整理归纳在Python中使用对数据处理的常用方法,包括与HDFS文件的读写,主要是怕用的时候记不住,容易搞混,再搜也不爽,好记性不如烂笔头,写下来自己用的时候方便看,而且写一遍也加深印象。
随查随用随更新
Numpy
ndarray
ndarr1 = np.array([ [1, 2, 3], [4, 5, 6] ])
shape 大小和形状
dtype 数据类型
astype 显式的转换类型
不同大小的ndarray也可以运算,称之为广播,比如arr * 2
一维:用[x]进行索引,用[x:y]进行切片,都是原始数组的视图
多维:[x][y]或者[x,y]索引,[x1:x2, y1:y2]切片。
布尔型可以直接做索引
按轴进行布尔类型list的索引,或者对每个元素进行单个布尔索引,比如data1[data1 > 0] = 0
花式索引行和列
arr[ [行1, 行i] ][ :, [列1, 列i] ] 或者
arr[ np.ix_( [行1, 行i], [列1, 列i] ) ]
而且花式索引总是复制数据到新的数组中,不是切片那种原始数组的视图
arr.T 转置
通用函数
np.sqrt(arr) arr的开平方
np.exp(arr) arr的e的x次方
np.abs(arr) arr的绝对值
np.square(arr) arr的平方
np.log(arr) ln(arr)
np.log10(arr) log10(arr)
np.isnan arr的各个元素是否为NaN的bool数组
np.add(arr1, arr2) arr1 + arr2
np.subtract(arr1, arr2) arr1 - arr2
三元表达式
np.where(cond, xarr, yarr) 等价为 xarr if cond else yarr
统计
arr.sum(axis=?) 按照轴的方向求和
arr.mean 按照轴的方向求平均值
arr.min()和max() 最大和最小值
arr.argmin()和argmax() 最大和最小值的索引
arr.cumsum() 所有元素的累计和
arr.cumprod() 所有元素的累计积
排序
np.sort(arr)和arr.sort(),前者是顶级方法,返回对arr排序后的副本;后者则是直接对arr排序。
线性代数
包括矩阵的点乘,矩阵分解以及行列式等等。
点乘:xarr.dot(yarr)等价于np.dot(xarr, yarr)
numpy.linalg中有一组标准的矩阵分解运算以及诸如求逆和行列式之类。比如如下部分:
diag([一维数组]) 对角矩阵,对角线是输入的一维数组
dot 点乘
det 计算矩阵的行列式
inv 计算矩阵的逆
qr 计算QR分解
svd 计算奇异值分解(SVD)
Pandas
(官网)https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html
官网Pandas的API汇总
官网10分钟对Pandas的简介
Series
可以把Series看成是一个有序的定长字典。
ser = Series([1, 2, 3, 4], index=['d', 'b', 'a', 'c'])
经常存在与DataFrame的行与列中。
也可以直接从字典类型的对象中构建。
idx_val_map = {'d':1, 'b':2, 'a':3, 'c':4}
ser = Series(idx_val_map, name='值的名称')
ser.index.name = '索引的名称'
ser['a']进行索引
再进一步,比如对于二维的DataFrame,取其中一列出来,就是Series,它的name就是这一列的名字,它的index就是DataFrame的index,index的name就是DataFrame中作为index的那一列的名字。
DataFrame
DataFrame的索引是不可更改的。可以添加和删除,但是不能修改。
- 构造DataFrame
1.由二维ndarray构造,可以给出行标和列标
2.由字典构成,外层字典key是列标,内层字典是行标result1 = pd.DataFrame([[1, 0.7], [0, 0.7]], index=pd.Index([135, 136], name='Number'), columns=['Gender', 'Prob'])
需要注意的是字典构成的df,需要指定column的顺序,否则默认会按照列的字符串名排序
predict_df = pd.DataFrame(data={'svc_y': svc_y, 'dnn_y': dnn_y, 'xgb_y': xgb_y, 'rf_y': rf_y}, columns=['svc_y', 'dnn_y', 'xgb_y' ,'rf_y'])
3.由另一个DataFrame构成
有时候会有一种需求是从已经有的DataFrame中创建一个空的Dataframe但是使用的是原来这个Dataframe的结构。
copy_df = pd.DataFrame.from_items([(name, pd.Series(data=None, dtype=series.dtype))
for name, series in original_df.iteritems()])
-
添加列
frame['new-col'] = value # 需要添加多列时比较特殊点需要借Dataframe来赋值 frame[['new-col1', ..., 'new-coln']] = pd.Dataframe(np.random.randint(1,5,[n_rows, n]), index=frame.index) -
添加行
s = pd.Series({'Col1':'Value1', 'Col2': 'Value2', 'Col3': Value3}) # 构造一行新数据 frame.append(s) -
删除列
del frame['col-name'] -
删除行
# 因为DataFrame是列索引的(在frame.items()返回值中可以看出来)所以del只能删除列,删除行需要用到drop方法 frame.drop(frame.index[[1,3]]) -
索引方式
列索引:frame['col_name']或者frame.col_name
行索引:frame.ix['row_name']
点索引:frame.at[行,列] 或者frame.iat[行i,列i],只能索引具体的元素,不能切片
用整数位置索引frame.iloc[index(列表), col-index(列表)]
ix[行, 列]和iloc[行, 列]都可同时索引行与列,区别在于ix用的是名字(当DataFrame的index没有设置时,退化成iloc),iloc用的是整数位置
loc: works on labels in the index.
iloc: works on the positions in the index (so it only takes integers).
ix: usually tries to behave like loc but falls back to behaving like iloc if the label is not in the index.- 总结
['col-name']——是对列的索引
[ ['col-name1', 'col-name_i'] ]——两个[]是对多个列的索引
[bool类型list]或者[i:j]——是对行的切片索引
ix[行,列]——支持对行和列同时索引和切片(loc和iloc参考上面)NOTE:ix操作如果有左值,那么就默认会copy,如果没有左值那么就是对原始Frame进行操作,而loc和iloc默认都是对原始Frame的操作,所以推荐使用loc,如果需要复制,可以显式的调用Frame.copy(). 不过仍要注意的是frame2 = frame1.loc[a:d, :]确实不是复制是对原frame1的切片,但是frame1.loc[ [a, b, c, d], :]则是复制不是切片了。
at[行,列]和iat[i,j]——是定位到元素
所以对列的bool类型list切片应该用ix[:,bool_list],然而对行的bool类型list切片可以直接[bool_list]
- 总结
-
基本功能
重新索引
reindex,对索引重新排序,新加的使用缺失值填充。丢弃指定轴上的项
frame.drop(['name'], axis=?)切片
frame[:2] 这个是直接按行切片,和常识有点不太一样,但是方便实际操作。
frame[ ['列1', '列i'] ],这个是按列切片过滤
按照某一列的值过滤:frame[ frame['列'] > 5 ]
对于bool类型的list,除了上面的方法,也可以frame.loc[bool_list_X, bool_list_Y]进行过滤。算术运算
frame1 + frame2 或者 frame1.add(frame2, fill_value=0)
sub做减法 div是除法 mul是乘法-
函数应用和映射
Numpy的ufuncs也可用于操作pandas对象np.abs(frame)
还可以自定义函数(列或行的):
f = lambda x: x.max() - x.min()
frame.apply(f, axis=?)对元素的函数
format = lambda x: '%.2f' % x
frame.applymap(format)featQuant = sampleDF_feat.quantile(0.999) # 获得0.999的分位数
frameFeatUnderQuant = sampleDF_feat.where(sampleDF_feat <= featQuant, other=0) # 把异常高的数值排除掉总的来说,DataFrame可以用的是apply和applymap,Series可以用的是map:
apply:是对DataFrame的具体行或者列进行整体操作。比如可以取最大最小值
applymap:是对DataFrame的具体每个元素进行操作。
map:也是对每个元素进行操作,和applymap类似。 排序
frame.sort_index(by='name', axis=?, ascending=True)
-
汇总和计算描述
frame.sum(axis=?, skipna=True) 求和
frame.mean() 平均值
frame.count()
frame.min、max
frame.argmin、argmax 整数索引位置
frame.idmin、idmax 名字ID索引位置
frame.quantile() 计算样本的分位数(0到1),比如frame['col_name'].quantile([q/10 for q in range(1, 11, 1)])
frame.describe() # 描述各个列的详细统计信息
frame.info() # 描述各个列是否有缺失值和dtype
frame['col_name'].value_counts() # 计算得到col_name列上各种取值的个数- groupby
这个操作是对数据做聚合后的操作。
比如df['col1'].groupby(by=某种依据),就是在df的'col'列上按照某种依据来聚合,产生一个DataFrameGroupBy对象。这里的某种依据就是告诉pandas在聚合时哪几个数据属于一类的,比如df的行数为7,那么某种依据为['c','s','t','t','s','s','c'],会把第一行和最后一行归在一起,第2\5\6行归在一起,第3\4行归在一起。
此时可以使用mean(),sum(),apply()这样的操作来得到想要的值。当对df['col1']做groupby时得到的每一项是Series,此时apply(lambda x: ...)中的x是Series类型;当对df[['col1',...,'colN']]做groupby时得到的是Dataframe,此时apply(lambda x: ...)中的x是DataFrame类型。
比如对df['cnt']表示某个用户购买某个物品的个数,我们想得到每个用户各自购买物品占自己购买总数的比值时:df['cnt'].groupby(df['user_name']).apply(lambda cnts: cnts.apply(lambda n: n / cnts.sum()))
另外df.groupby(...).agg(func)是指对df做group之后对每一列执行func,如果不需要对每列执行,则直接使用apply即可。agg的详细示例见:官网agg - melt
这个是让df按照指定的列消融,比如df有3列,直接melt(),会得到新的melt_df由index, variable, value这三个列组成,其中index的范围是原来的3倍,variable是原来的列名,value是原来对应列的值。
melt()函数有几个参数:id_vars='不消融的列', value_vars=消融的列list, var_name='消融后variable的名字', value_name='消融后value的名字'
- groupby
-
处理缺失数据
frame.dropna() 丢弃NaN,可以给出阈值进行调节容忍度
df.fillna( {'列1': 值1, '列i': 值i}, inplace=True ) 默认返回一个新的对象
frame.isnull() 返回与frame一样大小的布尔值对象(值为NaN的为True,否则为False) -
其他常用
# 去重 df.duplicated(keep='first') # 这个会返回列的值重复与否的布尔值,默认对于重复值的第一个为False,其他重复的为True # 得到这个布尔后可以再进行切片去重,不过还有更便捷的方法: df['某列'].drop_duplicates(keep='first', inplace=True) # 这样直接得到去重后的结果。 -
从文件中读取
frame = pd.read_csv('file.csv', names=col_names, index_col='col_index')
另外说下,如果csv的文件中是这样的0,1,2,"string:\"(1,2)\"",那么上面在读的过程中会有问题,多读出一列,需要加上参数escapechar="\\",也就是:
frame = pd.read_csv('file.csv', names=col_names, index_col='col_index', escapechar="\\")
除了读取本地文件还可以读取HDFS文件:首先需要安装需要的包:pip install hdfs 官网文档
然后代码中:from hdfs import Client from hdfs import HdfsError client = Client('http://name_node.url:50070') # 输入要链接的NameNode地址。如果是高可用的模式,会有多个name node,那么有个比较笨的方法就是挨个试,看看那个可用(也就是处于active状态)就用哪个。 print(client.list('/')) # 可以在这里添加try操作,catch到异常后去尝试下一个name node的链接。 try: with client.read('path/file.csv') as hdfs_in_fs: predictDF = pd.read_csv(hdfs_in_fs, names=predict_cols, index_col='Number') except HdfsError as e: print(e) -
将Frame写入文件
frame.to_csv(path_or_buf='path/file', index=True, header=False, sep='|')
写入HDFS文件会有些麻烦,一是写的时候需要权限,把要写入的目录设置为hdfs dfs -chmod -R 777 write_Dir;二是写入文件会遇到TypeError: a bytes-like object is required, not 'str',因为不像普通的文件可以在open的时候设置mode参数,所以还需要做如下操作:from hdfs import Client from hdfs import HdfsError client = Client('http://name_node.url:50070') # 输入要链接的NameNode地址。如果是高可用的模式,会有多个name node,那么有个比较笨的方法就是挨个试,看看那个可用(也就是处于active状态)就用哪个。 print(client.list('/')) # 可以在这里添加try操作,catch到异常后去尝试下一个name node的链接。 try: with client.write('path/file' overwrite=True, encoding='utf-8') as hdfs_out_fs: # 需要设置encoding不然遇到上面说的TypeError predictDF[['Gender', 'Prob']].to_csv(path_or_buf=hdfs_out_fs, index=True, header=False, sep='|') except HdfsError as e: print(e) -
另外一种读写HDFS文件的方法
上面的代码确实可以读写HDFS文件,不过需要修改权限,这会出现下面情况: 可以看到为了允许读写,上级目录已经将权限更改为全部可读写执行了,而且新创建的文件夹和文件都是用户dr.who
可以看到为了允许读写,上级目录已经将权限更改为全部可读写执行了,而且新创建的文件夹和文件都是用户dr.who
这会给后续操作带来一定的麻烦,比如yarn用户在程序中对这个文件无法修改。因为只有读权限。
不过还有一个API可以在python中使用,如果你的HDFS配置支持非安全的HttpFS的话。 Client API介绍
Client API介绍上面的使用Client的API是用的WebHDFS。连接的时候需要指定namenode,而在高可用的模式情况下,可能要多试几次才知道当前哪个node处于active状态。为了避免这两个问题,接下来展示另外一个API InsecureClient来实现。在接下来的代码中,使用的是HttpFS方式来读写HDFS
from hdfs import InsecureClient client = InsecureClient('http://HttpFS_node.url:14000', user='yarn') # 使用HttpFS所配置的角色主机域名及REST 端口 print(client.list('/')) # 无需像之前一样多次尝试当前输入的namenode是否可用 with client.read('path/in_file') as hdfs_in_fs: with client.write('path/out_file', overwrite=True, encoding='utf-8') as hdfs_out_fs: sampleDF = pd.read_csv(hdfs_in_fs, names=, index_col=) sampleDF.to_csv(path_or_buf=hdfs_out_fs, index=True, header=False, sep='|')这个API的好处是:1、不需要修改权限,由参数的指定用户保证权限没问题。2、新写入的文件权限也无问题。3、可以支持远程读写,无需在集群上执行,在本地PC上运行即可。4、无需知道当前active的namenode是哪个,可以通过HttpFS主机直接连接。
 新建的文件都是用户yarn的
新建的文件都是用户yarn的 -
合并数据集
- pandas.merge
根据一个或多个键将不同的DataFrame中的行连接起来。类似SQL的关系型数据库的连接操作
简单说就是将多个DataFrame按照指定的各自的列以某种方式(inner,left,right,outer)组合起来。
除了pd.merge还有frame_left.join(frame_right)这个方式
其中join和merge的区别如下:
left.join(right, on='col_name') #是将left的col_name列和right的index进行比较连接,且默认how='left' left.merge(right, on='col_name') #是将left和right共有的col_name列进行比较连接,且默认how='inner' # 不过如果right中如果没有col_name列,那么还是会和join一样会拿index来连接. # 另外merge还提供了left_on/right_on/left_index/right_index这些参数供选择- pandas.concat
沿着一条轴将多个对象堆叠在一起
比如将两个frame的行数据堆叠起来。
frame_total = pd.concat([frame1, framei], axis=?, keys=['col1_name', 'coli_name']) - 举栗
合并Series到Dataframe中:purchase_1 = pd.Series({'Name': 'Chris', 'Item Purchased': 'Dog Food', 'Cost': 22.50}) purchase_2 = pd.Series({'Name': 'Kevyn', 'Item Purchased': 'Kitty Litter', 'Cost': 2.50}) purchase_3 = pd.Series({'Name': 'Vinod', 'Item Purchased': 'Bird Seed', 'Cost': 5.00}) df = pd.DataFrame([purchase_1, purchase_2, purchase_3], index=['Store 1', 'Store 1', 'Store 2']) s = pd.Series({'Name':'Kevyn', 'Item Purchased': 'Kitty Food', 'Cost': 3.00}) s.name = 'Store 2' # 合并s到df中 # 方法1,使用concat函数 df = pd.concat([df, s.to_frame().T]) # 方法2,使用append df = df.append(s)
- pandas.merge
-
打印DataFrame
打印DataFrame非常简单直接print就可以了,但是Pandas对于显示的行数、列数、宽度和长度都有默认限制,如果不期望看到...这样的省略号,或者不期望换行,那么可以如下设置:
在最近的pandas版本中,已经没有display.height这个参数了,其值可由display.max_rows自动推断得到。pd.set_option('display.height',1000) # 把1000换成None即为无限制,下面均是如此。 pd.set_option('display.max_rows',500) pd.set_option('display.max_columns',500) pd.set_option('display.width',1000)上面的设置完之后会对后面的代码全部做这个配置处理,如果想在代码中动态的改变,还可以这么写:
with pd.option_context('display.max_rows', None, 'display.max_columns', None, 'display.width', None): logging.info('输出打印DataFrame:\n{}'.format(data_frame))这样在需要长显示的时候套上with就可以了,不需要的地方继续使用pandas的默认设置。
pandas的通用功能(官链)
pandas提供了很多general function来支持很多数据操作。比如上面提到过的pandas.melt还有其他经常用到的pandas.concat, pandas.merge, pandas.unique等,下面会介绍一些其他常用的功能:
pd.cut
我们有时会需要把连续数值转换为类别,比如根据取值的大小按照某种分隔标准来划分成类别。
更明确些,我们可能有两种划分依据,在pandas中均能找到对应的函数:1、按照取值来划分,比如某个特征取值从0到1,我们希望按照这个取值范围分成3等份,那么就可以用pd.cut;2、按照统计的个数来划分,比如根据样本在这个特征上的取值所统计的个数,分为好中差三个等样本个数的分类,这时可以用pd.qcut;
下面简单介绍下几个常用参数
pd.cut(x=连续取值的数据, bins=整数N(会自动按照上下限的取值份N等份)/数组(会按照数组指示的间隔来划分), labels=划分后的标记)
比如X的取值是0到1,希望按照(0, 0.25](0.25, 0.5](0.5, 0.75](0.75, 1]划分成4份,且对应的label分别是1到4:
pd.cut(X, bins=[i*1.0/4 for i in range(0, 4+1)], labels=range(1,4+1))-
pd.qcut
介绍几个常用的参数
pd.cut(x=连续取值的数据, q=整数N(会自动按照统计分位数分N等份)/数组(会按照数组指示的间隔来划分), labels=划分后的标记)
比如q = [0, .25, .5, .75, 1.] for quartiles
pd.qcut(range(5), 3, labels=["good", "medium", "bad"])... [good, good, medium, bad, bad] Categories (3, object): [good < medium < bad] pd.get_dummies
这个是对类别特征做one-hot编码,比如pd.get_dummies(df, columns=df.columns)
但是有个点需要注意下,比如现在有训练集和测试集,其中训练集中可能某个类别没有在测试集中出现,或者测试集中的某个类别没有在训练集中出现。此时如果分别对它们做get_dummies就会出现得到的数据集的列对不起来。
此时需要做的是,保证训练集中的列一定都会出现,对于测试集中没有包含训练集的列添加并值为0,对于测试集中含有训练集中没有的去除,并保证两个数据集的列顺序一致。
df_train_onehot = pd.get_dummies(train_df, columns=train_df.columns)
train_oh_cols = df_train_onehot.columns
df_test_onehot = pd.get_dummies(test_df, columns=test_df.columns)
test_oh_cols = df_test_onehot.columns
miss_cols = set(train_oh_cols) - set(test_oh_cols)
for col in miss_cols:
df_test_onehot[col] = 0
df_test_onehot = df_test_onehot[train_oh_cols]
除了上面这个做法外,还可以利用sklearn的OneHotEncoder来实现。
ohe = OneHotEncoder(sparse=False, handle_unknown='ignore')
然后在ohe.fit_transform(train_df)接着ohe.transform(test_df)即可,不过ohe返回的值都是np.ndarray类型,如果需要则自己命名列的名字。
第一种方法要保存的是训练集的列名,第二种方法则要把fit后的ohe模型保留下来。
Matplotlib
常用作图方法
import matplotlib.pyplot as plt
%matplotlib inline # 在ipynb上显示图片
plt.plot([4, 3, 2, 1]) # 作图代码
plt.show() # 在python运行程序时显示
# 启动ipython作图时可以: ipython --pylab,这样就会自动import matplotlib.pyplot as plt而且不用show()就可以输出图表。
plt.plot([4, 3, 2, 1]) # 使用ipython --pylab后直接显示图图表
直接用数据作图
- 对于numpy的数组数据作图:
fig = plt.figure()
ax1 = fig.add_subplot(2, 2, 1)
ax2 = fig.add_subplot(2, 2, 2)
ax3 = fig.add_subplot(2, 2, 3)
plt.plot([1.5, 3.5, -2, 1.6]) # 默认对最后创建的subplot作图
import numpy as np
from numpy.random import randn
_ = ax1.hist(randn(100), bins=20, color='k', alpha=0.3) # 直方图
ax2.scatter(np.arange(30), np.arange(30) + 3 * randn(30)) # 散列图
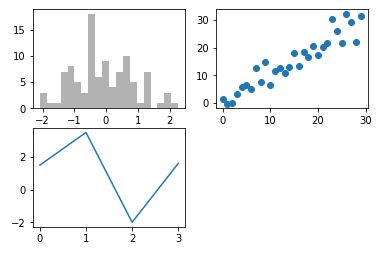
- 强调数据点
plt.plot(randn(30).cumsum(), 'ko--') # 等价于下面语句
plt.plot(randn(30).cumsum(), color='k', linestyle='dashed', marker='o')
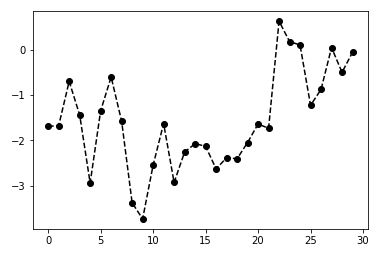
- 图中坐标和标题设置
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(randn(1000).cumsum())
ticks = ax.set_xticks([0, 250, 500, 750, 1000]) # 设置X轴的刻度
labels = ax.set_xticklabels(['one', 'two', 'three', 'four', 'five'], rotation=30, fontsize='small') # 刻度的标签
ax.set_title('My first matplotlib plot') # 图的标题
ax.set_xlabel('Stages') # X轴的名称
- 添加图例
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(randn(100).cumsum(), 'k', label='one') # 创建图例
ax.plot(randn(100).cumsum(), 'g--', label='two')
ax.plot(randn(100).cumsum(), 'r.', label='three')
ax.legend(loc='best') # 把上面设置的图例(legend)创建生效
- 保存图表到文件
plt.savefig('figpath.svg')
plt.savefig('figpath.png', dpi=400, bbox_inches='tight')
Pandas的绘图函数
- Series做柱状图
import pandas as pd
from pandas import Series, DataFrame
fig, axes = plt.subplots(nrows=2, ncols=1) # 获得subplot集合
data = Series(np.random.rand(16), index=list('abcdefghijklmnop'))
data.plot(kind='bar', ax=axes[0], color='k', alpha=0.7) # 竖向柱状图,不设置kind默认是线形图
data.plot(kind='barh', ax=axes[1], color='k', alpha=0.7) # 横向柱状图
- DataFrame做柱状图
df = DataFrame(np.random.rand(6, 4),
index=['one', 'two', 'three', 'four', 'five', 'six'],
columns=pd.Index(['A', 'B', 'C', 'D'], name='Genus'))
print(df)
df.plot(kind='bar')
df数据打印:
Genus A B C D
one 0.017426 0.964258 0.479931 0.636357
two 0.020693 0.979753 0.846889 0.436802
three 0.650068 0.608675 0.964375 0.866141
four 0.523848 0.610598 0.296204 0.879183
five 0.419329 0.023081 0.442044 0.842727
six 0.926948 0.454734 0.436056 0.970364
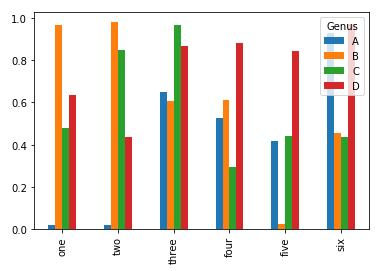
- 直方图和密度图
comp1 = np.random.normal(0, 1, size=200) # N(0, 1)
comp2 = np.random.normal(10, 2, size=200) # N(10, 4)
values = Series(np.concatenate([comp1, comp2])) # 合并为一个Series
values.hist(bins=100, alpha=0.3, color = 'k', normed=True) # 直方图
values.plot(kind='kde', style='k--') # 密度图(kde表示标准混合正态分布)
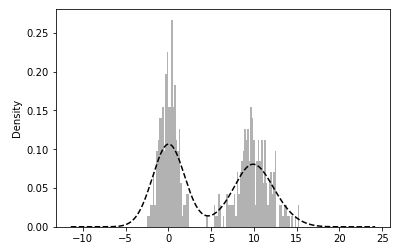
- 散布图
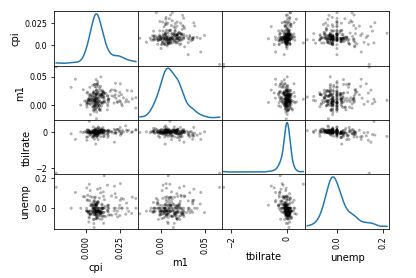
plt.scatter(trans_data['m1'], trans_data['unemp']) # 散布图
plt.title('Changes in log %s vs. log %s' % ('m1', 'unemp'))
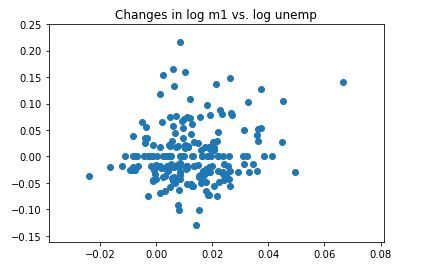
pd.plotting.scatter_matrix(trans_data, diagonal='kde', color='k', alpha=0.3) # 散布图矩阵