Weigel, K.A., VanRaden, P.M., Norman, H.D., and Grosu, H. 2017. A 100-Year Review: Methods and impact of genetic selection in dairy cattle—From daughter–dam comparisons to deep learning algorithms. J. Dairy Sci. 100(12): 10234–10250. doi:10.3168/JDS.2017-12954.
Translated by Google & revised by Dong
摘要
20世纪初期,育种协会的家畜血统簿已经建立起来,而产奶记录仪方案还处于起步阶段。农民想提高他们牛的生产力,但是群体遗传学、数量遗传学和动物育种的基础还没有奠定。早期的动物育种人员利用受当地环境条件和畜群特定管理措施影响的表现记录,努力确定遗传优良的家系。母-女比较使用了30多年,虽然遗传进展微乎其微,但对表现记录、遗传理论和统计方法的关注在未来几年得到了回报。当时(同群)比较方法允许更准确地考虑环境因素,当这些方法与人工授精和后代测试相结合时,遗传进展开始加快。计算能力的进步促进了混合线性模型的实现,该模型以最佳的方式使用谱系数据和表现数据,并实现了精确的选择决策。牛基因组的测序引发奶牛育种的革命,科学发现和遗传进展的步伐得以加快。基于谱系的模型已经让位给全基因组预测,贝叶斯回归模型和机器学习算法已经在现代动物育种者的工具箱中加入了混合线性模型。未来的发展将包括阐明关键生物途径中的遗传遗传和表观遗传修饰的机制,基因组数据将与来自农场传感器的数据一起使用,以促进现代奶牛场的精确管理。
2017年3月29日收稿。2017年6月11日接收。该综述是Dairy Science杂志委托为庆祝出版百年(1917-2017)特刊的一部分。 通信作者:[email protected]
关键词:遗传选择,奶牛,基因组选择,统计模型
基础
表现记录
谱系记录和表现数据是在前基因组时代开发有效的遗传选择程序的关键基石,如附录表A1所示。谱系记录可以追溯到19世纪末期育种协会创建时,在早期乳业先驱如W.D.Hoard的鼓励下,此后不久开始广泛收集表现数据。 1905年,密歇根州成立了第一个记录牛奶重量和分析乳脂样品的全州协会,到1908年,美国农业部(USDA)动物工业局开始组织地方和国家奶牛检测协会进入全国奶牛群改良协会(DHIA)。1914年这项工作转由联邦推广人员负责,参与牛奶测试的奶牛数迅速增长(VanRaden和米勒,2008年),如图1所示。
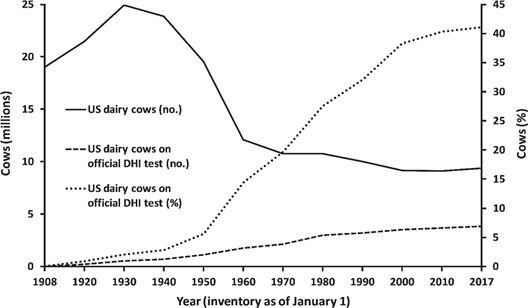
DHIA按月检测是几十年来的标准,但是现在大约三分之二的奶牛场使用省力的上午/或下午测试计划,即在每个月的交替时间采取牛奶样本。未来的战略重点是对最新鲜的母牛或最高产奶牛的母牛进行更频繁的DHIA采样,可能为处于最高效率和最常见健康疾病风险的奶牛提供更有用的数据。如图2所示,通过射频识别(RFID)传感器和在线取样系统对数据进行电子测量,取代了手动输入谱系和表现数据。
在二十世纪二十年代和三十年代,当地的公牛协会很常见,直到20世纪40年代人工授精的广泛采用,当时形成了几十个地区人工授精合作社。因为实际上所有对奶牛感兴趣的性状都是有性别限制的,所以对公牛自身表型的遗传评估是无用的,并且需要根据其后代的表现评估公牛基因优势或劣势的策略。

谱系数据
尽管早在19世纪末期,奶牛育种协会就为每个奶牛和公牛分配了独特的识别号码,但大部分未注册的动物(“等级”)不包括在育种协会的家畜血统簿中,需要另一种鉴别方法。美国农业部于1936年推出了具有独特编号的金属耳标,而后发展成9位数的耳标系列(如35ABC1234),在1955年由动植物健康检验局(APHIS)和美国动物育种者协会(NAAB)引入,今天仍在广泛使用。 1998年推出的美国ID系列具有双字符品种代码,三字符国家代码和12位数字识别号码的特点(例如,HOUSA00035ABC1234或HO840012345678910)。这个系统被设计成在全球唯一的,并且包括登记和分级动物,并且允许将用于每个个体的多个识别码相互参照到一个唯一的号码。
早期的预测育种值的方法
母-女比较
一头母牛的泌乳表现一直被认为是受遗传影响,而早期选择的决定仅仅是基于一头牛的奶或黄油产量。在二十世纪之交出现了比较女儿与其母亲产奶量的想法。为此目的提出了几个指标(Davidson,1925; Graves,1925; Yapp,1925; Goodale,1927; Gowen,1930; Bonnier,1936; Allen,1944),Edwards(1932)比较了它们的相对准确性。在实践中,美国最早已知的母女差异是由1915年左右个别公牛协会计算出来的,根据少数几个种牛和若干后代——这是通过选择改良奶牛的第一次认真的尝试。到1927年,代表超过6000名农民的大约250个合作奶牛协会向美国农业部提供了数据,并且在接下来的40年中,美国农业部计算出了种牛的母-女比较值,并将结果寄给了它们的所有者。 20世纪30年代后期人工授精开始可用,才有了优良种牛在许多牛群中生产数百或数千只后代的机会。在各种管理和环境条件下饲养的大群子代雌牛大大提高了遗传预测的准确性。在此期间,RA Fisher(1918,1930)和JBS Haldane(1932)等巨擘的工作为群体和数量遗传学奠定了基础,使先驱Sewall Wright(1932)和Jay Lush(1931,1933)发展动物育种科学和准确评估种牛所需的统计方法。开发了基于母-女比较的各种指数,包括Wright(1932)和Lush等人(1941年)的指数 。
只要表现数据可用于母女及其女牛,母-女比较促进了用于多个牛群的公牛的遗传评估。如果母女及其女牛被安置在同一个畜群中,这种方法能够考虑牛群特定的管理做法和当地的环境条件。母女及其女牛表现之间发生的管理或环境条件的变化可以忽略。不考虑种牛与其交配个体间的关系,如果这头公牛被用到其原产地,有时会违反这一假设。母牛表现的变化,相对于她的实际遗传价值,是造成预测误差的一个重要来源。随着时间的推移遗传趋势被忽略,但当时在大多畜群中遗传进展是微不足道的。种牛的评估没有回归到平均水平是一个重要的限制,因此仅基于少数母-女对评估的公牛更可能具有极高或极低的遗传预测值。在此期间,制定了泌乳期长度(305 d),挤奶频率(2X)和产犊年龄(成年当量)的记录方法以标准化记录数据。产犊季节也进行了调整,但一般忽略年间环境条件的差异。
选择指数
Hazel和Lush(1942)提出了单个性状EBV(估计育种值)的选择指数,Lush(1944)使用这种方法来推导出母-女比较中各种信息来源的权重。使用多元线性回归预测选择候选者的EBV,其中每个独立变量代表特定类型的亲缘关系,例如母本,父本,母亲半同胞,父本半同胞,或子代的个体或平均表现。回归系数表示指数权重,是遗传关系和由表型记录或平均值贡献的信息量(例如,泌乳次数或后代数量)的函数。来自不同类型亲缘关系的信息量在选择候选者之间经常不同,因此根据遗传力和重复力参数对对平均表现有贡献的亲属或哺乳动物的数量调整指数权重。
同代(同群)比较
同代比较代表了基因评估准确性的巨大飞跃,因为它们能够考虑表型表达所在的特定管理和环境条件(Robertson et al,1956)。同代比较的引入要归功于Robertson和Rendel (1954),亨德森(Henderson)等人(1954)同年正式发表了同群比较模型。然而,Searle(1964)指出这种方法在出版之前已经在新西兰使用过。经受相似的管理和环境条件下的同代或同群的概念与流行病学“cohort”的概念非常相似,在此概念中,基于群体特征(例如,年龄,性别或地理区域)和生活方式特征(例如锻炼方案或烟草使用)的共性将患者分组。设计同代群体的一个重要考虑因素是牛群环境条件的确切定义与足够的同群提供对同代群体效应的准确估计的需求之间的平衡。
后代测试在母-女比较时代变得普遍。然而,同代比较的引入使得人工授精中心能够充分获得将年轻公牛的精液分配给几十个或几百个具有不同地理位置,环境条件和管理实践的畜群的益处。基于遗传力和后代数目,同代比较通过将平均女牛同代偏差(现在称为女儿产量偏差)回归到零而得到增强,因为较少后代的公牛的平均偏差比具有许多后代的多头的方差更大。一些同代比较模型还包括通过父本相互作用调整的群体,以限制单个群体对父本EBV的影响。
康奈尔大学在20世纪50年代中期(亨德森,1956)实施了一个基于同代比较的区域父系评估系统,记录根据每头母牛的泌乳次数和重复性参数进行加权。然而,当结合女牛同代偏差来计算父本的EBV时,没有使用女牛或同代个数的信息。美国农业部于1961年采用了同代比较方法,取代了母-女比较系统。
这个模型允许包含母本表现记录未知的奶牛。Herdyear-season同代群体是以5个月的动态平均值为基础的,同代平均值是根据季节影响而调整的。就像在康奈尔模型中一样,父本的影响也回归到了平均水平,所以如果一个公牛没有大量的女牛就不可能排在前列。被淘汰或用于出售奶制品目的的牛的记录被延长至305天,而更长的记录在305天被截断。
此时还进行了其他调整,其中包括将泌乳期短于305d的因素延长到特定的品种,地区,季节和胎次,记录按泌乳时间加权。牛的产犊日期与父本总结启动之间的时间差确保了来自具有短哺乳期的被淘汰的母牛的记录不偏向对其父本的遗传评估。对于进入遗传评估系统的数据的及时性来说,这是一个明显的限制,至少直到1975年,牛群中的所有奶牛的记录可用。对种牛的遗传价值的估计被公布为他们的女儿相对于典型群体中的同代表现的预测差异(PD)。术语“可重复性”(后来的“可靠性”)用来表示公牛PD的准确性,表明了农民在购买公牛精液时应该具有的信心水平。这种方法直到1973年才被允许包含更多的数据,而且倾向于更小的偏差,并为优良磁性的排名提供了一个指标。
在这段时间内引入了几种竞争性的评估方法。大多数是彼此密切相关的,以及C. R. Henderson(1952,1963)和Cunningham(1965)的加权最小二乘法,以及后续章节中所描述的最佳线性无偏预测(BLUP)模型的简化版本(Thompson ,1976)。 Bar-Anan和Sacks(1974)的累积差异方法基本上与同代比较方法相当,但是对牛的同代的遗传水平进行了调整。 “累积”一词认识到公牛的女牛的表现数据随着时间的推移而积累,从而提高了预测的准确性,这种方法是Dempfle(1976)提出的修正累积差分方法的基础。
1968年美国农业部(USDA)统一了奶牛的遗传评估(Plowman和McDaniel,1968),当时奶牛育种协会停止生产性状的排名。 1972年,美国农业部牛奶改良调查部门更名为美国农业部 - 农业部动物改良项目实验室(AIPL) - 该实验室为今后45年的奶牛遗传评估转化研究设定了全球标准。
改良的同代比较
1974年引入了改进的现代比较(MCC)方法(Dickinson等,1976; Norman等,1976)。在这个模型中,公牛的PD代表了他的系谱价值的加权平均值,以及他的女儿与同代的表现偏差。在以前的方法中,当产奶女牛的数据变得可用时,公牛的系谱信息通常被丢弃。 MCC方法也允许包含父亲和母亲的父亲系谱。考虑到给定群体(即同代的种群)内竞争性种牛的遗传价值,这种方法可以更好地适应一段时间内的遗传趋势(Norman等,1972)。 MCC方法的这些特征越来越重要,因为现代选择工具和先进的生殖技术现在允许一些农民比同龄人更快速地获得遗传进展(McDaniel等,1974)。另外,随着农民“尽其所能地改善他们的畜群”(Norman et al。,1987),积极的配种交配也变得流行起来。 MCC模型包括了来自特定母牛的前5个泌乳记录,其提供了关于动物遗传优势或终生生产力劣势的更准确信息。同代群体在一个群体内的初产和多产奶牛是不同的。如前所述,基于遗传力、女牛个数和每个女牛的泌乳情况回归公牛的评估,但是回归是对它的谱系值,而不是群体平均值。
MCC方法产生的结果与公畜模型中的BLUP几乎相同,但计算要求相当低。遗传基础的重新设定是在这个时候开始的,所以提醒农民提高他们的选育标准。然而,遗传基础的定期重置“原谅”不希望的遗传趋势,可能作为对选择(例如,女性生育力)的相关反应或某些性状(例如身材)的主观价值的偏差的形式出现。 MCC方法被家系育种家和人工授精试验所广泛接受,每头泌乳母牛每年可获得约45千克牛奶的遗传增益。在此期间的另一个创新是将牛奶、脂肪和蛋白质的定价数据纳入其中,因此遗传价值的估计可以表示为相同品种(PD $)的平均父系的财务收益或损失。奶牛指数在中冶时代被广泛使用;这些代表了牛的改良同代偏差和她的父本的PD的加权平均值(以及后来她的母牛指数),权重取决于对每个组成部分贡献的信息量。
线性模型
混合线性模型
亨德森(Henderson,1953)主张使用统计模型来分割遗传和环境变异成分,并预测种牛的遗传价值,这就导致了BLUP方法的发展。尽管其理论上的吸引力,计算限制阻止了BLUP的实现,直到1972年康奈尔大学在公畜模型中实施BLUP;这种模式后来被修改,以包括父本之间的遗传关系。
混合线性模型用矩阵符号表达得最简洁,即
y = Xb + Zu + e,
其中y是一组动物的表型测量向量;b是已知影响表型的连续或分类固定效应向量,例如在传统最小二乘分析中会遇到的产犊或季节性同代群体的年龄;u是一个随机效应向量,比如育种价值;X和Z分别是将y中的表型观察映射到b和u中的固定和随机效应的关联矩阵,e是随机残差效应向量,如临时环境条件或测量误差。对应于随机效应u和e的方差分量σ2u和σ2e可以使用各种方法来估计,如最大似然(Harville,1977)。
公畜和外祖父(Maternal Grandsire)模型
如果混合模型方程中的向量u包含公畜的育种值,并且y包含其女牛的泌乳记录,则上述混合线性模型将被视为一个“公畜”模型。如果我们指定G = N (0,Iu^2),这个模型假设父本是彼此不相关的,所得到的父系EBV相对于σ2e与σu2的大小成比例地向总体均值回归。由于人工授精和胚胎移植的广泛使用,分别导致大的父本半同胞家系和全同胞小家系,因此假设父本彼此不相关是非常不切实际的。当指定G时,对u元素之间的相关性进行建模的概念是直接的,在该应用中,系谱信息被用来推导期望加性遗传关系矩阵,其中G = N (0,Au^2)。得到的A矩阵非常大,是u的元素个数的数量级,并且不能用当时可用的计算资源来求逆。Henderson (1976)开发了一套直接构建A^-1的规则,没有建立A,这样就可以比MCC模型更精确地建模各家系之间的关系,以及公畜和母牛之间的关系或者公畜和外祖父之间的关系(Henderson,1975)。后来,这种方法被扩展,以允许在存在近交的情况下有效地构建A^-1(Tier,1990)。
在1972年在康奈尔大学进行的东北AI公畜比较的公畜模型中,向量b包括公畜的产犊年份和遗传群的固定效应,其中后者基于公牛的出生年和它所在的AI组织。这个想法是,一个给定的AI中心在某一年购买的所有年轻的公牛都具有相似的遗传价值,这有助于假设u中的公畜代表来自相同分布的独立(不相关)样本。只有AI女儿的第一次泌乳记录被使用,尽管如果有额外的记录来自同一群体,这个限制后来被放宽(Ufford等人,1979)。假定了父母本之间随机交配,母牛之间的母本关系被忽略了。
为了解决这样天真的假设,即公牛随机同母牛交配,Quaas等人(1979)提出了一个外祖父模型。这个模型包含了一个额外的随机效应,它代表了外祖父的加性遗传价值,以及一个加性的固定效应,代表了外祖父的遗传基因组。虽然这是解决配对交配积极的一步,但它仍然假定每只公牛的每个配偶都代表该外祖父的所有女儿的随机样本。母本之间的母本关系被忽略,模型没有为外祖父未知的情况增加价值。Norman et al. (1987)对牛奶产量的适宜交配进行了全面的考察,表明平均遗传水平较高的牛群一直使用遗传上优越的公牛。然而,主要关注的是由于内部匹配交配造成的偏差,这在当时并不常见(Norman等,1987),在国家公畜评估系统中很少有AI公牛受到负面影响。
动物模型
公畜或外祖父模型无法充分考虑,在一个给定的群体中,有对母牛而言昂贵精液的公畜和具有最高主观价值的小母牛的非随机交配是众所周知的。此外,希望出售优良种群的农民不再满足于关注公畜和处理奶牛作为副产品的遗传评估系统。 1989年,AIPL的科学家们引入了“动物模型”(Wiggans and VanRaden,1989),该模型利用了母牛与其父母祖先之间所有已知的关系。在这个模型中,动物的加性遗传效应代表了无限多的等位基因,具有非常小的效应 - 所谓的无穷小遗传模型。
一旦实施,利用康奈尔大学的数据算法的迭代和超级计算机,动物模型成为奶牛遗传评估的全球标准。统计方法早在近三十年之前推导出,可以精确地说明交配个体的遗传价值,为同时评估雄性和雌性提供了一个一致的框架。单个动物的育种价值表示为其父本的一半加性遗传价值,其母本的加性遗传价值的一半和孟德尔抽样的总和,孟德尔抽样表示其与其全同胞平均加性遗传价值的偏差,偏差是由于对配子中的allels进行随机取样造成的。所有已知的关系都在A矩阵中考虑,所以一个动物的表现对所有已知的父系和母系亲属的EBV有贡献,其贡献程度取决于关系的接近度。用户通常提供至少4代或5代的谱系数据,并且谱系很少追溯到20世纪70年代以前,当时的系谱记录被计算机化。当谱系数据缺失时,可以使用未知(幻影)亲本组(Westell等,1988)来解释遗漏祖先遗传价值的差异。
在美国农业部的动物模型中,管理组根据平价(第一vs较晚)、注册状态(注册与等级)以及畜群年内的双月时间块来定义。与以前的系统一样,调整用于说明年龄,挤奶频率和泌乳时间,这些因素是特定的品种和地理区域。自1975年以来,美国一直在使用记录;通过减少数据收集和育种值预测之间的时间差(Powell等,1975),遗传进展提高了10%。一旦母牛完成每月2或3次DHI检测,不完整的泌乳记录预计为305天,以及时产生遗传预测并能够对母牛及其父本做出快速选择决策。数据收集等级(DCR)是由美国农业部于1998年引入的;这些数据是基于试验日记录的数量和间隔,相对于标准的每月监督记录每天所有的记录,得到100分。DCR系统允许根据遗传评估的期望值加权记录,他们可以作为指导来偿还提供高质量数据的农民。
由动物模型产生的EBV的精确度可以从混合模型系数矩阵的逆元素中计算出来,但是这在计算上是不可行的,因此使用了近似值(Harris和Johnson,1998)。一个实际的方法是将有助于给定动物遗传预测的女儿当量数相加(VanRaden和Wiggans,1991),其中来自动物后代、自己的表型记录和祖先(注意同胞和表堂亲通过父母进行贡献)的信息量要计数,当计算可靠性值时。
测试日(Test-Day)模型
1993年,康奈尔大学获得了美国“测试日模型”的专利,在该模型中,使用牛群每月测试中的每日牛奶重量来评估动物相对于其牧童的表现,而不是标准化的305 -d泌乳收益。该模型被引入到几个国家(例如加拿大,德国)的常规遗传评估中,其中遗传评估中心获得许可或成功挑战了专利。但是,由于这个专利,美国的常规遗传评估没有实施测试日模型。康奈尔的专利是有争议的,因为许多组织(包括美国农业部)已经提供了几十年的信息,说明在给定的测试日期,一头牛相对于她的牧羊犬的表现,澳大利亚在1984年正式实施了一个测试日遗传评估模型。然而,以前没有人考虑过这个相对广为人知的统计过程的专利(Rothschild and Newman,2002)。测试日模型的一个有趣的特征是它们能够产生泌乳持久性的遗传评估;例如,280天的预期产奶量与产后60天的产奶量的比率。具有较大泌乳持久性的动物可能更有可能在整个泌乳期保持健康,并且可能能够以较便宜的口粮来满足其营养需求,因为它们不经历DMI的极端情况或其较不持久的同时代的负能量平衡。
随机回归模型和协方差函数
通常使用随机回归模型(Henderson,1982;Ali和Schaeffer,1987;Jamrozik等,1997)分析随时间收集的数据,如泌乳牛的试验日乳重或生长小母牛的周期性体重)。 Legendre多项式或样条等函数可以用来描述泌乳期遗传,永久环境和临时环境影响的轨迹。已经提出了许多线性和非线性函数来建模这些效应。例如,Ali和Schaeffer(1987)的模型包括一个随机的牧群日期当代群体效应,以及与母牛哺乳期间的4种功能相对应的固定(总体平均)和随机(加性和永久环境)回归系数记录牛奶重量。在该研究中,假设整个泌乳期的剩余方差是固定的,但一般而言,随机回归模型可以提供在泌乳期间的任何时间点的遗传,永久环境和残差(以及遗传性和可重复性)的估计。选择候选者的EBV可以在泌乳期间的不同时间点计算,并且随机回归模型在适应农场之间牛奶记录频率的变化方面提供了更大的灵活性。
被称为协方差函数(Kirkpatrick et al。,1990)的类似方法可用于分析纵向数据,并解释遗传因素和环境因素随时间的相互关系。这些模型可能在计算上要求很高,并且必须确保适当地建模加性遗传,永久环境和临时环境效应的轨迹。使用具有4或5个参数的复杂函数精确地模拟遗传,永久环境和临时环境效应的轨迹的目标必须与参数估计在应用于每月DHIA记录时具有大标准误差的现实相平衡,每头母牛每泌乳10个数据点。
随机回归模型和协方差函数可以提供关于泌乳期间生物过程的轨迹(例如,乳脂合成,身体组织沉积)的洞察。另外,这些模型可以提供关于选择随时间表达的性状的相关响应的信息,例如选择在泌乳早期的最高泌乳量对泌乳末期的奶组成的影响。随机回归模型或协方差函数的结果也可以用来促进有效的数据收集协议的开发,以最大化在测量表型中投入的每美元的遗传进展。
多性状模型
Harvey和Lush(1952)介绍了第一个选择指数,将牛的生产和构象性状结合起来,继Hazel和Lush(1942)和Hazel(1943)的研究后,他们将动物的基因型定义为线性组合构成总体育种目标的性状的加性遗传价值和经济价值。总基因型或育种目标中性状的数量和定义可能不同于选择指数中性状的数量和定义,特别是如果某些性状测量困难或昂贵(例如饲料效率),或者如果选择依赖于相关表型更容易得到的性状。
估计育种价值的大多数模型可以扩展到纳入多性状(Henderson,1976)。性状之间的遗传相关性表示一个性状的遗传优势倾向于遗传优势或劣势的另一个性状的育种目标的程度。这种相关性可能是由于多效性(一个影响几种性状的基因),或者它们可以通过选择诱导。永久的环境相关性测量动物一生中某些时刻出现的非遗传因素可能影响随后几个月或几年中测量的多重表型的程度,而临时环境(残留)相关性则确认了当前管理实践,环境条件或记录的程度错误会影响多个特征。
奶牛中有利的遗传相关性的实例包括具有长期的奶产量或具有女性生育力的身体状况评分,而不利的遗传相关性的例子包括具有女性生育力的乳产量或具有乳腺炎的产奶量。在人群中存在足够的遗传变异来寻找特定的个体或家族,这些个体或家族优于与负相关的特征,例如高产奶量和良好的女性生育能力。多性状模型通过将正性或负性相关性状的额外表型纳入分析来提高遗传预测的准确性。此外,多性状模型有助于缓解选择偏倚,如果获得历史选择决策的特征的表型数据可用(Pollak et al。,1984)。然而,多性状模型的主要优点是能够评估育种目标中性状之间的相互关系;这个信息对于预测由于对各种性状的EBV选择而发生的期望和不期望的相关响应是关键的。
基因环境互作
一般来说,基因环境互作与温带环境中乳品生产系统中经济重要性状的相互作用很小,至少与植物育种者在将光系或品种与光周期,温度,湿度和土壤条件相匹配时所考虑的相互作用相比较。温带和热带环境之间存在重要的相互作用,因此巴西或泰国等国家的农民往往避免使用普通欧洲品种的纯种牛,而更喜欢适应当地温度湿度条件的品种遗传率为12.5%至37.5% ,蜱传疾病和传染病。
多性状模型经常用来评估GXE的相互作用。例如,可以考虑在具有TMR的密闭畜群中生产牛奶,以牧场为基础的牧群中的奶牛生产作为独立但相关的特征(Weigel等人,1999)。两个生产系统中的相同动物的表型(作为植物育种者将通过在不同的领域中种植相同的品种来做)是不必要的,因为不同系统中的奶牛之间的遗传关系允许将环境之间的表型协同性分为其遗传和环境组分。
反应规范模型在概念上与协方差函数相似,可以描述跨越某个梯度的遗传或环境影响的轨迹,通常是跨越总体管理水平或特定环境条件的梯度(Strandberg et al。,2009)。 Ravagnolo等人使用了一种概念上类似的方法。 (2000)使用当地气象站的温度湿度指数(THI)数据模拟热应激对产奶量和肥力的影响。假设每只动物对热应激的发生具有特定的截距 - 在特定的母牛中观察到牛产量或生育力下降的THI。此外,假定每只动物具有特定的斜率,该斜率表示在该动物的发病点之后,每增加一个THI的产奶量或生育力的下降速率。澳大利亚也进行了类似的分析,以量化个体动物或陛下家系应对气候变化的能力(Garner等,2016)。实施热应激,气候适应或其他反应标准模式的挑战是结果的呈现。对于每个低,中或高THI环境中的每个特征,父母EBV由于信息过载而不明智,但是如果EBV是根据最终用户的当地环境和生产条件定制的,则电子分布的结果可能是简单的。根据地方环境和畜群管理条件定制EBV或选择指数权重可以提供超越G precise精确建模的额外收益。例如,这将减少特定地区或国家的所有农民选择同一个种公的趋势,从而解决控制近亲交配和保持遗传多样性的挑战。
国际比较
Holstein-Friesian系的比较
70年代联合国粮食及农业组织(FAO)进行的大规模牛只育种试验涉及将70个国有农场的30,000只波兰黑白牛配种给国际公牛。在10个国家,约有80,000剂精液来自年轻(未经证实的)荷斯坦奶牛AI公牛,尽管很难确保这些公牛代表该国荷斯坦种群的随机样本。这项研究引起了对乳制品精液的国际贸易,特别是北美荷斯坦公牛的精液出口到欧洲和其他大陆的极大兴趣。
转换方程
早期遗传学比较奶牛的不同来源,国家使用基于回归的“转换方程”。在多个国家,通常是原籍国和一个或多个进口国,挤牛奶的公牛的EBV被用来制定转换方程。回归模型包括截距(平均差)和斜率系数(尺度差),但由于截距和斜率系数的标准误差较大,转换后EBV的准确性一般较差,除非有大量的公牛在两国挤奶女儿。
多性状跨国评估
1995年,国际公牛评估服务(Interbull;瑞典乌普萨拉)引入了多重国家评估(MACE)方法作为转换方程的替代(Schaeffer,1994)。这种线性模型方法允许Interbull中心同时为每个参与国家的每头公牛生成EBV。输入数据是每个国家的女儿产量偏差或EBV(去除祖先影响),其中每个国家都有牛奶记录的女儿,这些数据由每个国家的后代数量加权。目前有二十多个国家参加了Interbull公牛评估,服务包括每个主要奶牛品种的产量,种类,生育力,产犊,寿命,健康和可行性特征。北美和欧洲国家牛奶产量的估计遗传相关性往往很高,在0.85至0.95的范围内,而澳大利亚,新西兰和其他放牧型生产系统的国家则可能在0.75或更低。由于性状定义的差异,构象和健身性状的遗传相关性差异很大。由于缺乏热带或亚热带国家的Interbull分析,热应力或寄生虫抗性等因素的影响在很大程度上是未知的。
成员国已经向Interbull免费提供了他们的全国公牛EBV和谱系文件超过20年,Interbull的工作人员使用MACE方法进行了基于谱系的荟萃分析。对基因组测试的年轻公牛的预测可以用基因组MACE进行计算(Sullivan和VanRaden,2009),但大多数国家公布了基因型交换的预测结果;例如北美财团(包括英国,意大利,瑞士,德国和日本),欧洲基因组学(荷尔斯泰因)或基因组学(布朗瑞士)。交换基因型和家谱比在不同条件下以各种方式测量表型和分化标准更简单,来自50多个国家的育种者已经从北美参考群体获得了基因组预测。
非线性模型
阈值模型由Gianola和Foulley(1983)引入到动物育种领域的阈值模型允许对二元或类别性状(如死产或难产)进行适当建模。正常性假设被违反,但是链接函数(例如probit,logit)将观察到的二元或分类表型与父系EBV在基础“责任”等级上匹配。正态分布曲线下方的区域被模拟,如果父系的EBV()小于第一阈值,则将其分配到类别1,而如果落在第一和第二阈值之间,则将其分配到类别2,等等。阈值模型通常应用于产犊性状,通常与母本效应模型相结合,其使用通常限于父系模型(而不是动物模型)。一般来说,阈值模型导致比通过用常规线性模型拟合二元或分类表型可以获得的EBV更精确。
生存分析
失败时间(生存分析)方法,如Cox或Weibull比例风险模型,在流行病学中被广泛应用,以解释“审查”观察的存在;即,对于开始或结束点(或两者)未知的事件的时间测量。一个例子是生产性寿命(PL)的寿命或长度,其是从第一次产犊到由于疾病,受伤或不育而死亡或扑杀的时间来衡量的。仍然活着的母牛的观察结果是右删失的,因为他们的死亡或淘汰日期是未知的,就像出售给另一个牛群用于奶牛目的的奶牛一样。同样地,日龄开放的表型(从产犊到妊娠时间计算的女性生育力的常见测量值)对于还没有怀孕的母牛以及由于除了不育之外的原因而离开母牛的非怀孕母牛是正确的。 VanRaden和Klaaskate,1993)已经实施了简单的方法,例如假设一个非怀孕母牛的天数或活牛寿命的任意大的值。 Ducrocq等人(1988)将威布尔比例风险模型扩展到包括随机加性遗传效应和关系,从而计算父系EBV的存活率。对右删失记录进行适当的建模,可以包含大量仍然存活的动物,从而获得更及时和准确的结果。以前的研究允许母牛的机会期(如84个月)充分表达生产性生活或终生净利润的表型(如Cassell等,1993),但是到研究完成和手稿发表时,年龄最小奶牛十多年前就出生了。这种方法的另一个优点是能够使用时间敏感的协变量,从而可以更精确地模拟随时间变化的管理和环境因素。
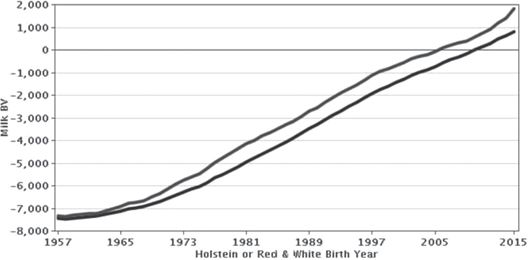
基因组选择标记辅助选择
如图3所示,通过选择在多基因遗传假设下计算的EBV和无限小的模型(即大多数性状受几十或几百个基因影响的概念,每个基因具有非常小的作用)获得了巨大的遗传进展 。尽管如此,用于评估基因组水平上的变异的技术,如RFLP或微卫星标记,使得遗传学家能够追求潜在的功能性突变或具有大的影响的QTL。最初的期望是非常不切实际的,许多研究人员和资助机构认为可以找到导致高产奶量,特殊女性生育能力或有吸引力的物理构象的“基因”。影响精确映射的数量性状的功能性突变的数目并且已经充分表征了遗传模式是可以忽略的,并且单基因选择的效果已经局限于以简单的孟德尔方式遗传的遗传缺陷。
从二十世纪八十年代末到二十一世纪初,开发了用于标记辅助选择的各种方法。关于通过各种方法鉴定的QTL的信息被纳入用于遗传评估的线性模型中,通常作为固定效应。一个代表选择候选者的EBV作为QTL1,QTL2,QTL3,...的估计效应的总和。 。以及一个多基因EBV,它代表分散在整个基因组中的未知基因座,由关系矩阵A调节。由于标记辅助选择的遗传进展收益未能达到预期,Dekkers(2004)综述,特别是当致病突变是未知的,并且选择依赖于群体范围连锁不平衡中的标记,或者当使用全群连锁平衡中的标记进行选择时。通常高估了显着标记的效应(Beavis,1998),并且由于严格的显着性阈值,许多影响较小的QTL被忽略(Lande和Thompson,1990)。
全基因组选择
Nejati-Java- remi et al. (1997) and Meuwissen et al. (2001)的seminal基因组选择论文,加上开发廉价的SNP标记高通量基因分型平台(Matukumalli等,2009),革新了奶牛的繁殖。研究人员开发了数十种方法和算法用于植物和动物的整体基因组选择(de Los Campos et al。,2013),奶牛育种者处于这一运动的前沿(VanRaden,2008;VanRaden等,2009;Wiggans et 2017年)。额外的好处,例如基于基因组发现缺失的祖先,可以进一步提高遗传进展。考虑到从较少数目(n)的基因型个体的表型数据估计大量(p)SNP效应的问题,与全基因组选择相关的早期计算和统计障碍是艰巨的。
BLUP模型
已经使用混合线性模型来估计SNP效应,其中向量u包含假定代表来自正态分布的样本的SNP标记;这提供了可以在基因组上加性的SNP效应的BLUP估计,以获得新的候选基因组的基因组EBV(SNP-BLUP;Meuwissen等,2001)。等效地,可以从SNP基因型构建基因组关系矩阵(G),并且当计算基因组EBV(GBLUP)时,取代BLUP中的基于谱系关系矩阵(A)。最初,SNP-BLUP比GBLUP在计算上需求更高,因为SNP的数量超过了具有表型记录的基因型动物的数目。然而,主要乳品种的培训群体现在由成千上万的具有后代数据的基因型公牛或具有成绩记录的数十万个基因型奶牛组成。 GBLUP中混合模型系数矩阵的维数是基因型动物数量的数量级,其增长速度非常快,通常超过SNP的数量。尽管如此,GBLUP的吸引力还是因为它在几十年来一直使用BLUP的动物育种者的熟悉度和易用性。基因分型动物的快速生长是由于廉价的低密度SNP小组的可用性,其典型特征在于遍布基因组均匀分布的5,000至25,000个SNP。这些低密度基因型可与中等密度(50,000至100,000 SNP)或祖先的高密度(500,000至800,000 SNP)基因型相匹配,并且在低密度面板上遗漏的SNP以95至99%的准确度填充使用基因型归集算法(Habier等,2009;Weigel等,2010)。
一步GBLUP
Legarra等。 (2009)和Misztal等人(2009)解决了计算基因组预测时同时分析基因分型和未分型动物表型的复杂挑战。在此发展之前,直接基因组预测(直接基因组值,DGV)源自基因型动物亚组中SNP基因型和相应表型之间的关联。在随后的步骤中,使用选择指数或加权平均值,将DGV与基于谱系的EBV进行组合。 Legarra等人(2009)提出的单步GBLUP(ssGBLUP)最初的挑战是, 认为缺乏提高其计算效率的技巧,如亨德森(Henderson,1976)从血统书中创建A-1的快速方法。在ssGBLUP中,必须创建矩阵(H)的逆矩阵,其包括用于基因型动物之间的基于基因组的关系的块,非基因型动物之间的基于系谱的关系以及基因型和非基因型动物之间的基于系谱的关系。 Legarra等人(2014)开发了一种构建H-1的高效方法,而ssGBLUP现在可以应用于包含基因分型和未分型动物的相对较大的数据集。
贝叶斯回归模型
使用贝叶斯回归建立另一组基因组预测模型。普通的最小二乘回归方法不能适应解释变量(SNP)数超过数据点数的情况(有表型的动物),但在贝叶斯回归模型中,SNP效应被视为基础分布的随机样本。贝叶斯A(Meuwissen等人,2001)假定SNP效应是从具有厚尾的t分布中采样的,因此大多数SNP具有非常小的效应,但是少数SNP(推测与附近QTL处于连锁不平衡中)可能具有大的影响。被称为贝叶斯B(Meuwissen等人,2001)的类似方法假设SNP效应代表2种分布的混合,其中标记的一部分(π)对表型具有零效应,剩余部分(1-π)具有遵循t分布的效果。可以使用诸如Bayes C(Habier等人,2011)的方法从数据中任意预先确定分数参数。 Erbe等人(2012)随后开发了Bayes R,它具有正态分布的混合,并且适应了零,小,中和大的SNP效应。如果存在中等或较大效应的QTL,贝叶斯回归方法倾向于优于GBLUP,而GBLUP在继承接近无限小模型的情况下表现良好。对未来的担忧是这些模型是否能为选择候选物提供有力的繁殖价值估计,因为只有少数动物被选择用于繁殖先进的繁殖技术。我们的统计模型能够在这个极端的选择强度下正常运行吗?
机器学习方法
机器学习是人工智能的一个分支,其重点是通过将高度灵活的算法应用于观察到的个体(标记的数据)的已知属性(特征)和结果来预测未观察到的个体(未标记的数据)的结果。结果可以是连续的,分类的或二元的。在动物育种中,标记的数据对应于具有基因型和表型的老年动物的参照群体或训练集,而未标记的数据对应于验证群体或仅具有基因型的测试组选择候选者。用于预测的特征是SNP基因型。存在无数的机器学习算法,并且没有一种方法提供了普遍优越的预测 - 不同的应用程序和不同的应用程序的最优方法和参数是不同的。
随着机器学习在其他领域的普及,在畜禽基因组预测方面也取得了一定的进展。机器学习算法因其在大型杂乱数据集中发现模式的能力而广为人知,即使在关于某些潜在解释变量的数据丢失时也是如此。 Long等人(2007)是应用机器学习进行基因组预测的第一批动物育种家之一,他们使用过滤包装法对肉鸡健康特性进行SNP分类。随后的研究Gonz ez-Recio等人(2010)着重于基因组预测荷斯坦种公牛寿命净功的强化算法,而Okut等(2011)使用人工神经网络来预测使用密集分子标记的小鼠的体重指数。姚等人(2013)通过使用随机森林算法来识别影响奶牛残留采食量的潜在加性和上位性QTL,显示了机器学习方法的巨大灵活性。最近,Ehret等人(2015)使用人工神经网络来预测德国的荷斯坦弗里斯兰和弗列克牧人的产奶育种价值。
机器学习,特别是用于实现多层人工神经网络的深度学习算法,对于增强基因组选择和牛群管理具有巨大的潜力。这些算法发现杂乱数据中复杂的模式并比传统的统计方法更有效地预测结果的能力已经在各种领域得到了证明。功能强大的算法在商业和公共领域软件中很容易获得,但是它们本质上是“黑匣子”。最终用户必须了解基本概念,如如何构建独立且适合于预期用途的训练和测试集,如何调整给定模型或算法的参数,以及如何避免过度拟合训练数据和对模型在未来应用中的预测能力做出不切实际的结论。机器学习算法的灵活性可能是有价值的,其中包含从设计实验中收集的生物学知识,以及大量的基因组和表型数据,用于预测选择候选物的育种值。
近交系数
近交系数用于监测一个品种内遗传多样性的损失,并在计算遗传评估时考虑近交衰退的影响。预计未来的近亲繁殖是由美国农业部自1998年以来计算的,通过测量每只公牛与同一品种的雌性样本之间的关系,并且该统计可用于识别与该品种低度相关的“异交”公牛。自2005年以来,美国农业部的基因评估已经根据牛奶记录的女儿与预期的未来配偶之间的差异进行了调整,如果公牛的原配偶不是该品种的随机样本,就可能出现差异。近亲繁殖的基因组测量,例如百分比杂合性或纯合性运行,可以在基因组水平提供更精确的相似性度量。基于基因组的预测来自给定牛和其未来配偶的假设小牛的近亲繁殖可以促进配偶分配决定,基因组数据可以为遗传缺陷和近交抑制的遗传基础提供新的见解(VanRaden等,2011)。使用基因组数据评估品种组成现在是常规的,但缺乏在杂交育种系统中利用基因组数据的有效方法。品种内遗传多样性的丧失仍然是一个问题,品种的管理者应该监测快速遗传进展与多样性保持之间的平衡。没有任何理由让一只荷斯坦公牛来养育超过3000个经过子代测试的儿子,这些儿子统治着每个大陆的人工授精母牛的牛栏,但这在实践中已经发生了。尽管基于最优贡献理论(Meuwissen,1997)提供了限制加性遗传关系随时间变化的速率的方法,但这些方法在实践中并未被广泛使用。实施农场,区域或生产系统特定的EBV和选择指数将有效地解决近亲繁殖和遗传多样性问题,同时也获得与当地适应相关的GXE的益处。
表型预测和管理诊断
动物育种者几乎痴迷于下一代候选子代的预期表现。目前这一代动物的表现往往是事后的事情。他们还倾向于通过数据编辑消除似乎是由非遗传原因引起的例外。例如,双胎产犊的母牛通常从难产和死胎分析中去除,在泌乳早期(第一次DHIA试验之前)死亡的母牛从产奶量评估中去除,在机会期结束前淘汰母牛一个特定的疾病可能会从健康特性分析中被丢弃。然而,农民必须根据当代所有动物的收入和支出来管理自己的业务,包括那些动物育种者认为是例外的动物。用于预测未来表型(例如估计的相对生产能力(ERPA)或最可能的生产能力(MPPA))的方程可以容易地从牛的EBV和相应的永久环境效应估计和其他相关的解释变量计算。预测的未来表型可以包含非加性遗传效应,在基于谱系或BLUP的基因组应用中被忽略,并且这可能变得对特定突变及其作用模式特别有用。数十年来,乳制品档案处理中心的报告向农民提供了MPPA,ERPA和类似指标的价值,但在做出扑杀和管理决策时很少使用这些信息。
现在,基因组测试已经非常普遍,每个月都有成千上万的小牛进行测试,预测未来表型的效用大大提高。管理良好的现代化养殖场的牛群相对于维持群体规模所需的替代品数量,以及与饲养小母牛有关的饲料,劳力和住房成本,直到首次产犊时常常超过动物的市场价值。根据预测的未来表型来剔除劣质的小母牛犊牛,可能是将它们用于牛肉生产,这是一种常见且经济上合理的做法(Weigel等,2012)。可以使用EBV进行剔除决定,但是遗传倾向性是对例如呼吸系统疾病引起的显着肺损伤的小牛未来表型的不完全预测。预测的表型构成了基因组引导的奶牛群管理的基础 - 牛等价于个性化医疗 - 如Weigel等人所述。 (2017)预测早产后荷斯坦奶牛的高酮血症表型。
预测的表型被忽视的应用是使用基因组数据进行评估或牛群管理实践的基准化的机会。基因组测试可以描述给定农场中的小牛,小母牛或牛的遗传倾向,并且该信息可以用于量化农场的住房,热量消减,饲料质量,日粮配方,繁殖程序,健康协议,以及其他管理实践使这些动物充分表达其遗传优势。例如,可以使用用于早期产后健康障碍的基因组预测(Vukasinovic等,2017)来评估牛群的过渡牛处理,或者可以退化泌乳中期奶牛的每日牛奶重量以用于牛产量的基因组预测,以评估牛群的营养计划。
总结
在过去的一百年中,遗传选择程序从谱系记录,表现记录和子代比较,到成年动物模型BLUP,全基因组预测,非线性模型和机器学习算法的演变。 Grosu等人(2014)全面回顾了这些发展及其对全球奶牛改良项目的影响,而这次审查主要集中在美国。过去一个世纪,奶牛育种者的每一次科学进步都建立在他们前辈的肩膀上,与遗传学,统计学和计算机科学同事的合作已经取得了显着的回报。此外,过去一个世纪中,奶牛育种者的每一次科学进步都是为了解决影响奶农的实际问题,解决可能伤害奶农的潜在威胁,或利用可能使奶农受益的机会。这正是立法者设想的赠地大学制度和联邦农业研究机构网络的目标,也是纳税人被要求为这些努力提供资金的期望。未来100年的发现目前是不可想象的,但我们希望在产生能够导致健康的动物,充满活力的农场,满意的消费者和可持续的粮食生产体系的研究成果方面也会取得类似的成就。