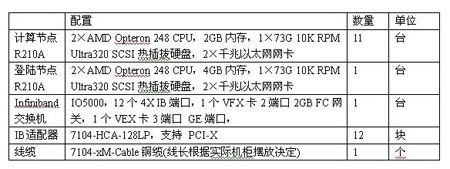
4.3. 流体力学应用计算机群设计(48节点以下)
4.3.1. 项目背景
随着CFD(计算流体力学)逐步在各个行业的深入,CFD商业软件Fluent有很大的发展前景。Fluent已经在航空航天、石油化工、建筑、热能等大领域有广泛应用。支持Fluent等大型CFD/CAE商业软件的并行系统平台的需求随着国民经济发展逐渐提高。
在航天领域fluent可以模拟复杂几何模型的内、外流场。可以进行飞机内外流耦合计算、导弹飞行姿态过程模拟、气动噪音数值模拟、染料箱液体振荡模拟、飞行器部件温度场数值模拟、发动机燃烧室燃烧模拟、火箭喷管模拟、弹道飞行模拟、冷却系统模拟、换热系统模拟等应用。
近年来我国的航空航天技术也已经赶上并超过一些发达国家的研究水平,在对这个领域的进一步探索中,无法完成大规模计算一直制约着前进的步伐,为此,航天三院的研究人员终于明确了一个目标“工欲善其事必先利其器”,加大对科研的投资力度,构建一套较大规模的48节点的高性能计算机群,为新的课题奠定良好的科研环境。
4.3.2. 方案分析
4.3.2.1. 应用分析
首先分析用户应用,该项目中主要应用软件是Fluent。Fluent是目前世界上广泛使用的CFD商用软件,用来模拟从不可压缩到高度可压缩范围内的复杂流动。由于采用了多种求解方法和多重网格加速收敛技术,因而FLUENT能达到最佳的收敛速度和求解精度。灵活的非结构化网格和基于解算的自适应网格技术及成熟的物理模型,使FLUENT在层流、转捩和湍流、传热、化学反应、多相流、多孔介质等方面有广泛应用。Fluent属于比较成熟的商业软件,其应用模式具有很强的代表性。
完整的Fluent计算过程可分为三块:
前端处理(Preprocessing)
计算和结果数据生成(compute an result)
后处理(Postprocessing)
前端处理通常要生成计算模型所必需的数据,这一过程通常包括建模、数据录入(或者从cad中导入)、生成离开格等;做完前处理后,CFD的核心解释器(SOLVER)——Fluent将根据具体的模型,完成相应的计算任务,并生成结果数据;后处理过程通常是对生成的结果数据进行组织和诠释,一般以直观可视的图形形式给出来。其中中间处理的过程是最耗费计算单元的了。
根据上述3.1节可知fluent在普通千兆以太网上的性能加速比很好,在Infiniband上的性能也有相应的提升,但是投入较多,在资金允许的范围内可以考虑采用高速网络作为系统间的通讯介质。
本项目中用户预算比较充裕,而且立项的目的就是为了尽可能快的完成计算任务,要求系统具有48个计算节点的能力。
4.3.2.2. 架构分析
由上文可知,Infiniband的交换机只有24口和144口两种,此谓遗憾,但是由于Infiniband带宽很高,还可以有很多种灵活的搭建模式。可以分为3.3G-10G和5G-10G以及10G全互连的构建方式。
3.3G-10Gb CBB方案: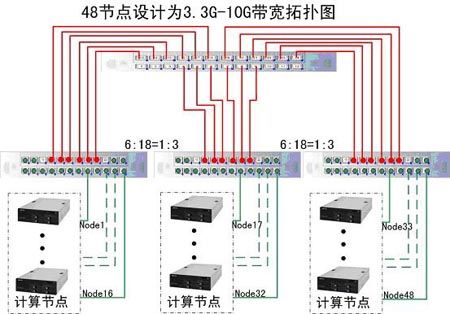
如图所示为3.3Gb/s CBB* 方案
*:CBB (constant bisectional bandwidth):恒定的半分带宽指的是集群内部可用的带宽是恒定的(例如:3.3 Gb/s).
3.3~10Gbps Infiniband解决方案的工作原理:
a. 核心交换模块和边缘交换模块的连线为10Gbps连接
b. 服务器(1、2、3、4、5、6)与交换机的连线全部为10Gbps连接。
c. 当图中6台服务器中仅有1和2通信时;通信带宽为10Gbps。
d. 当图中1和2、3和4同时通信时;最小通信带宽为5Gbps。
e. 当图中1和2、3和4、5和6同时通信时;最小通信带宽为3.3Gbps。
由图中可知,每一个最底层的边缘交换模块还有两个端口属于空余状态,所以此结构图适用于的最大计算节点个数为:18*3=54个,最小计算节点个数为:37个。即:该逻辑拓扑结构图适用性为:37~54个节点的3.3G~10Gb的高速交换架构。
5G-10Gbps方案:
如图所示为5Gb/s 方案,可以看出与3.3~10Gbps 的架构类似
5~10Gbps Infiniband 与3.3~10Gbps Infiniband解决方案的工作原理:相同
a. 核心交换模块和边缘交换模块的连线为10Gbps连接
b. 服务器(1、2、3、4)与交换机的连线全部为10Gbps连接。
c. 当图中4台服务器中仅有1和2通信时;通信带宽为10Gbps。
d. 当图中1和2、3同时通信时;最小通信带宽为5Gbps。
由图中可知,每一个最底层的边缘交换模块均已占用,所以此结构图适用于的最大计算节点个数为:16*3=48个,另观察可知最小计算节点个数为:33个。即:该逻辑拓扑结构图适用性为:33~48个节点的5G~10Gb的高速交换架构。
10Gbps全互联的 FBB方案: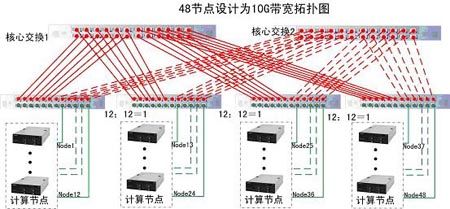
如图所示为10Gb/s 方案,可以看出与5~10Gbps的架构有很多不同
10Gbps Infiniband的工作方式属于标准的全互联工作方式:每个边缘交换模块只有12个端口用于连接计算节点,其余12个端口中一半的端口用于连接核心交换模块1,另一半用于连接核心交换模块2,如此保证从node1至node48均可达到10G的带宽。
由图中可知,欲达到每个节点之间的交换带宽均为10G则每个交换机只可连接12个计算节点,所以此结构图适用于的最大计算节点个数为:12*4=48个,若上图中的边缘交换模块为三个,则最大连接节点的个数为12*3=36个。即:该逻辑拓扑结构图适用性为:37~48个节点的10Gb的高速交换架构。
架构分析:
观察上述三种逻辑图:该项目为48节点的高性能计算系统,3.3G与5G的图中区别仅仅是在5G的结构中多了两条线缆连接,线缆的投资相对很小,所以建议该项目不必考虑3.3G连接方式,在投资允许的范围内选择5G连接架构或10G连接架构。
4.3.2.3. 扩展性分析
集群硬件升级方案:
注:
集群规模扩容(48节点升级到54节点):只需要增加6块HCA卡和6根线缆
集群带宽扩展(3.3Gbps升级到10Gbps全互联):只需要增加2台IO9024和30根线缆就可扩展到48节点的10Gbps全互联。
集群软件的升级:所有产品使用一套软件,保证客户使用Infiniband产品的易用性和一致性;当软件新版本推出后,使用集群安装辅助工具能够快速的实现整个网络的IB环境升级,保持客户集群软件平台的先进性和高性能。
4.3.3. 建议配置 
4. 有限元分析计算机群设计(64节点)
4.4.1. 项目背景
中科院某所是以进行广泛的物质科学领域的计算和模拟研究为主要研究方向的研究所。还兼有开发新的计算技术和计算模拟方法的任务。对新方法的发展,包括从微观到宏观,从单体到多体系统,从经典到量子,从常温常压到极端条件等等领域的不同范畴不同尺度的计算模拟新方法,涉及到材料、能源、信息、 生物、环境等领域,及物理、数学、化学、生物、计算机科学等学科。不仅如此,中心还承担着国家相关研究课题,主要体现在物理科学的模拟与计算、国内核心“物质模拟机”的研究运用和成为代表国家水平的开放中心上。
由于中心进行的项目多、复杂,往往多种应用程序要并行、串行, 而且CPU、RAM、存储需求都很大。运用普通的超级计算机,模拟程序一旦运行,就会产生内存不够等问题,往往严重影响甚至阻滞了科研的发展。因此,中心的科研急需利用更先进的信息技术和计算机设备来提高数据处理、计算的能力。
目前中心常用的软件包括LS-Dyna、VASP等很成熟的商业软件,应用范围比较广泛,8个研究室都要在一年内完成相关课题,研究任务必将繁重。虽然对计算的需求很大,但每个研究室并没有充裕的资金和力量构建具一定规模的计算平台,所以经过协商,采用“联手”的方式构建较大规模的计算平台,如此可以节省重复劳动、降低管理费用。经讨论,构建一套64节点的高性能计算平台,平时每个实验室可以使用其中的一部分(8台),如需要更多的资源可以跟管理人员提出申请,进行大规模计算。目前暂定主要应用软件为LS-Dyna,若以后还有相关深入研究,则根据实际情况,增加其它软件的支持。
4.4.2. 方案分析
4.4.2.1. 应用分析
该项目用于LS-Dyna的应用。LS-DYNA 是世界上最著名的通用显式动力分析程序,能够模拟真实世界的各种复杂问题,特别适合求解各种二维、三维非线性结构的高速碰撞、爆炸和金属成型等非线性动力冲击问题,同时可以求解传热、流体及流固耦合问题。在工程应用领域被广泛认可为最佳的分析软件包。与实验的无数次对比证实了其计算的可靠性。
根据上文3.3分析,LS-Dyna应用在千兆以太网络时的并行加速比并不是很好,尤其是到了16颗CPU,若采用高速网络,并行加速比得到了大大的提升,所以该项目中非常建议用户采用高速Infiniband网络构建系统。
4.4.2.2. 架构分析
Infiniband网络有其高效的一面,但也有其复杂的一面,或者可以称其为灵活性很强。本项目中要构建一套64节点的高速网络既可以通过普通的24口交换机搭建也可以直接选用144口的大规模交换机,节省了布线难度。
10G全互联的网络构架一:
如图所示:该结构是通过标准24口交换机搭建起来的10G网络系统,为了达到互联的目的,每个交换机只可连接12个计算节点,所以此结构图适用于的最大计算节点个数为:12*6=72个,即:该逻辑拓扑结构图适用性为:61~72个节点的10Gb的高速交换架构。
但仅仅通过拓扑图即可以看出该网络环境极为复杂,各个交换机交叉会有很多联系,如此在项目实施的时候会比较困难,除非有比较有经验的工程实施人员,而且整体系统在短期内不会发生变更才建议选用这种方式。
10G全互联的网络构架二:
上文曾经介绍过,Infiniband还有一种模块式最大可达144口的交换机,该交换机属于InfinIO9120模块化交换机,高度只有7U,支持12个扩展插槽、每个插槽内可以插入12端口IB扩展模块。InfinIO9120交换机具备很高的可靠性,每一款交换机都配备冗余的管理、电源和风扇;交换机的内部软件可以很方便的升级。InfinIO9120交换机同样采用silverstorm公司开发的Infiniview管理软件对交换机进行管理和配置;保证用户对silverstorm产品使用时感到一致;一台InfinIO9120交换机可最大支持144个节点,以12节点为单位进行递增,具有很高的灵活性和可扩展性。
IO9000系列交换机的扩展插槽中可供选择的模块:
12-端口4X (10Gb/s)Infiniabnd交换模块。
64节点两种方案对比:
采用多个24端口的交换机IO9024搭建,使用交换机较多,工程实现的难度稍大一些。但易于拆卸,使用方便。
采用IO9120,通过插入12端口的模块进行扩展机群规模,操作简单;另外可以通过插入SPINE核心交换模块,来搭建3.3,6.6,10Gbps的解决方案,非常灵活。
4.4.2.3. 扩展性分析
集群规模的扩容:一台IO9120交换机最多可以支持144端口10Gbps Infiniband连接,同时IO9120交换机支持与silverstorm其它交换机的堆叠,实现集群规模的扩容。
软件的简便升级:当软件新版本推出后,使用快速安装工具能够快速的实现整个网络的IB环境升级。
4.4.3. 建议配置