Ubuntu下caffe:用自己的图片训练并测试AlexNet模型
目录
1.准备图片
2. 将 图片路径写入txt
参考 这篇文章
3.转换格式
还是参考这篇文章
4.训练模型
参考这篇
参考这篇
参考这篇
5.测试模型
看过这篇转换均值文件
看过这篇
—————————————————————————————正文——————————————————————————————————————
1.准备图片
在data下新建文件夹myself ,在myself文件夹下新建两个文件夹 train和val。
train用来存放 训练的图片,在train文件夹下新建两个文件夹0和1 。图片有2类,包包(文件夹0)和裤子(文件夹1),每类55种。
Tips:大家从网上找的图片可能命名不规范,身为强迫症当然无法忍受了,一个一个修改太麻烦。
我分两步重命名图片:
第一,在每个图片名字前面加上类别名,这样就会规整很多 ;
rename 's/^/bag/' *第二,把jpg的后缀改为jpeg,别问我为啥,小白看别人这么做,我也这么做了。
rename 's/.jpg $/.jpeg/' *
val 用来放训练过程中用来验证的图片(来计算准确率),val中的图片和train中的不一样。我这里放了15张包包和15张裤子。只将图片后缀重命名了一下。

2. 将 图片路径写入txt
在data/myself/中新建train.txt 和val.txt
需要将图片的路径以及标签都写进去,包包标签为0,裤子标签为1
① 写入路径
find -name *jpeg | grep train | cut -d / -f 3-4 > train.txt
find -name *jpeg | grep val | cut -d / -f 3 > val.txt
sed -i "1,55s/.*/& 1/" train.txt # 1~55是裤子,标签为1
sed -i "55,110s/.*/& 0/" train.txt # 55~110是包包,标签为0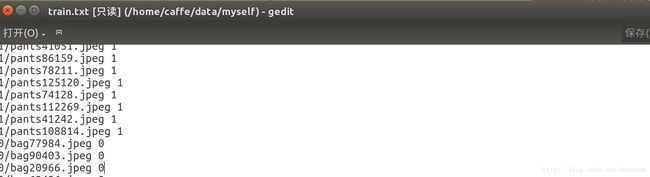
3. 转换数据
在caffe/example目录下新建目录myself。并将caffe/examples/imagenet 目录下create_imagenet.sh文件拷贝到myself中。
注释里是需要改的地方
EXAMPLE=examples/myself #这里修改为自己的路径
DATA=data/myself # 修改为自己的路径
TOOLS=build/tools
TRAIN_DATA_ROOT=/home/caffe/data/myself/train/ # 修改为自己的路径
VAL_DATA_ROOT=/home/caffe/data/myself/val/ #修改为自己的路径
# Set RESIZE=true to resize the images to 256x256. Leave as false if images have
# already been resized using another tool.
RESIZE=true #这里一定要改成true!!!!!!
if $RESIZE; then
RESIZE_HEIGHT=256
RESIZE_WIDTH=256
else
RESIZE_HEIGHT=0
RESIZE_WIDTH=0echo "Creating train lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$TRAIN_DATA_ROOT \
$DATA/train.txt \
$EXAMPLE/myself_train_lmdb #把这里改成自己命名的数据库
echo "Creating val lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$VAL_DATA_ROOT \
$DATA/val.txt \
$EXAMPLE/myself_val_lmdb #这里也改一下
返回caffe根目录 运行 sh ./examples/myself/create_imagenet.sh
接下来就会在examples/myself 下生成 两个文件夹 myself_train_lmdb和 myself_train_lmdb
4. 训练数据
把caffe/models/bvlc_reference_caffenet中所有文件复制到caffe/examples/myself文件夹中
① 修改train_val.prototxt
#data/myself文件夹下myimagenet_mean.binaryproto没有这个文件,把data/ilsvrc12下的imagenet_mean.binaryproto复制到该文件夹下,并重命名为myimagenet_mean.binaryprotoname: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "data/myself/myimagenet_mean.binaryproto"
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size: 227
# mean_value: 104
# mean_value: 117
# mean_value: 123
# mirror: true
# }
data_param {
source: "examples/myself/myself_train_lmdb"
batch_size: 256
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 227
mean_file: "data/myself/myimagenet_mean.binaryproto"
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size: 227
# mean_value: 104
# mean_value: 117
# mean_value: 123
# mirror: false
# }
data_param {
source: "examples/myself/myself_val_lmdb"
batch_size: 50
backend: LMDB
}
}
------------------------------往后拉,在最后----------------------------------------------------
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2 #改这里,图片有几个分类,就写几
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
test_iter: 1000是指测试的批次,我们就10张照片,设置10就可以了。 test_interval: 1000是指每1000次迭代测试一次,我改成了10。 base_lr: 0.01是基础学习率,因为数据量小,0.01就会下降太快了,因此改成0.001 lr_policy: “step”学习率变化 gamma: 0.1学习率变化的比率 stepsize: 100000每100000次迭代减少学习率 display: 20每20层显示一次 max_iter: 4000最大迭代次数, momentum: 0.9学习的参数,不用变 weight_decay: 0.0005学习的参数,不用变 snapshot: 10000每迭代10000次显示状态,这里改为1000次 solver_mode: GPU末尾加一行,代表用GPU进行

③ 图像均值
减去图像均值会获得更好的效果,所以我们使用tools/compute_image_mean.cpp实现,这个cpp是一个很好的例子去熟悉如何操作多个组建,例如协议的缓冲区,leveldbs,登录等。我们同样复制caffe-maester/examples/imagenet的./make_imagenet_mean到examples/myself中,将其改名为make_myimagenet_mean.sh,加以修改路径。
#!/usr/bin/env sh
# Compute the mean image from the imagenet training lmdb
# N.B. this is available in data/ilsvrc12
EXAMPLE=/home/caffe/examples/myself
DATA=/home/caffe/data/myself
TOOLS=/home/caffe/build/tools
$TOOLS/compute_image_mean $EXAMPLE/myself_train_lmdb \
$DATA/myimagenet_mean.binaryproto
echo "Done."拷贝examples/imagenet目录下的train_caffenet.sh文件到example/myself目录下。
#!/usr/bin/env sh
./build/tools/caffe train \
--solver=examples/myself/solver.prototxt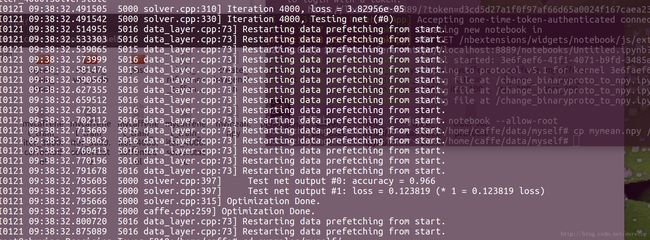
我电脑快,训练了十分钟左右就好啦(默默炫耀一下。。。)出现 【Restarting data prefetching from start.】的提示不要慌,因为图片太少,又从第一幅图片开始训练了。哈哈,我的精确率0.996 还是挺高的。
5 . 测试数据
① 找一个你要测试的图片,我找了一个想买但买不起的包包的图片。。
。。
②修改deploy.prototxt 并编写一个labels.txt
deploy.prototxt 修改一个地方
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
inner_product_param {
num_output: 2 #改成2
}
}bag
pants② 打开data/myself 将myimagenet_mean.binaryproto 转换成 mymean.npy
打开jupyter写个python
import caffe
import numpy as np
proto_path='myimagenet_mean.binaryproto'
npy_path='mymean.npy'
blob=caffe.proto.caffe_pb2.BlobProto()
data=open(proto_path,'rb').read()
blob.ParseFromString(data)
array=np.array(caffe.io.blobproto_to_array(blob))
mean_npy=array[0]
np.save(npy_path,mean_npy)③用Python写代码对 包包图片 分类
import caffe
import sys
import numpy as np
caffe_root='/home/caffe/'
sys.path.insert(0,caffe_root+'python')
caffe.set_mode_cpu()
deploy=caffe_root+'examples/myself/deploy.prototxt'
caffe_model=caffe_root+'examples/myself/mycaffenet_train_iter_1000.caffemodel'
img=caffe_root+'examples/myself/pinko.jpeg'
labels_name=caffe_root+'examples/myself/labels.txt'
mean_file=caffe_root+'examples/myself/mymean.npy'
net=caffe.Net(deploy,caffe_model,caffe.TEST)
transformer=caffe.io.Transformer({'data':net.blobs['data'].data.shape})
transformer.set_transpose('data',(2,0,1))
transformer.set_mean('data',np.load(mean_file).mean(1).mean(1))
transformer.set_raw_scale('data',255)
transformer.set_channel_swap('data',(2,1,0))
image=caffe.io.load_image(img)
net.blobs['data'].data[...]=transformer.preprocess('data',image)
out=net.forward()
labels=np.loadtxt(labels_name,str,delimiter='\t')
prob=net.blobs['prob'].data[0].flatten()
top_k=net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1]
for i in np.arange(top_k.size):
print top_k[i],labels[top_k[i]],prob[top_k[i]]下面是结果: 完美 O(∩_∩)O
