字符集和编码简介
在编程中常常可以见到各种字符集和编码,包括ASCII,MBCS,Unicode等字符集。确切的说,其实字符集和编码是两个不同的概念,只是有些地方有重合罢了。对于ASCII,MBCS等字符集,基本上一个字符集方案只采用一种编码方案,而对于Unicode,字符集和编码方案是明确区分的。
1 ASCII
其中ASCII标准本身就规定了字符和字符编码方式,采用单字节编码,总共可以编码128个字符,如空格的编码是32,小写字母a是97,所以ASCII既是字符集又是编码方案。
计算机世界里一开始只有英文,而单字节可以表示256个不同的字符,可以表示所有的英文字符和许多的控制符号。不过ASCII只用到了其中的一半。
2 MBCS
对于英文来说,128个符号编码已经够用了,然而对于其它语言比如中文,显然就不够了。后来每个语言就制定了一套自己的编码,由于单字节能表示的字符太少,而且同时也需要与ASCII编码保持兼容,所以这些编码纷纷使用了多字节来表示字符,如GBxxx、BIGxxx等等,他们的规则是,如果第一个字节是\x80以下,则仍然表示ASCII字符;而如果是\x80以上,则跟下一个字节一起(共两个字节)表示一个字符。因此就出现了多字节字符集MBCS(Multi-Byte Character Set)。如GB2312,GBK,GB18030,BIG5等编码都属于MBCS。由于MBCS大都使用2个字节编码,所以有时候也叫作DBCS(Double-Byte Character Set)。我们在Linux系统中看到含有中文的文件编码常常是CP936,那这个其实就是GBK编码了,这个名字的由来是因为IBM曾经发明了一个Code Page的概念,把这些多字节编码收入其中,GBK编码正好位于936页,所以就简称CP936了。
GB2312是中国规定的汉字编码,也可以说是简体中文的字符集编码。
GBK是GB2312的扩展,除了兼容GB2312外,它还能显示繁体中文,还有日文的假名。
3 Unicode
而后大家觉得各种编码太多不方便,不如所有语言字符都使用一套字符集来表示,于是就出现了Unicode。Unicode/UCS(Unicode Character Set)标准只是一个字符集标准,但是它并没有规定字符的存储和传输方式。Unicode是一种字符集而不是具体的编码,它主要有3种编码方式:最初Unicode标准使用2个字节表示一个字符,编码方案是UTF-16。还有使用4个字节表示一个字符的编码方案UTF-32。而后来使用英文字符的国家觉得不好,原理一个字符存储的现在变成了2个字符,空间增大了一倍,由此UTF-8编码。UTF-8编码中,英文占一个字节,中文占3个字节。
如上面所提到的,Unicode字符集采用UTF-8,UTF-16等方式进行编码存储。那么这样的话,计算机如何知道文件采用哪种方式编码呢?Unicode规范中又定义,在每个文件最前面加入一个表示编码顺序的字符BOM(Byte Order Mark)。比如石锅拌饭中的‘石’的UTF-16编码是77F3,采用UTF-16方式存储使用2个字节,一个字节是77,一个字节是F3.存储的时候如果77在前面,F3在后面,则称为big endian方式。反之,则是Little endian方式。
你可能听说过UTF-8不需要BOM,这种说法是不对的,只是绝大多数编辑器在没有BOM时都是以UTF-8作为默认编码读取。即使是保存时默认使用ANSI(MBCS)的记事本,在读取文件时也是先使用UTF-8测试编码,如果可以成功解码,则使用UTF-8解码。记事本这个别扭的做法造成了一个BUG:如果你新建文本文件并输入"姹塧"然后使用ANSI(MBCS)保存,再打开就会变成"汉a",你不妨试试 :)。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字'中'已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101;
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
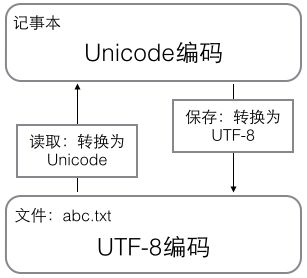
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:

所以你看到很多网页的源码上会有类似的信息,表示该网页正是用的UTF-8编码。
4 ANSI
此外,还有一种不得不提的是ANSI,ANSI在windows系统中极为常见,其实ANSI是Windows code pages,这个模式根据当前的locale选定具体编码,如果系统locale是简体中文则采用GBK编码,繁体中文为BIG5编码,日文则是JIS编码。
此外windows中喜欢把BOM_UTF16_LE编码称作Unicode, 把BOM_UTF8称作UTF-8。也有人说UTF-8不需要BOM来标示,其实是不对的,这是因为编辑器一般默认使用UTF-8来测试字符编码而已,如果可以成功解码,就用UTF-8进行解码。即便最开始采用的是ANSI保存的,打开文件时还是最先使用UTF-8来解码。比如你用windows的记事本程序新建一个文件,写入“姹塧”并用ANSI编码保存,再次打开文件,会发现“姹塧”会变成“汉a”。
1 Python 编码基础
1.1 str和unicode
python中有两种数据模型来支持字符串这种数据类型,str和unicode,它们的基类都是basestring。比如s='中文'就是str类型的字符串,而u=u'中文'就是一个unicode类型的字符串。unicode是由str类型的字符串解码后得到,unicode也可以编码成str类型。即
str --> decode --> unicode
unicode --> encode --> str
关于encode和decode,
s.encode不妨理解为s.encodeTo().
s.decode不妨理解为s.decodeFrom().
encode可以指定error handler,以防脚本在执行的时候因为编码问题而中断。
s.encode('gb18030', 'ignore')
s.encode('gb18030', 'replace')
严格来说,str也许应该叫做字节串,它是unicode经过编码后的字节组成的序列,因为对于UTF-8编码的str类型‘中文’,使用len()函数得到的结果是6,因为UTF-8编码的str类型‘中文’实际是'\xe4\xb8\xad\xe6\x96\x87'。
unicode才是真正意义上的字符串,对字节串str使用正确的字符编码进行解码后获得。而对于unicode类型u'中文'(实际是u'\u4e2d\u6587'),使用len()函数得到结果是2。
1.2 头部编码声明
在python源代码文件中如果有用到非ascii字符,比如中文,那么需要在源码文件头部声明源代码字符编码,格式如下:
#-*- coding: utf-8 -*-
这个格式看起来比较复杂,其实python只检查#,coding,编码等字符串,可以简写成#coding:utf-8。
2 Python2.x常见编码问题
2.1 头部编码声明和文件编码问题
文件头部编码声明决定了python解释器解析源码中的str的编码选择方式,比如头部声明的是utf-8编码,则代码中s='中文',python就会按照utf-8编码格式来解析,通过repr(s)可以看到字符编码是"\xe4\xb8\xad\xe6\x96\x87",如果头部声明的编码是gbk编码,则python会对s采用gbk编码解析,结果是"\xd6\xd0\xce\xc4"。
需要注意的是,文件本身的编码要跟文件头部声明编码一致,不然就会出现问题。文件本身的编码在Linux下面可以在vim下用命令set fenc来查看。如果文件本身编码是gbk,而源码文件头部声明的编码是utf-8,这样如果源码中有中文就会有问题了,因为本身中文str存储是按照gbk编码来的,而python在解析str的时候又以为是utf-8编码,这样就会报SyntaxError: (unicode error) 'utf-8' codec can't decode byte错误。
2.2 默认编码问题
下面看个python默认编码导致的问题:
#-*-coding: utf-8 -*-
import sys
print sys.getdefaultencoding()
u = u"中文"
print 'repr(u) is', repr(u)
s = "中文"
print 'repr(s) is', repr(s)
u2 = s.decode("utf-8")
print 'u2 is', repr(u2)
#s2 = u.decode("utf-8") #编码错误
#u2 = s.encode("utf-8") #编码错误
ascii
repr(u) is u'\u4e2d\u6587'
repr(s) is '\xe4\xb8\xad\xe6\x96\x87'
u2 is u'\u4e2d\u6587'
Traceback (most recent call last):
File "C:/Users/kaicz/Desktop/bianma.py", line 13, in
s2 = u.decode("utf-8")
File "C:\Python27\lib\encodings\utf_8.py", line 16, in decode
return codecs.utf_8_decode(input, errors, True)
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
Traceback (most recent call last):
File "C:/Users/kaicz/Desktop/bianma.py", line 14, in
u2 = s.encode("utf-8")
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
注意实例中注释掉的2行代码,对于unicode最好不要直接调用decode,str最好不要直接调用encode方法。因为如果是直接调用,则相当于u.encode(default_encoding).decode('utf-8'),default_encoding是python的unicode实现中用的默认编码,即sys.getdefaultencoding()得到的编码,如果你没有设置过,那么默认编码就是ascii,如果你的unicode本身超出了ascii编码范围就会报错。同理,如果对str直接调用encode方法,那么默认会先对str进行解码,即s.decode(default_encoding).encode('utf-8'),如果str本身是中文,而default_encoding是ascii的话,解码就会出错,从而导致上面这两行会分别报UnicodeEncodeError: 'ascii' codec can't encode characters in position...错误和UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position...错误。
上面例子中注释掉的两行代码如果执行就会报错,当然,如果本身str或者unicode都在ascii编码范围,就没有问题。比如s='abc'; s.encode('utf-8')就不会有问题,语句执行后会返回一个跟s的id不同的str。
那如果要解决实例1中的问题,有两种方法,其一是明确指定编码,如下所示,
#coding: utf-8
u = u"中文"
print repr(u) # u'\u4e2d\u6587'
s = "中文"
print repr(s) # '\xe4\xb8\xad\xe6\x96\x87'
u2 = s.decode("utf-8")
print repr(u2) # u'\u4e2d\u6587'
s2 = u.encode("utf-8").decode("utf-8") # OK
u2 = s.decode("utf8").encode("utf-8") # OK
第二种方法就是更改python的默认编码为文件编码格式,如下所示(这里要reload sys模块,是因为python初始化后删除了setdefaultencoding方法):
#coding:utf-8
import sys
reload(sys)
sys.setdefaultencoding("utf-8") #更改默认编码为utf-8
u = u"中文"
print repr(u) # u'\u4e2d\u6587'
s = "中文"
print repr(s) # '\xe4\xb8\xad\xe6\x96\x87'
u2 = s.decode("utf-8")
print repr(u2) # u'\u4e2d\u6587'
s2 = u.decode("utf-8")
u2 = s.encode("utf-8")
市面上有些库,例如BeautifulSoup,有时候不正确地使用了ascii来解决中文编码,要修正这种行为在文件头加上,
import sys
reload(sys) #载入setdefaultencoding方法
sys.setdefaultencoding('utf-8')
2.3 读写文件编码
采用python的open()方法打开文件时,read()读取的是str,编码就是文件本身的编码。而调用write()写文件时,如果参数是unicode,则需要用指定编码encode,如果write()参数是unicode而且没有指定编码,则采用python默认编码encode后再写入。
#coding:utf-8
f = open("testfile")
s = f.read()
f.close()
print type(s) #
u = s.decode("utf-8") #testfile是utf-8编码
f = open("testfile", "w")
f.write(u.encode("gbk")) #以gbk编码写入,testfile为gbk编码
f.close()
此外,python codecs模块提供了一个open()方法,可以指定编码打开文件,使用这个方法打开文件读取返回是unicode。写入时,如果write参数是unicode,则使用打开文件时的编码写入,如果是str,则先使用默认编码成unicode后再以打开文件的编码写入(这里需要注意如果str是中文,而默认编码sys.getdefaultencoding()是ascii的话就会报解码错误)。
#coding:gbk
import codecs
f = codecs.open('testfile', encoding='utf-8')
u = f.read()
f.close()
print type(u) #
f = codecs.open('testfile', 'a', encoding='utf-8')
f.write(u) #写入unicode
# 写入gbk编码的str,自动进行解码编码操作
s = '汉'
print repr(s) # '\xba\xba'
# 这里会先将GBK编码的str解码为unicode再编码为UTF-8写入
#f.write(s) #默认编码为ascii时,这会报解码错误。
f.close()
2.4 与编码相关的方法
#coding: gbk
import sys
import locale
def p(f):
print '%s.%s(): %s' %(f.__module__, f.__name__, f())
# 返回当前系统所使用的默认字符编码
p(sys.getdefaultencoding)
# 返回用于转换Unicode文件名至系统文件名所使用的编码
p(sys.getfilesystemencoding)
# 获取默认的区域设置并返回元祖(语言, 编码)
p(locale.getdefaultlocale)
# 返回用户设定的文本数据编码
# 文档提到this function only returns a guess
p(locale.getpreferredencoding)
# \xba\xba是'汉'的GBK编码
# mbcs是不推荐使用的编码,这里仅作测试表明为什么不应该用
print r"'\xba\xba'.decode('mbcs'):", repr('\xba\xba'.decode('mbcs'))
在笔者的Windows上的结果(区域设置为中文(简体, 中国))
sys.getdefaultencoding(): ascii
sys.getfilesystemencoding(): mbcs
locale.getdefaultlocale(): ('zh_CN', 'cp936')
locale.getpreferredencoding(): cp936
'\xba\xba'.decode('mbcs'): u'\u6c49'
3 python开发过程中涉及到的编码
在开发python程序的过程中,会涉及到三个方面的编码:
- Python程序文件的编码;
- Python程序运行时环境(IDE)的编码;
- Python程序读取外部文件、网页的编码;
3.1 Python程序文件的编码
例如,Python2自带的IDE,当创建了一个文件保存的时候提示:
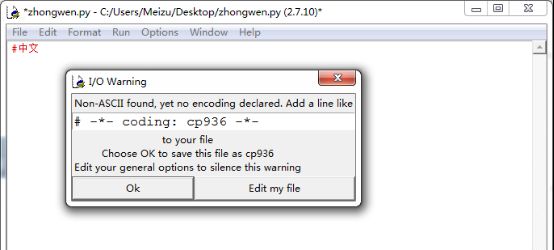
这是因为Python2编辑器默认的编码是ASCII,它是无法识别中文的,所以会弹出这样的提示。这也是我们在大多数情况下写Python2程序的时候习惯在程序的第一行加上:#coding: utf-8。
3.2 Python程序运行时环境(IDE)的编码
执行下面一段程序
#coding: utf-8
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
# 返回百度页面底部备案信息
text = driver.find_element_by_id("cp").text
print(text)
driver.close()
在windows cmd下执行:
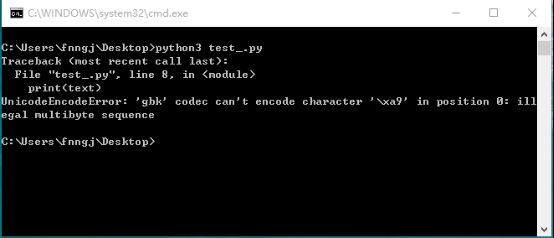
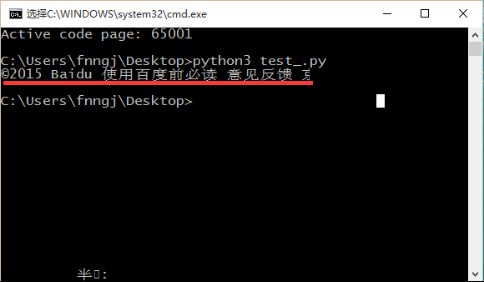
我们要获取的信息是:©2015 Baidu 使用百度前必读 意见反馈 京ICP证030173号
Windows cmd用的是cp936,也就是中文的GB2312,在GBK的字符集里没有"©",这就导致通过GBK解析的时候出现编码问题。
那假设,我还就想在cmd下执行这个python程序了,那么可以去修改cmd的默认编码类型为utf-8,对应的编码为CHCP 65001(utf-8)。在cmd下输入:chcp 65001命令回车。
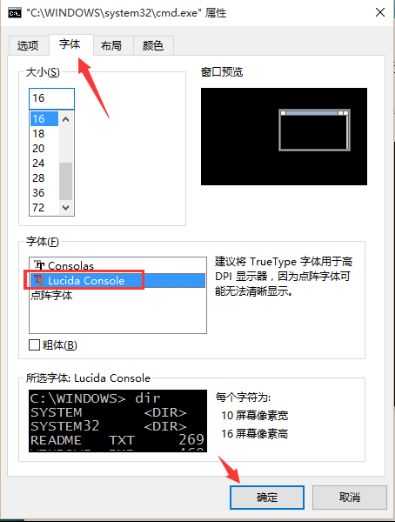
然后,修改cmd的字体为"Lucida Console",再来执行程序就可以被正确输出了。
3.3 Python程序读取外部文件、网页的编码
N/A
3.4 chardet模块
chardet是一个非常优秀的编码识别模块。
通过pip安装
>pip install chardet
>>> from chardet import detect
>>> a = "中文"
>>> detect(a)
{'confidence': 0.682639754276994, 'encoding': 'KOI8-R'}
>>>
3.5 Python的字符串,Python对Unicode的支持
因为Python的诞生比Unicode标准发布的时间还要早,所以最早的Python只支持ASCII编码,普通的字符串'ABC'在Python内部都是ASCII编码的。Python提供了ord()和chr()函数,可以把字母和对应的数字相互转换:
>>> ord('A')
65
>>> chr(65)
'A'
>>>
Python在后来添加了对Unicode的支持,以Unicode表示的字符串用u'...'表示,比如:
>>> print u'中文'
中文
>>> u'中'
u'\u4e2d'
>>> len(u'中')
1
>>>
写u'中'和u'\u4e2d'是一样的,\u后面是十六进制的Unicode吗。因此, u'A'和u'\u0041'也是一样的。
两种字符串如何相互转换?字符串'xxx'虽然是ASCII编码,但也可以看成是UTF-8编码,而u'xxx'则只能是Unicode编码。把u'xxx'转换为UTF-8编码的'xxx'用encode('utf-8')方法:
>>> u'ABC'.encode('utf-8')
'ABC'
>>> u'中文'.encode('utf-8')
'\xe4\xb8\xad\xe6\x96\x87'
>>>
英文字符转换后表示的UTF-8的值和Unicode值相等(但占用的存储空间不同),而中文字符转换后1个Unicode字符将变为3个UTF-8字符,你看到的\xe4就是其中一个字节,因为的值是228,没有对应的字母可以显示,所以以十六进制显示字节的数字。len()函数可以返回字符串的长度:
>>> len(u'ABC')
3
>>> len('ABC')
3
>>> len(u'中文')
2
>>> len('\xe4\xb8\xad\xe6\x96\x87')
6
>>>
反过来,把UTF-8编码表示的字符串'xxx'转换为Unicode字符串u'xxx',用decode('utf-8')方法:
>>> 'abc'.decode('utf-8')
u'abc'
>>> '\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
u'\u4e2d\u6587'
>>> print '\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
中文
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按照UTF-8编码读取文件,我们通常在文件开头写上这两行:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
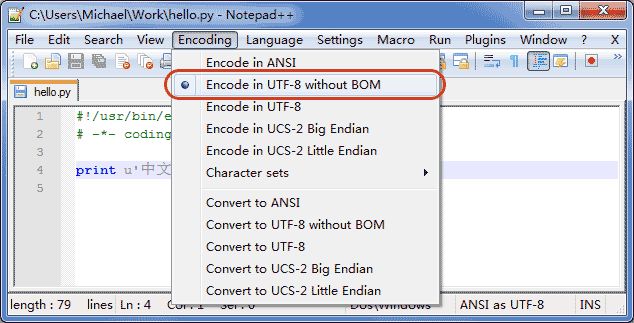
如果你使用Notepad++进行编辑,除了要加上# -- coding: utf-8 --外,中文字符串必须是Unicode字符串:

申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保Notepad++正在使用UTF-8 without BOM编码:
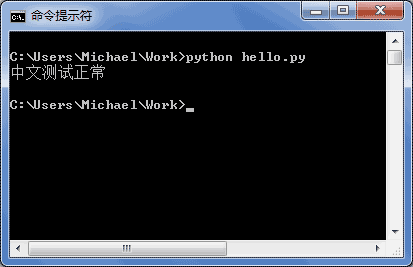
如果.py文件本身使用UTF-8编码,并且也申明了# - - coding: utf-8 --,打开命令提示符测试就可以正常显示中文:
4 实际问题
相信很多用Sublime Text来写Python2的同学都遇到过一下这个问题:在Sublime Text里用Ctrl+B运行代码print u'中文',想要打印出unicode类型的字符串时,会出现以下报错,UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)。
分析:
Python在向控制台(console)print的时候,因为控制台只能看得懂由bytes(字节序列)组成的字符串,而Python中"unicode"对象存储的是code points(码点),因此Python需要将输出中的“unicode”对象用编码转换为储存bytes(字节序列)的"str"对象后,才能进行输出。
而在报错里看到UnicodeEncodeError, 那就说明 Python 在将 unicode 转换为 str 时使用了错误的编码。而为什么是 'ascii' 编码呢?那是因为 Python 2 的默认编码就是 ASCII,可以通过以下命令来查看 Python 的默认编码。
>>> import sys
>>> print sys.getdefaultencoding()
ascii
所以此时在Sublime Text里运行print u'中文',实际上等于是运行了,
print u'中文'.encode('ascii')
ASCII编码无法对unicode的中文进行编码,因此就报错了。
那为什么同样的代码 print u'中文' 在 Mac 的终端里却能正常输出中文,难道是因为终端下的 Python 2 的默认编码不是 ASCII?非也,在终端下运行 sys.getdefaultencoding() 结果一样是 ascii。那同样是 ascii 为什么会有不同的结果?难倒这里 Python 用了另外一个编码来转换?
是的,其实 Python 在 print unicode 时真正涉及到的是另一组编码:stdin/stdout/stderr 的编码,也就是标准输入、标准输出和标准错误输出的编码。可以通过以下命令来查看,这里是在我的终端下运行的结果:
>>> import sys
>>> print sys.stdin.encoding
UTF-8
>>> print sys.stdout.encoding
UTF-8
>>> print sys.stderr.encoding
UTF-8
在正常情况下,Python2在print unicode时用来转换的编码并不是Python的默认编码sys.getdefaultencoding(),而是sys.stdout.encoding所设的编码。
因为在我的终端下 Python 的 sys.stdout.encoding 编码是 UTF-8,所以在终端里运行 print u'中文' 时,实际上是等于运行了:
print u'中文'.encode('UTF-8')
编码正确,运行正常,因此没有报错。
在类 UNIX 系统下,Python 应该是通过环境变量 LC_CTYPE 来判断 stdin/stdout/stderr 的编码的。因此一般只要将 shell 的 LANG 环境变量设置对为 _.UTF-8 后,应该就能在终端里直接 print 出 unicode 类型的字符串了,而不需要在 print 时手动加上 .encode('utf-8') 进行编码了。
但在 Sublime Text 里事情就没那么美好了。在 Sublime Text 里运行查看 stdout 编码的命令,发现:
import sys
print sys.stdout.encoding
-----------------------------
None
[Finished in 0.1s]
结果甚至不是 'ascii' 而是 None。可能是因为 Sublime Text 的 Build System 是用 subprocess.Popen 来运行 Python 的,导致 Python 无法判断出正确的 stdin/stdout/stderr 编码,于是都变成 None 了。
这种情况也发生在输出的目标是管道的情况下:
$ python -c 'import sys; print sys.stdout.encoding' | tee /tmp/foo.txt
None
那么在这种 sys.stdout.encoding 为 None 情况下的 print unicode 怎么办呢?答案就是 Python 只能很无奈地使用 sys.getdefaultencoding() 的默认编码 ascii 来对 unicode 进行转换了。这样就出现了本文开头所说的那个 UnicodeEncodeError 问题。
总结
总结一下Python 2向控制台print输出时的流程:
- Python启动时,当它发现当前的输出是连接到控制台的时候,它会根据一些环境变量,例如环境变量LC_CTYPE,来设法判断出sys.stdin/stdout/stderr.encoding编码值。
- 当Python无法判断出所需的编码时,它会将sys.stdin/stdout/stderr.encoding的值设置为None。
- print时判断字符串是否是unicode类型。
- 如果是的话,并且sys.stdout.encoding不为None时,就使用sys.stdout.encoding编码对unicode编码成str后输出。
- 如果sys.stdout.encoding为None的话,就使用sys.getdefaultencoding()默认编码来对unicode进行转换成str后输出。
if sys.stdout.encoding:
print unicode.encode(sys.stdout.encoding)
else:
print unicode.encode(sys.getdefaultencoding())
解决方法
解决方法1:
先说最不正确的解决方法: 在文件头部加上,
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
这种方法通过dirty hack的方式在Python刚刚启动时更改了Python的默认编码为utf-8。此后:
>>> print sys.getdefaultencoding()
utf-8
但就本文所讨论的问题来说,这个方法并不是真正地直接解决了问题。就如上所说,Python只是在sys.stdout.encoding为None时,才会使用默认编码来转换需要print的unicode字符串。那万一在sys.stdout.encoding存在,但为ascii的情况下呢?这样即使更改了Python的默认编码,同样还是会出现UnicodeEncodeError报错。所以对本问题来说,这个方法治标不治本。
除此之外,很多人都用这个方法来解决Python 2下遇到的其它各种各样的编码问题。但实际上很多大牛都不推荐用这个方法来解决Python 2的编码问题,这里引用下 StackOverflow 相关回答 里的一句话:
the use of sys.setdefaultencoding() has always been discouraged
为什么这个方法不被推荐呢?我们来看下Python文档里对这个function是怎么说的:
This function is only intended to be used by the site module implementation and, where needed, by sitecustomize. Once used by the site module, it is removed from the sys module's namespace.
可以看到这个方法原本就不是面向用户的方法,并没有打算让用户用这个方法来更改Python 2的默认编码。
那为什么不建议我们更改 Python 的默认编码呢?这里引用 Python 核心开发者、Python Unicode 支持的设计者和实现者: Marc-André Lemburg,他在一个邮件列表上的回复:
The only supported default encodings in Python are:
Python 2.x: ASCII
Python 3.x: UTF-8
If you change these, you are on your own and strange things will
start to happen. The default encoding does not only affect
the translation between Python and the outside world, but also
all internal conversions between 8-bit strings and Unicode.
Hacks like what's happening in the pango module (setting the
default encoding to 'utf-8' by reloading the site module in
order to get the sys.setdefaultencoding() API back) are just
downright wrong and will cause serious problems since Unicode
objects cache their default encoded representation.
Please don't enable the use of a locale based default encoding.
If all you want to achieve is getting the encodings of
stdout and stdin correctly setup for pipes, you should
instead change the .encoding attribute of those (only).
--
Marc-Andre Lemburg
eGenix.com
从此可见,Python 2 唯一支持的内部编码只有 ASCII,更改其默认编码为其它编码可能会导致各种各样奇怪的问题。在这里他也说了使用 sys.setdefaultencoding() 的方法是彻彻底底的错误,正确的方法应该是更改 stdout 和 stdin 的编码。
所以这个方法是最不正确的填坑方法,请大家慎用。
解决方法 2:
然后说说应当是姿势最正确的,也是大家都懂的方法:
在 print的时候显式地用正确的编码来对 unicode 类型的字符串进行encode('正确的编码')为 str 后, 再进行输出。而在 print的时候,这个正确的编码一般就是 sys.stdout.encoding的值。但也正如上述所说,这个值并不是一直是可靠的,因此需要根据所使用的平台和控制台环境来判断出这个正确的编码。而在 Mac 下这个正确的编码一般都是 utf-8,因此若不考虑跨环境的话,可以无脑地一直用 encode('utf-8') 和 decode('utf-8') 来进行输入输出转换。
在我的经验中,这个策略也是解决 Python 2 其它 unicode 相关编码问题的最佳方法。在 PyCon 2012 的一个演讲中(关于 Python Unicode 问题很好的一个演讲,这里有演讲稿的中文翻译版),对这个方法有一个很形象的比喻:

因为在程序中进进出出的只有存储 bytes(字节序列)的 str。因此最好的策略是将输入的 bytes 马上解码成 unicode,而在程序内部中均使用 unicode,而当在进行输出的时候,尽早将之编码成 bytes。
也就是要形成一个 Unicode 三明治(如图), bytes 在外,Unicode 在内。在边界的地方尽早进行 decode 和 encode。不要在内部混用 str 和 unicode,尽可能地让程序处理的字符串都为Unicode。
解决方法 3:
虽然解决方法2是最正确的方式,但是有时候在Sublime Text里调试些小脚本,实在是懒得在每个print语句后面写一个尾巴.encode('utf-8')。那么有没有办法能让Sublime Text像在终端里一样直接就能print u'中文'呢?也就是说能不能解决sys.stdin/stdout/stderr.encoding为None的情况呢?
答案肯定是有的,一种方法是用类似更改默认编码的方法一样,用 dirty hack 的方式在 Python 代码中去显式地更改sys.stdin/stdout/stderr.encoding 的值。一样是不推荐,我也没尝试过,在这里就不详说了。
另一种方法则是通过设置 PYTHONIOENCODING 环境变量来强制要求 Python 设置 stdin/stdout/stderr 的编码值为我们想要的,这是一个相对比较干净的解决方法。见文档:
PYTHONIOENCODING
Overrides the encoding used for stdin/stdout/stderr, in the syntax encodingname:errorhandler. The :errorhandler part is optional and has the same meaning as in str.encode().
New in version 2.6.
在 Mac 下对全局 GUI 程序设置环境变量的方法是:使用 launchctl setenv <
在这里顺便科普下,为什么对所有 launchd 启动的未来子进程设置环境变量可以使得对 Mac 下所有 GUI 程序生效。这是因为 launchd 是 OS X 系统启动后运行的第一个非内核进程。我们可以在 activity monitor(活动监视器)里看到,它的 pid 是很帅气的 1。而之后所有的进程都将是它的子进程。另外还可以通过 launchd 在 Mac 下实现类 crontab 的功能。
launchctl setenv命令设置的全局环境变量会在电脑重启后失效,因此就需要通过上面说的 launchd 的开机启动任务的功能来在重启后再设置一遍环境变量,其配置方法可以参考这里。也因为这个原因,我并没有使用这个方法来设置 PYTHONIOENCODING环境变量。
而 Sublime Text 提供了一个设置 Build System 环境变量的方法,这个方法各平台的 Sublime Text 都适用。
设置 Sublime Text 的 Python Build System 环境变量的步骤如下:
- 将 Sublime Text 默认的 Python Build System 的配置文件Python.sublime-build(找到这个文件的最好方法是安装插件 PackageResourceViewer)复制一份到 Sublime Text 的 /Packages/User 文件夹下(在 Mac 和 Sublime Text 3 下这个路径是 ~/Library/Application Support/Sublime Text 3/Packages/User)。
- 打开编辑新复制来的 Python.sublime-build 文件,如下加上一行设置 PYTHONIOENCODING环境变量为 UTF-8 编码的内容,并保存:
{
"shell_cmd": "python -u \"$file\"",
"file_regex": "^[ ]*File \"(...*?)\", line ([0-9]*)",
+ "env": {"PYTHONIOENCODING": "utf8"},
"selector": "source.python"
}
这样一来终于在这么长的文章后能在 Sublime Text 里直接运行 print u'中文',而不用再出现万恶的 UnicodeEncodeError 了。
既然都研究到这了,不妨我们试试把 PYTHONIOENCODING 设置成其它编码看看会出现什么情况,例如设置成简体中文 Windows 的默认编码 cp936:"env": {"PYTHONIOENCODING": "cp936"}
import sys
print sys.stdout.encoding
print u'你好'
----------------------------------
cp936
[Decode error - output not utf-8]
[Finished in 0.1s]
[Decode error - output not utf-8],这就是 Sublime Text 在 Windows 下可能会出现的问题。这是因为 Sublime Text 的 Build System 默认是用utf-8 编码去解读运行的输出的,而我们指定了让 Python 用 cp936 编码来生成 str 字符串进行输出,那么就会出现 Sublime Text 无法识别输出的情况了。同样在对终端 export PYTHONIOENCODING=cp936后,在终端下 print u'你好' 输出的就会是 ���这样的乱码解决办法之一就是同样在 Python.sublime-build 文件里设置 "env": {"PYTHONIOENCODING": "utf8"}来使得输出统一为 utf-8。或者是更改 Sublime Text 的 Build System 所接受的输出编码,将其改为一致的 cp936 编码,同样也是更改 Python.sublime-build 文件,加入一行:
{
"shell_cmd": "python -u \"$file\"",
"file_regex": "^[ ]*File \"(...*?)\", line ([0-9]*)",
+ "encoding": "cp936",
"selector": "source.python"
}
那我们再试试把这两个设置同时都加到 Python.sublime-build 文件里,也就是让 Python 输出 utf8 编码的字符串,而让 Sublime Text 用 cp936 编码来解读,看看会发生什么情况?
{
"shell_cmd": "python -u \"$file\"",
"file_regex": "^[ ]*File \"(...*?)\", line ([0-9]*)",
+ "env": {"PYTHONIOENCODING": "utf8"},
+ "encoding": "cp936",
"selector": "source.python"
}
print u'你好'
----------------------
浣犲ソ
[Finished in 0.1s]
笑,居然不是 [Decode error - output not cp936],而是这么喜感的 “浣犲ソ”!
这是因为 “你好” 的 utf-8 编码刚好和 “浣犲ソ” 的 cp936 编码重合了,都是 '\xe6\xb5\xa3\xe7\x8a\xb2\xe3\x82\xbd',所以使用 cp936 编码去解读的 Sublime Text 就认为这段字符串就是 “浣犲ソ” 而显示了出来。
>>> print repr('浣犲ソ') # cp936 编码
'\xe6\xb5\xa3\xe7\x8a\xb2\xe3\x82\xbd'
>>> print repr(u'你好'.encode('utf-8')) # utf-8 编码
'\xe6\xb5\xa3\xe7\x8a\xb2\xe3\x82\xbd'
5 QA
1.1 请教个问题,文件头部定义的编码#--coding: utf-8 -- 和sys.setdefaultencoding()定义的编码是一回事吗?
#--coding:utf-8--指明'当前文件'的encoding。sys.getdefaultencoding()是python默认把字符转换为unicode的encoding。举个例子,假如你的某个源代码文件里有韩文,并且由于不知什么原因,源代码必须用韩文euc-kr。这时你得在源文件开头声明#coding: euc-kr。
然后这个文件里有这么一段代码:
a = b'hello'
b = u"#*%韩%#@#%文!@#$字$%符"
c = a + b
虚拟机在执行'c = a + b'这句的时候,发现a是一个byte string,b是一个unicode string。它就会用default encoding先去decode一下a,再去和b进行拼接。所以实际执行的是'c = a.decode(DEFAULT_ENCODING) + b'。
其中的DEFAULT_ENCODING在python2下默认是'ascii',可以用reload(sys): sys.setdefaultencoding('utf-8')改成'utf-8',在python3下默认就是'utf-8'。
参考:
- http://www.cnblogs.com/fnng/p/5008884.html
- http://www.liaoxuefeng.com
- https://www.v2ex.com/t/163786