本周花了几天的时间来研究怎么在 breakpad [1, 2] 中加入打印函数参数的功能,以期其产生的 callstack 更具可读性,方便定位崩溃原因。
现代 ELF 中的调试信息基本是以 DWARF 格式为主了,因此这几天的研究也主要将时间花在了理解 DWARF 这货是怎么工作上,感叹要把东西做到极致真是件繁琐而细致的事情。关于 DWARF,网上能找到的相关介绍真心不多,估计也是因为真正需要和它打交道的人真是太少了,在这种情况下最有用最权威的,当然还是官方的文档了,好在我现在也不必把整个 DWARF 的所有细节都给搞明白,且用且看先把需要用到的东西理一理呗。
LEB128编码
LEB128(little endian base 128) 是 DWARF 读写数据使用的一种变长整型编码格式,该编码格式的理论基础与哈夫曼编码相似:相对常用的小整数用较少的位数来表示,大的整数用较长的编码来表示,形式上看 LEB128 分为有符号与无符号两种版本,但在实现上其本质是相同的。
LEB128 以7个 bit 为一个编码单元放在一个 byte 中,从低放到高,该字节的最高位用于表示当前 byte 是否是当前数据的最后一个 byte,0 表示是最后一个字节,1表示还有其它的字节,所以对于小于等于 2 ^ 7 - 1 的整数,只要一个字节就可以表示,大于 2 ^ 7 - 1 又小于等于 2 ^ 14 - 1的整数则需要2个字节,如此类推。
// 原始数据 -> 二进制表示 -> leb128表示
7 -> 00000111 -> 00000111
771 -> 00000011 00000011 - > 00000011 10000011[更正:此处正确的编码应该是:00000110 10000011,多谢网友 @宝刀未老 的指正]因此对于无符号整型, LEB128 的编码过程可以简单用如下伪代码来表示:
void encode_uleb128(value, output)
{
do {
byte = value & 0x7f; // get lower 7 bits of the input.
value >>= 7;
if (value) byte |= 0x80; // need more byte
*output = byte;
output++;
} while (value);
}
至于有符号整数,它的编码原理与实现和无符号本质是一样的,不同之处在于有符号的整形需要一个符号位,因此有符号的 leb128 也需要加入符号位,这个符号位就设在了最后一个字节的第二高位上:
void encode_sleb128(value, output)
{
more = true;
do {
byte = value & 0x7f;
value >>= 7; // 有符号数移位,如果 value 是负数,高位补1.
if (value == 0 && (byte & ox40) == 0 // value 是正数,且当前 byte 的符号位没被占
|| value == -1 && (byte & 0x40) ) // value 是负数,且当前 byte 的符号位已经设置
{
more = false;
}
else
{
byte |= 0x80; // need more byte.
}
*output = byte;
output++;
} while (more);
}可见整个编码过程十分简单明了,解码只是编码的逆过程,这里从略。
DWARF 中调试信息的组织
DWARF 中的调试信息被放在一个叫作 .debug_info 的段中,该段与 DWARF 中其它的段类似,可以看成是一个表格状的结构,表中每一条记录叫作一个 DIE(debugging information entry), 一个 DIE 由一个 tag 及 很多 attribute 组成,其中 tag 用于表示当前的 DIE 的类型,类型指明当前 DIE 用于描述什么东西,如函数,变量,类型等,而 attribute 则是一对对的 key/value 用于描述其它一些信息,在 linux 下我们可以用如下命令来查看 ELF 中的调试信息:
// file: debug_info.c
#include
void func(int arg)
{
int i = 0;
int local = arg + 42;
while (i < local)
{
printf("i = %d\n", i++);
}
}
int main()
{
func(23);
return 0;
}
-bash-3.00$ gcc -o the_executable -g debug_info.c
-bash-3.00$ readelf --debug-dump=info the_executable得到如下信息:
The section .debug_info contains:
Compilation Unit @ 0:
Length: 342
Version: 2
Abbrev Offset: 0
Pointer Size: 8
<0>: Abbrev Number: 1 (DW_TAG_compile_unit)
DW_AT_stmt_list : 0
DW_AT_high_pc : 0x4004fe
DW_AT_low_pc : 0x4004a8
DW_AT_producer : GNU C 3.4.5 20051201 (Red Hat 3.4.5-2)
DW_AT_language : 1 (ANSI C)
DW_AT_name : debug_info.c
DW_AT_comp_dir : /home/miliao/code/snippet
<1><6f>: Abbrev Number: 2 (DW_TAG_base_type)
DW_AT_name : (indirect string, offset: 0x0): long unsigned int
DW_AT_byte_size : 8
DW_AT_encoding : 7 (unsigned)
// skip some the output.
<1>: Abbrev Number: 4 (DW_TAG_subprogram)
DW_AT_sibling : <138>
DW_AT_external : 1
DW_AT_name : func
DW_AT_decl_file : 1
DW_AT_decl_line : 4
DW_AT_prototyped : 1
DW_AT_low_pc : 0x4004a8
DW_AT_high_pc : 0x4004e9
DW_AT_frame_base : 0 (location list)
<2><10d>: Abbrev Number: 5 (DW_TAG_formal_parameter)
DW_AT_name : arg
DW_AT_decl_file : 1
DW_AT_decl_line : 3
DW_AT_type :
DW_AT_location : 2 byte block: 91 6c (DW_OP_fbreg: -20)
// skip some of the output 其中以2个尖括号开始的行表示一个 DIE 的开始,第一行可以看成前面说的 tag,接下来的行表示众多的 attribute。
树型结构的序列化存储
由前面的描述,我们知道 DIE 结构在物理上是以一个数组的形式存放在了一块,但实际在逻辑上它们是树状的,将一棵树序列化存储有很多的方式,DWARF 的实现是这样的:按先序访问这棵树,把节点按访问顺序依次存储,那怎么来表示这些节点间的父子关系呢?
树中每一个节点设置一个 hasChild flag, 该 flag 如为 true,则表示该节点有子节点,且子节点紧跟着当前节点依次存放,直到遇到一个空节点。因此对于每一个节点来说,它要么是前一个节点的子节点,要么是前一个节点的兄弟节点,就看前一个节点的 hasChild 是否为 true。
举个粟子,如下形状的一棵树:
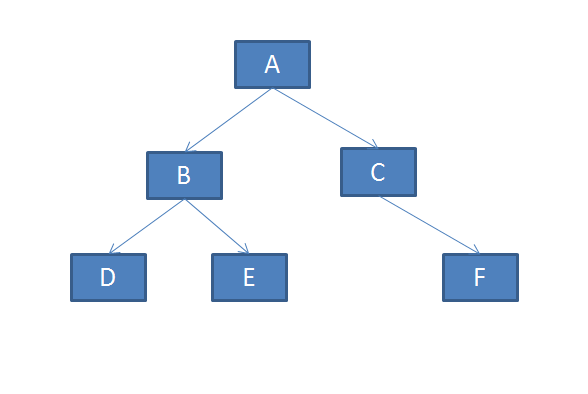
按前面的算法描述,我们可以得到以下序列化的结果:
显然,反序列化就只是一个深度优先,不断回溯的过程,和某些找路径的算法有些相似。
数据压缩
因为调试信息是嵌入在可执行文件当中的,因此调试信息数据量的大小对最后可执行文件的大小有显著的影响,如果你有注意过编译程序时加-g与不加-g,最后得到的程序大小有什么不同,你就明白我的意思。因此对调试信息进行适当压缩是很有意义的,而就目前的结果来看,哪怕最后进行了压缩,调试信息的数据在体积上还是轻松超过了程序的代码与数据,若是不进行压缩。。。
DWARF 为对数据进行压缩采取了两方面的措施,其一前面已经讲了,就是用leb128对数据进行编码及把树序列化从而省去节点指针的开销,另一个措施则是减少 DIE 中 attribute 的数据量,这个怎么做呢? 虽然设计上 DWARF 允许每个 DIE 中可以有不同的 attribute,从而可以极度灵活地来描述各种信息,但在实际的应用中,各个 DIE 的 attribute 数量上是非常少而且非常固定的,比如说描述函数的 DIE 中,它们含有的 attribute 在数量与种类上很多是一样的,只是 value 不同,想像一下如果每一个 DIE 中都保存一份相同的 key,那岂不是太浪费?
所以,DWARF 引进了一个叫作 abbreviation 的东西, 每个 DIE 中包含一个索引,该索引指向一个 abbreviation,该 abbreviation 指明该 DIE 是否有儿子节点,及都有哪些 attribute,而 DIE 中就只存了各个 attribute 的值。
换一句话说,这个做法其实就是把 DIE 中的 key 给抽出来放到abbreviation 中,DIE 则只保存相对应的 value,因此 abbreviation 功能上看就类似个书签索引之类的东西,指导你怎么去解析 DIE 中的数据,举个粟子:
<2><10d>: Abbrev Number: 5 (DW_TAG_formal_parameter)
DW_AT_name : arg
DW_AT_decl_file : 1
DW_AT_decl_line : 3
DW_AT_type :
DW_AT_location : 2 byte block: 91 6c (DW_OP_fbreg: -20) 该 DIE 实际上是存储为如下这样子:
05 'arg\0' 01 03 000000c9 916c 00其中05是该 DIE 对应的abbreviation 的编号,这条 abbreviation 长成如下样子:
5 DW_TAG_formal_parameter [no children]
DW_AT_name DW_FORM_string
DW_AT_decl_file DW_FORM_data1
DW_AT_decl_line DW_FORM_data1
DW_AT_type DW_FORM_ref4
DW_AT_location DW_FORM_block1所以我们知道,DIE 中 'arg\0' 是 DW_AT_name 这个 attribute 的值,类型是 DW_FORM_string,01 对应 DW_AT_decl_file 这个 attribute, 类型是 DW_FORM_data1,如此类推。因为类型可以从 abbreviation 中获取,而每一个类型的数据长度又是确定的,因此 DIE 中的数据也就可以顺利解析了。
DWARF Expression
DWARF 表达式是一个基础于栈的简单程序语言,主要用来描述怎么去计算一个数值或地址。这个语言非常的简单,具体来说,一个表达式由一系列的指令组成,解释表达式的过程就是执行这些指令的过程,而执行指令就是根据该指令及其相应的操作数(如果存在)执行具体的动作,然后把得到的结果放到栈上,等所有指令都执行完了,栈顶的元素就是这个表达式返回的结果。
栈中元素的大小与当前机器的地址长度一样,至于指令,则主要包括如下四类:
Literal Encoding, 字面意思来看,该类指令做的事情很简单:直接把操作数压入栈中,如 DW_OP_lit0 ~ DW_OP_lit31, 这几个指令,执行后会分别往栈上压入 0 ~ 31 这些数字,执行 DW_OP_addr 则把该指令的操作数(一个地址)压到栈上,DW_OP_const1u~DW_OP_const8u 则分别表示往栈上压入 一个 1 ~ 8 个字节的无符号整数,等等。
Register Based Addressing, 这类的指令需要读取寄存器,再把得到的数值与操作数作某些运算后压入栈中,比如:DW_OP_breg0, DW_OP_breg1, ..., DW_OP_breg31,这几个指令都跟着一个 signed LEB128 的操作数,执行这些指令则要求从相应的寄存器(reg 0, reg 1, ..) 取出一个值与该指令的操作数相加,然后把得到的结果压到栈上。
Stack operations, 这类指令表示直接操作当前栈上的元素,如 DW_OP_dup,该指令用来把当前栈顶上的元素再次压入栈中,DW_OP_drop 则表示把当前栈顶的元素从栈中移除,也就 Pop.
Arithmetic And Logical Operations, 这类的指令也是用于操作栈上的元素,但这些操作主要与一些算术逻辑运算相关,如 DW_OP_abs,该指令用来把当前栈顶的元素 Pop 出来,把其当作有符号数,取绝对值后再压回栈中。同理的指令还有诸如 DW_OP_and, DW_OP_div, 等等。
Control flow operations, 这一类指令数量非常少,只有6个,分别是 DW_OP_le, DW_OP_ge, DW_OP_eq, DW_OP_lt, DW_OP_gt, DW_OP_ne,它们的作用是取出当前栈顶的前两元素作相应的比较操作(如,<=, >=),把得到布尔值压回栈中。
空指令, DW_OP_nop,该指令什么事情也不作。
DWARF 表达式在 debug info 中是广泛存在的,主要用来描述参数地址,变量地址等,因此几乎处处都有它的身影,因此读懂这些指令对理解调试信息是至关重要的,好在这个语言并不复杂,甚至解释起来都还算简单,只是考虑到相应指令数量不小,具体写代码实现起来还是得多参考参考 DWARF 的手册,反正到现在我都还没耐心去做完这件事情,根据需要慢慢来吧,摊手。
【引用】
http://www.dwarfstd.org/doc/Dwarf3.pdf
http://www.cs.dartmouth.edu/~sergey/cs108/2010/Debugging%20using%20DWARF.pdf
http://dwarfstd.org/doc/Debugging%20using%20DWARF-2012.pdf