第一次课音乐推荐系统
适合推荐系统的两个库:
查看ipynb文件,使用safiri,先终端运行jupyter notebook。
- surprise
- lightfm
一个项目一般分为两个部分:一个offline的modelling和一个online prediction。(online一般用java或者C++,线上尽量要快,例如网易云会每一天提前算好明天的推荐内容,用户在上线点进去是直接推荐的,不会实时去计算)
这一步的目的,为了将刚才的数据解析成
image.png

image.png
#filter过滤器的用法
def is_odd(n):
return n % 2 == 1
newlist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print(newlist)
#coding: utf-8
#解析成userid itemid rating timestamp行格式
import json
import sys
#配合下面的filter的一个方法
def is_null(s):
return len(s.split(","))>2
def parse_song_info(song_info):
try:
song_id, name, artist, popularity = song_info.split(":::")
return ",".join([song_id, name, artist, popularity])
return ",".join([song_id,"1.0",'1300000'])
except Exception,e:
print e
print song_info
return ""
def parse_playlist_line(in_line):
try:
contents = in_line.strip().split("\t") ##分割内容
name, tags, playlist_id, subscribed_count = contents[0].split("##")
songs_info = map(lambda x:playlist_id+","+parse_song_info(x), contents[1:])
##这一步是map,lambda的结合应用,用来写成一个专辑号,对应多个歌曲信息的形式
songs_info = filter(is_null, songs_info)
return "\n".join(songs_info)
except Exception, e:
print e
return False
##依次读入每一个专辑的内容
def parse_file(in_file, out_file):
out = open(out_file, 'w')
for line in open(in_file):
result = parse_playlist_line(line)
if(result):
out.write(result.encode('utf-8').strip()+"\n")
out.close()
漫步西欧小镇上##小语种,旅行##69413685##474 18682332::Wäg vo dir::Joy Amelie::70.0
音乐系统2
import numpy as np
import pandas as pd
ids = np.random.randint(0, 10, 2)
x = np.array([[0,1],[2,3],[4,5],[6,7],[8,9],[10,11],[12,13],[14,15],[16,17],[18,19]])
print (ids)
print (x[:,1])
print (x[1,:])
print (x[ids,:])
输出:
/Users/yuanxin/PycharmProjects/untitled/venv/bin/python /Users/yuanxin/Documents/大学/Python/code/code/课外拓展学习资料/test1.py
[7 9]
[ 1 3 5 7 9 11 13 15 17 19]
[2 3]
[[14 15]
[18 19]]
Process finished with exit code 0
----------------------------
import numpy as np
import pandas as pd
def read_data_and_process(filname, sep="\t"):
col_names = ["user", "item", "rate", "st"]
df = pd.read_csv(filname, sep=sep, header=None, names=col_names, engine='python')
print(df)
df["user"] -= 1
df["item"] -= 1
for col in ("user", "item"):
df[col] = df[col].astype(np.int32)
df["rate"] = df["rate"].astype(np.float32)
return df
test=read_data_and_process("/Users/yuanxin/Desktop/test.csv", sep="\t")
print (test)
输出:
/Users/yuanxin/PycharmProjects/untitled/venv/bin/python /Users/yuanxin/Documents/大学/Python/code/code/课外拓展学习资料/test1.py
user item rate st
0 123 11 1134 31
1 121 22 3134 23
2 124 15 1242 43
user item rate st
0 122 10 1134.0 31
1 120 21 3134.0 23
2 123 14 1242.0 43
Process finished with exit code 0
第三次课 金融反欺诈
模型整合的三种方式:
- bagging:(集体智慧)
将训练集自动抽样,产生出构建子模型所需要的子训练集,再进行综合打分得到的结果。典型应用是随机森林。 - stacking:(站在巨人的肩膀上,层叠式递进)
有点类似于公司信息汇报,底层提交报告给中层,中层再提交报告,Stacking先用第一层生成决策结果,以多层模型对模式进行识别,在下一层做汇总再提交给下一层进行处理,并最终得出结果。典型应用:神经网络(多层对图像进行挖掘和汇总)。 - boosting:(一万小时定律)
一个弱的分类器,通过不断去学习,直到能够通过一系列的基模型去优成一个强大的模型。典型应用为XGBOOST。
常见的模型融合:
Xgboost:
DMLC提供的大杀器,性能优越,表现稳定,几乎垄断了Kaggle比赛的Top榜单。lightGBM:
微软开源提供,性能略快于Xgboost,可以直接处理字符型的类别变量列,不需要额外变换。
资产证券化:
https://www.zhihu.com/question/20621510
归一化的简单理解:
加速迭代
https://www.zhihu.com/question/20455227
ks曲线
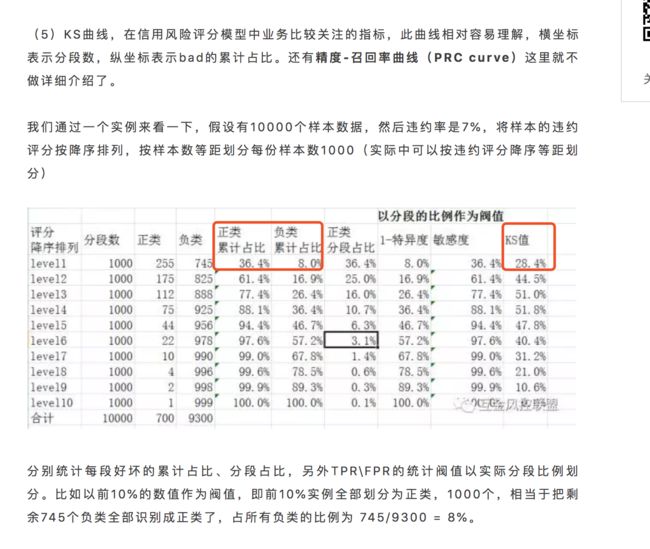
image.png
参考微信文章:信用风险评分卡系列之评分卡(四)